















So you think you've already heard about all the enhancements to DB2 for i? Don't be so sure.
The IBM i 7.1 announcement materials have given the most ink to DB2 enhancements for XML integration and column-level encryption enablement—and deservedly so. However, the DB2 for i 7.1 release includes several unheralded features that are sure to make life easier for both programmers and administrators alike.
Some of the features that fall into the unheralded category include embedded SQL client support for stored procedure result sets, Adaptive Query Processing (AQP), a new Merge statement, and IBM i Navigator status monitors for long-running database operations. In this article, you will learn how your applications and systems can benefit from both the major and minor features in the DB2 for i 7.1 release.
XML Integration
XML integration is one of the headline features in the new release. This integration is accomplished via three key enabling technologies: an XML data type, annotated decomposition of XML documents, and a set of SQL XML publishing functions. Read Jon Triebenbach's article to get all the details on these new XML integration capabilities.
Column-Level Encryption Enablement
The other headline DB2 feature in the IBM i 7.1 release is the column-level encryption support. This should be no surprise, given all the media attention on recent IT data breaches. DB2 for i 7.1 enables transparent column-level encryption implementations with a field-level exit routine, known as FieldProc. The FieldProc feature allows developers to register at the field level an ILE program (see code below) that DB2 automatically calls each time a row (record) is written or read.
ALTER TABLE orders ALTER COLUMN cardnum
SET FIELDPROC mylib/ccpgm
This user-supplied program can be written to include logic to encrypt the data for a write operation and automatically decrypt for read operations. This is exciting news to those IBM i customers with legacy RPG and COBOL applications that are looking to encrypt sensitive data at rest without any application changes. All that's required is registering the FieldProc program object (mylib/ccpgm in this example) for those columns containing sensitive data. While the ALTER TABLE statement can be used to register FieldProc programs for DDS-created physical files, it is safer to first convert the physical file to an SQL table definition. This is due to the fact that if CHGPF is used to apply a new DDS definition after the FieldProc registration has been completed, CHGPF will remove the FieldProc without any warning since it's a column attribute that can be defined only with SQL.
Any type of encoding can be performed by a FieldProc program, but it's expected that encryption algorithms such as AES will be the most common form of encoding. Third-party software providers Linoma Software and Patrick Townsend Security Solutions have updated their encryption software to support the DB2 FieldProc interface. This is a good option for those clients that don't want to invest in writing their own Fieldproc programs. Fieldproc implementation requirements are documented in the SQL Programmer's Guide.
Stored Procedure Result Set Integration
Embedded SQL support for stored procedure result set consumption is another integration feature that will have RPG and COBOL developers jumping for joy. The DB2 for i SQL language now supports two new SQL statements, ASSOCIATE LOCATOR and ALLOCATE CURSOR, that allow RPG and COBOL programs to easily consume result sets, as shown below. The code snippet below is actually from an SQL stored procedure since these new statements can also be used by SQL routines (procedures, functions, and triggers).
…
DECLARE sprs1 RESULT_SET_LOCATOR VARYING;
CALL GetProjects(projdept);
ASSOCIATE LOCATOR (sprs1) WITH PROCEDURE GetProjects;
ALLOCATE mycur CURSOR FOR RESULT SET sprs1;
SET totstaff=0;
myloop:
FETCH mycur INTO prname, prstaff;
IF row_not_found=1 THEN
LEAVE fetch_loop;
END IF;
SET totstaff= totstaff + prstaff;
IF prstaff > moststaff THEN
SET bigproj = prname;
SET moststaff= prstaff;
END IF;
END
CLOSE mycur;
…
The first step is declaring a result set locator variable for the ASSOCIATE LOCATOR statement to use. The ASSOCIATE LOCATOR statement is then executed after the call to the stored procedure (GetProjects) returning the result set is complete. Once the locator variable (sprs1) is associated with the result set returned by the GetProjects stored procedure, the final step involves associating a cursor, mycur, with the contents of the stored procedure result set. Effectively, you can think of the ALLOCATE CURSOR statement as performing both the cursor declaration and opening. A SELECT statement is not needed on the ALLOCATE CURSOR statement because that was already done by the stored procedure returning the result set.
With the cursor allocation complete, the invoking program is free to read through the contents of the result set using the FETCH statement, just like an application would do with a traditional SQL cursor. The DESCRIBE CURSOR statement can be used to dynamically determine the number of the columns returned in the result set and their attributes. In this example, that information was communicated to the developer ahead of time.
RPG Long Column Name Integration
RPG developers that access SQL tables with long column names will also enjoy the fact that they can now utilize these long, descriptive column names in their RPG code instead of the short, cryptic 10-character column names. This usability improvement is enabled with the new ALIAS keyword that is shown on the externally described data structure in Figure 1.

Figure 1: The new ALIAS keyword allows the use of long, descriptive column names in RPG. (Click images to enlarge.)
The external declaration statement references an SQL-created table, customers, which contains columns that have been defined with names longer than 10 characters. Specification of the ALIAS keyword results in the long SQL names being used for subfields of the externally described data structure. With the compiler pulling the long names into the data structure, RPG programmers can directly reference these long SQL names in their code instead of the short, cryptic names generated by DB2.
Stored Procedure Improvements
Not only can developers more easily consume result sets from stored procedures, they also have more flexibility when it comes to invoking stored procedures in the IBM i 7.1 release. The SQL CALL statement now supports expressions to be passed as parameters on stored procedure calls. The example CALL statement shown below demonstrates this capability by passing two expressions as parameters. On prior releases, developers had to go through the tedious process of performing the expressions prior to the CALL, storing the expression results in local variables, and then specifying the local variables on the CALL statement. Now, the development process is much more streamlined by allowing the expressions directly on the CALL statement.
CALL myprocedure('ABC', UPPER(company_name), company_discountrate*100 )
SQL Arrays
Sets of data can also be passed as parameters between SQL routines by using the new array support. The new SQL arrays can also be used during the execution of an SQL routine to store a set of values. Before an SQL array can be declared, the CREATE TYPE statement must be used to create an array-based SQL user-defined type such as those shown here.
CREATE TYPE part_ids AS CHAR(3) ARRAY[10];
CREATE TYPE intarray AS INTEGER ARRAY[5];
The first array can contain up to 10 elements, with each element being able to store a three-byte character string. The intarray type not surprisingly supports the storage of integer elements. The SQL array support is limited to single-dimension arrays like those shown above. In addition, data structures are not supported for the array element type; that is limited to a single SQL data type.
The SQL procedure below shows an example of how to use the new array type. In this example, the input parameter is defined to use the part_ids array type. This parameter provides a set of part identifier values that are going to be used to generate a result set containing only those parts matching the inputted part identifiers. The only invoker that can pass an array type to this SQL stored procedure would be a Java application using JDBC or another SQL routine.
CREATE OR REPLACE PROCEDURE List_Parts
(IN inparts part_ids)
DYNAMIC RESULT SETS 1
LANGUAGE SQL
BEGIN
DECLARE cur1 CURSOR WITH RETURN
FOR SELECT t1.id, part_qty, part_type
FROM parts, UNNEST(inparts) AS t1(id) WHERE t1.id = part_num
IF CARDINALITY( inparts )>5 THEN
SIGNAL SQLSTATE '38003'
SET MESSAGE_TEXT='Part limit exceeded';
END IF;
OPEN cur1;
END;
The DECLARE CURSOR statement contains the first reference to the input array, inparts. The UNNEST operator that wrappers the inparts array causes the elements of this array to be unpacked into rows. With the array elements now available as rows of a virtual table, the cursor declaration can join the list of input part identifiers with the parts table to produce the part list result set.
Before the cursor is opened to return the result, the CARDINALITY function is invoked to determine if the input array currently contains more elements than the logic for this routine allows (i.e., 5). The call to the List_Parts procedure produces the result set contents displayed in Figure 2, assuming that the in_parts contained the part identifier values of W12, S55, and M22. The new array support also includes an ARRAY_AGG function that enables the results of a SELECT statement to be assigned to an array variable.
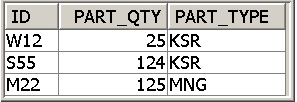
Figure 2: Here's an example result set for List_Parts.
REPLACE Support for SQL
Experienced SQL stored procedure developers may also have noticed additional new syntax in the List_Parts stored procedure example. That new syntax is the OR REPLACE clause, which provides functionality similar to the REPLACE(*YES) parameter value that's available on all of the IBM i create program CL commands.
The OR REPLACE causes DB2 to delete the existing object if the specified SQL object already exists. This eliminates developers having to code an additional DROP statement before each of their CREATE statements. What's even better with the OR REPLACE clause is that DB2 also preserves all of the existing authorities and privileges that had been previously set up for the SQL object. In addition to CREATE PROCEDURE, the OR REPLACE clause can be specified on the following SQL statements:
- CREATE FUNCTION
- CREATE TRIGGER
- CREATE ALIAS
- CREATE SEQUENCE
- CREATE VIEW
- CREATE VARIABLE
SQL Global Variables
The CREATE VARIABLE statement should be another statement that catches your eye since it's another new addition in the 7.1 release. This new statement enables support known as SQL Global Variables. The word "global" is misleading because it implies the value of the SQL Variable can be shared across jobs and database connections; this is not true. Instead, the SQL standards language uses "global" to describe an object that's available for the entire life of a job or connection. Even with SQL global variables limited to the life of a job, this new object still provides lots of flexibility by allowing values to be shared between SQL statements and objects such as triggers and views. For example, many developers using DB2 triggers have often asked if it was possible to pass parameters to triggers. The following code shows how global variables can be used to meet this requirement.
CREATE VARIABLE batch_run CHAR(1) DEFAULT 'N';
CREATE TRIGGER upper_case
BEFORE INSERT ON orders
REFERENCING NEW AS n FOR EACH ROW
WHEN (batch_run='N')
BEGIN
SET n.shipcity = UPPER(n.shipcity);
SET n.shipregion = UPPER(n.shipregion);
SET n.shipcountry = UPPER(n.shipcountry);
END;
…
/* Any batch job that would cause the trigger to be invoked
would need to change the value of the variable to 'Y' */
VALUES 'Y' INTO batch_run ;
…
The trigger is created with a reference to the variable batch on the WHEN clause. Each time the trigger is run, the value of that job's instance of global variable is checked to determine if it's being invoked in a batch environment. An instance of the global variable is automatically created by DB2 within a job the first time a global variable is referenced. In this particular batch environment, the conversion of the shipment location columns to all uppercase strings is not necessary because the orders come in through an electronic process that already does this processing. Thus, the batch_run variable enables the trigger logic to be bypassed when the invoking job has set batch_run to the value of 'Y'.
Without global variables, triggers have to be disabled manually with the CHGPFCST CL command. That CL command was sometimes difficult to run because an exclusive lock is required to disable or enable triggers. Interactive jobs requiring the uppercase transformation in the trigger would not need to assign a value to the batch_run global variable since the default value of the variable is 'N'.
SQL MERGE
The MERGE statement is another new SQL statement that simplifies life for developers. The MERGE statement enables developers to use a single SQL statement to both update and insert rows in a target table and even delete rows if necessary. This capability of the MERGE statement will be quite handy for the population and maintenance of a summary table. This process requires code that conditionally performs an insert or update on the summary table based on values from a detailed transaction file. The following code shows how the MERGE statement can be used in this type of process.
MERGE INTO account_summary AS a
USING (SELECT id, SUM(amount) sum_amount FROM trans GROUP BY id) AS t
ON a.id = t.id
WHEN MATCHED THEN
UPDATE SET a.balance = a.balance + t.sum_amount
WHEN NOT MATCHED THEN
INSERT (id, balance) VALUES (t.id, t.sum_amount)
The account_summary table is being populated with values coming back from the query on the USING clause. In this case, the source query references only a single table. However, the source query could have just as well joined together data from multiple tables. The ON clause identifies the condition that is used to determine when the target summary table will have an existing row updated or a new row inserted. When the account id in the summary table matches the account id being returned by the source query, the MERGE statement performs the UPDATE on the WHEN MATCHED clause to add to the summarized balance for that account. If the account id does not yet exist in the summary table, then the INSERT on the NOT MATCHED clause is used to add that account to the summary table.
Concurrent Access Resolution
As you might be aware, Insert and Update operations in the MERGE statement cause DB2 to hold row-level locks on the rows targeted with write operation. The row-level lock for any Insert or Update statements can be held for a period of time when the application is running with a commitment control (or isolation level) other than *NONE. These row-level locks can block other jobs and processes that are trying to read data in the same table; this blocking can limit the scalability and throughput of applications. With the DB2 for i 7.1 release, applications that are just reading now have the flexibility to have DB2 simply retrieve the last committed version of a locked row from the journal instead of sitting and waiting for the conflicting lock to be released.
This new concurrent access resolution behavior is initiated with the USE CURRENTLY COMMITTED clause shown in the code below. This behavior is beneficial for applications that need to improve performance by reducing lock wait times and do not require the latest version of a row to be returned by the query. Developers now have lots of flexibility for resolving concurrency conflicts when this new support in DB2 for i 7.1 is combined with SKIP LOCKED DATA support that was delivered in the prior release.
SELECT part_id FROM parts
WHERE part_type IN(‘KSR’,’MNG’)
USE CURRENTLY COMMITTED
New Built-In SQL Functions
In each release, IBM adds new built-in SQL functions to provide SQL developers more tools, and the 7.1 release is no different. A suite of new functions (MQSEND, MQREAD, etc.) enables SQL statements to directly integrate and interact with WebSphere MQ messages without the need to switch over to a high-level programming language. Integrating complex binary and character data into your DB2 tables is also easier with the new GET_BLOB_FROM_FILE and GET_CLOB_FROM_FILE functions. In addition, IBM has provided a set of new functions for bit manipulation.
ALTER TABLE Advancements
As SQL usage for DB2 for i database creation continues to increase, more programmers and administrators are relying on the ALTER TABLE statement to maintain those databases. When using the ALTER TABLE statement to add a new column to a table, the new ADD BEFORE clause can be used to control the location of the column within the record layout. On prior releases, new columns were always added to the end of the record. Developers also can now use ALTER TABLE to add the Identity column attribute to existing columns in their databases.
SQL Performance Enhancements
Up to this point, we've focused on those SQL features that make life easier for programmers. In addition to streamlining SQL development, DB2 for i 7.1 contains some significant enhancements to boost the runtime performance of SQL-based applications.
The SQL Query Engine (SQE) has been IBM's key driver of SQL performance over the past several releases, and that continues in the latest release with SQE's new ability to process those SQL statements that reference logical file objects on the FROM clause. This addition will allow more IBM i applications and queries to reap the performance benefits of SQE's advanced data access algorithms.
SQE Self-Learning Query Optimization
Having SQE process more SQL statements is a nice benefit; however, the new self-tuning features of SQL Query Engine will really open the eyes of IBM i customers. Self-learning query optimization is the foundation of this exciting self-tuning technology in 7.1. DB2 for i now supports self-learning query optimization by periodically reviewing the entries of the SQL Plan Cache and analyzing the actual runtime performance of the query access plans generated by the SQE optimizer. In this way, the SQE query optimizer learns from past executions of an SQL statement and can automatically change its optimization methods when there's a large discrepancy between the actual runtime performance and the estimated performance. The result is that future executions of the same SQL statement should run faster.
Adaptive Query Processing (AQP)
While it's great that self-learning optimization allows a statement to run faster in the future, I think you would agree that it would be even be better if the SQE optimizer could speed up the execution of a query or report currently running on the system. That's exactly the capability provided by the Adaptive Query Processing (AQP) feature of the SQL Query Engine. AQP enables the DB2 for i query optimizer to make real-time plan adjustments—such as changing the join order or utilizing a new index—while the SQL request is running. These adjustments are implemented without any disruption to the application. This is sort of like having a car engine tune itself while you're cruising down the road instead of requiring the car to be parked to manually make adjustments.
AQP relies on intelligent monitor agents to coordinate these real-time performance adjustments. Monitor agents are assigned only to queries that are expected to run longer than a few seconds. During the query execution, the monitor agent will periodically compare the runtime execution metrics with the optimizer's estimated costs. Whenever an agent detects a significant deviation between the runtime and estimated costs, the query optimizer is invoked with the new information in hand to re-examine the query plan and look for a more efficient plan. If a more efficient plan is found (e.g., new join order or utilization of a new index), the query is altered to use the new plan. The restart of the query is completely transparent to the application. The application will just reap the performance benefits of AQP detecting a slow-running query and automatically switching to an implementation that reduces the overall execution runtime. This cool technology should give developers extra incentive to convert their non-SQL reports (e.g., OPNQRYF and Query/400) over to SQL-based interfaces.
SQL "Select/Omit" Indexes
SQL performance also benefits from having the right set of indexes in place for the SQE query optimizer to use. DB2 for i 7.1 includes new indexing technology to make the indexing task easier. In the 6.1 release, DB2 provided syntax that allowed you to use SQL to create the equivalent of a Select/Omit logical file (see code below). While this syntax could be used to replace a logical file with an SQL object, the SQE optimizer had no ability to use that index to improve the performance of an SQL statement like the SELECT statement shown below. With the DB2 for i 7.1 release, the SQE optimizer now has the ability to employ SQL indexes created with a WHERE clause as well as existing keyed Select/Omit logical files to improve the performance of SQL requests.
CREATE INDEX cust_ix1 ON customers(cust_state)
WHERE activeCust=’Y’
…
SELECT cust_id, cust_lastname, cust_city FROM customers
WHERE activeCust = 'Y' and cust_state = 'IA'
Encoded Vector Index (EVI) Aggregates
The SQL Encoded Vector Index (EVI) support also was enhanced with the ability to optionally include sum and count aggregate values in the key definition. The INCLUDE clause shown below causes DB2 to augment the region key value with the sales summary and sales count for each region. As data in the underlying sales table changes, the aggregate values will be maintained by DB2 at the same time that index maintenance is performed for the region key field. With one of these new EVIs in place, a developer can speed up the performance of summary queries similar to the SELECT statement in the following code.
CREATE ENCODED VECTOR INDEX idx1 ON sales(region)
INCLUDE ( SUM(saleamt), COUNT(*) )
…
SELECT region, SUM(saleamt) FROM sales GROUP BY region
DB2 Solid-State Drives (SSDs) Enablement
Solid-state drives (SSDs) are another type of object (granted, a hardware object) that IBM i customers can use to boost DB2 for i performance. SSDs can provide performance benefits to DB2 tables and indexes where the data is randomly accessed and the data is read much more often than the data is written. One bank was able to reduce the length of a month-end batch process by 40 percent by moving some DB2 objects to a set of four solid-state drives. Placing DB2 tables and indexes on SSDs is done with a UNIT SSD clause on the SQL CREATE and ALTER statements or the UNIT(*SSD) parameter on the IBM i Create and Change file commands. This new syntax is also available on 5.4 and 6.1 systems by applying the latest Database Group PTF for those releases. To help customers identify those DB2 tables and indexes that are the best fit for SSDs, the DB2 for i 7.1 release now maintains random and sequential data access statistics for each DB2 object.
IBM i Navigator Enhancements
The integrated graphical management interface for DB2 for i databases, IBM i Navigator, has also been simplified with the 7.1 release. For an in-depth discussion, see Robert Bestgen and Tim Rowe's article.
The key addition in this area is the introduction of progress monitors (see Figure 3) for long-running database maintenance operations such as ALTER TABLE and index builds. These monitors enable administrators to more intelligently manage maintenance windows. A progress monitor, for instance, showing hours of work left on a database alter with a rapidly approaching maintenance window deadline enables an administrator to wisely cancel the operation and schedule the database alter operation for a longer maintenance window.
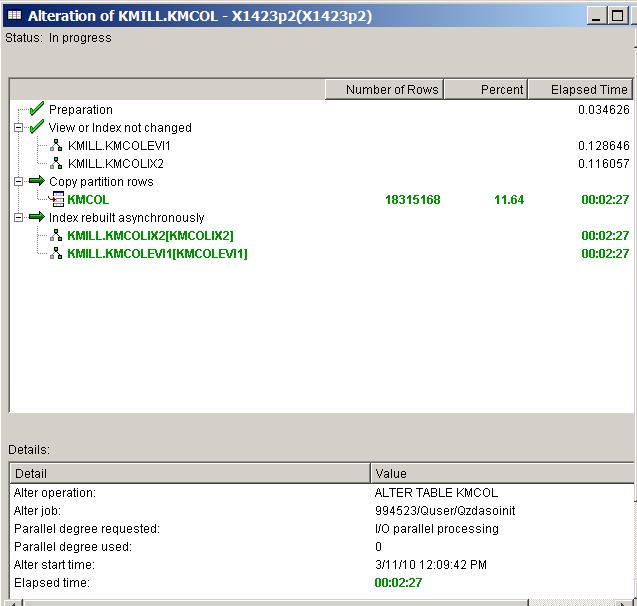
Figure 3: Progress monitors track long-running database maintenance operations.
IBM i Navigator also supports the management of IBM OmniFind text-search indexes, allowing both DB2 indexes and text indexes to be managed from a single interface, as demonstrated in Figure 4. The popular "SQL Details for Job" tool has been enhanced with connecting client information for QSQSRVR jobs and tighter integration with the SQL Performance Monitor tooling. Other improvements to the On Demand Performance Center tooling include Client Register and Error-Only filters for the SQL monitors and variable replacement support in the Show Statement task. In addition, the IBM i Navigator 7.1 client offers improved performance for object folders such as tables and procedures when they contain large numbers of objects.
Figure 4: Manage DB2 indexes and text indexes from a single interface with OmniFind.
Lots to Be Happy About
Hopefully, your eyes have been overwhelmed by the amount of new features and functions available with the DB2 for i 7.1 release…and your heads filled with ideas on how to leverage these enhancements to simplify application development and speed up application performance.



 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online