















The emergence of the IBM i Cloud along with dramatic changes in costs have made downtime-reducing solutions accessible for companies of all sizes.
Until recently, high availability solutions for IBM Power Systems servers running IBM i were reserved mostly for larger enterprises with on-premise or dedicated hosting solutions. Given the emergence of the IBM i Cloud, high availability is now dramatically easier to use and a less expensive alternative for organizations of all sizes. Today, just about anyone running an IBM i environment can now afford the “luxury” of real-time, offsite data protection, as well as rapid and complete data recovery in the cloud.
Fortunately, this shift is occurring just as downtime is causing more of a disruption and expense to businesses than ever before. With technology costs dropping and downtime costs skyrocketing, all organizations have a huge incentive to evaluate high availability technology.
This white paper is a collaborative effort between Connectria Hosting, a pioneer in the development of the IBM i Cloud, and Vision Solutions, the leader in High Availability and Disaster Recovery solutions, including MIMIX, the standard for complete, scalable HA/DR protection for the IBM i. It will provide a review of the core causes and costs of both planned and unplanned downtime and will then provide a detailed discussion of current options for IBM i High Availability and Disaster Recovery in the cloud. Most importantly, as you read, you will learn why true HA and DR protection are now within reach of even the smallest of businesses.
RPO vs. RTO
Before looking more closely at the cost factors of high availability (HA)—and why each has changed so significantly—it is helpful to first understand the concepts of recovery time objectives (RTOs) and recovery point objectives (RPOs).
The graph in Figure 1 shows a variety of common IBM i business continuity technologies in which one axis indicates the time it takes to recover data after a failure/disaster (RTO), and the other axis indicates the completeness of data that is ultimately recovered (RPO).
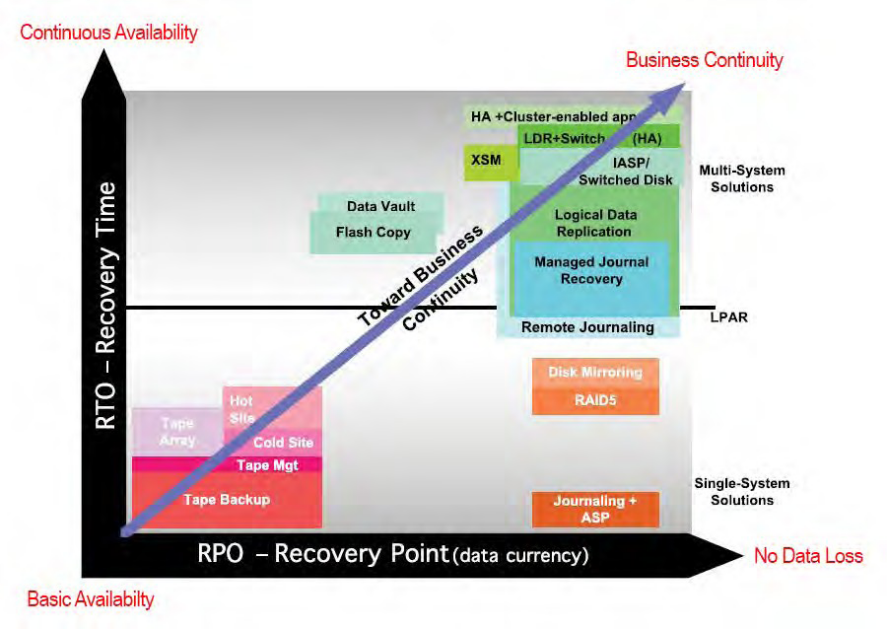
Figure 1: RPO and RTO and the spectrum of IBM i DR solutions/strategies
At the low end of the disaster recovery (DR) spectrum is tape backup (basic availability), and at the high end is high availability (HA)—a process more technically known as logical data replication-plus-switchover (LDR+Switch), which rapidly moves users and processes to a fully mirrored secondary server in order for it to assume all or most of the functions of the production server.
Unfortunately, the perception of companies is that HA technology is so much more expensive than basic disaster recovery protection that it is considered “out of reach” in terms of both cost and complexity. But, in line with most other computing technologies, the range of options between the most basic DR protection and the high-end, fault-tolerant, enterprise-scale solutions has increased, and overall, the cost of all the options has come down, radically in some cases. When introducing the option of an HA solution via a hosted cloud, the price points become decidedly more attractive.
High Availability Cost Factors
High availability is certainly not “cheap” when you consider all of the components that are needed. What has changed is how the cost of each of these factors—each for its own reasons—has dropped. Here are the major components that contribute to the cost of an HA solution.
Hardware—A second IBM Power Systems server is needed, with enough capacity to accommodate the storage of replicated data and potential production demands. For instance, depending on how fully you want to run your applications from your backup environment during planned and unplanned downtime, this server may need to handle the same scale of transaction volumes and devices supported by the production machine. If less than full capability is acceptable during downtime, adjustments can be made. But in the end, a second server, ready to run, is a must.
Communication Bandwidth—If the second Power Systems server is located offsite, which is what is necessary to have true disaster recovery protection, then sufficient communication capacity (bandwidth) is needed to accommodate the amount of data flowing to it from the production machine. This includes the I/O processing capacity of the backup server and the communication lines between sites.
High Availability Software—This component executes, manages, and monitors the replication or mirroring of designated business-critical data to the backup server. It also provides the ability to efficiently move users and processes to the backup server during downtime events. In addition to the initial purchase cost for this software, annual maintenance contracts and installation and training costs must be considered.
High Availability Management—As with any other infrastructure software or system, some level of staff time is required each day to monitor and manage the data replication processes to ensure that the mirrored data is accurate and usable when needed. In part, the amount of time needed for this task depends on the scale of your environment. But the self-managing capabilities of the HA software can have an even bigger impact. Even large-scale HA environments can be easy to manage, with the right software.
So what has changed? Why should you reconsider whether you can justify investment in a true high availability solution? Here are three reasons:
Want to find out more? Download the free white paper, “Three Compelling Drivers for Implementing a High Availability Solution on an IBM i Cloud with MIMIX,” from the MC White Paper Center.



 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online