
















It's time to continue our Big Data discussion. This article introduces the Hadoop framework, one of the most important and most commonly used tools in the Big Data world.
In the previous article, I explained that the most widely accepted definition (if we can call it that) of Big Data is more data than you can manage (store, analyze, and so on) with some (usually high) intrinsic potential value. I also mentioned that these datasets are usually composed of one or more types of data-structured (think RDMS), unstructured (typically text data stored in log files), and a mix of the previous two (like JSON, for instance).
The million-dollar question (well...sometimes it's worth even more than a million dollars) is how to "mine" the value hidden in the Big Data datasets. Just as in many other situations in which IT people found themselves with problems for which they had no tools, the Big Data conundrum (too much data with potential hidden value) led to the creation of quite a few solutions. Let's start with one of the most commonly used: the Hadoop framework.
What Does Hadoop Mean?
No, it's not Highly Available Data with Optimally Organized Processing - though it could be, because this made-up name kind of defines what Hadoop does. Actually, the name comes from the one of its creators' son's stuffed elephant. Strange as it may seem, this open-source software framework for storage and large-scale processing of datasets on clusters of commodity hardware (I'll explain exactly what this means in a minute) was named after Doug Cutting's 2-year-old son, who had just started to talk and called his inseparable stuffed animal "Hadoop," which he pronounced with the stress on the first syllable. This was the yellow elephant I was referring to in the first part of this article.
The Hadoop framework allows us to overcome the "too much data to handle" problem without resorting to expensive supercomputer hardware. Instead, Hadoop uses "commodity hardware" (read: old Pentium or alike PCs - a lot of them) to process the datasets, in distributed and parallel fashion. While a supercomputer typically processes data centrally and uses a high-speed network to feed the central processors and store the results, Hadoop breaks the data into smaller chunks that are distributed in a redundant manner among the components of its cluster, called nodes. These nodes (the old PCs mentioned earlier) running Hadoop-specialized modules (more on Hadoop's architecture later) handle all the processing locally and send back the results to the master node. This approach makes it possible to run applications on systems with thousands of commodity hardware nodes and to handle thousands of terabytes of data. Hadoop's distributed file system facilitates rapid data transfer rates among nodes and allows the system to continue to run smoothly even if a node fails. This approach also lowers the risk of catastrophic system failure and unexpected data loss, even if a significant number of nodes become inoperative. Consequently, Hadoop quickly emerged as one of the main tools for Big Data processing tasks, like scientific analytics, business and sales planning, and processing enormous volumes of sensor data, including from Internet of Things sensors. So, as you can see, Highly Available Data with Optimally Organized Processing kind of describes what Hadoop does. Now let's see how the Hadoop framework is organized, by analyzing its main components.
The Hadoop Ecosystem
Hadoop started out as a side project of Doug Cutting and Mike Cafarella in 2005. It was originally developed to support distribution for the Nutch search engine project. It was fundamentally inspired by two Google engineers' research papers: Google File System (GFS) and MapReduce. Based on these papers, Doug and Mike created the core of Hadoop 1.0: the Hadoop Distributed File System (HDFS) and the MapReduce engine. A lot has happened since then. The huge community that supports the framework created tools that allow Hadoop to connect to the outside world (both figuratively and literally, with the ability to integrate Internet of Things sensor data), taking its functionality way beyond the original one. Figure 1 roughly depicts the current Hadoop ecosystem.
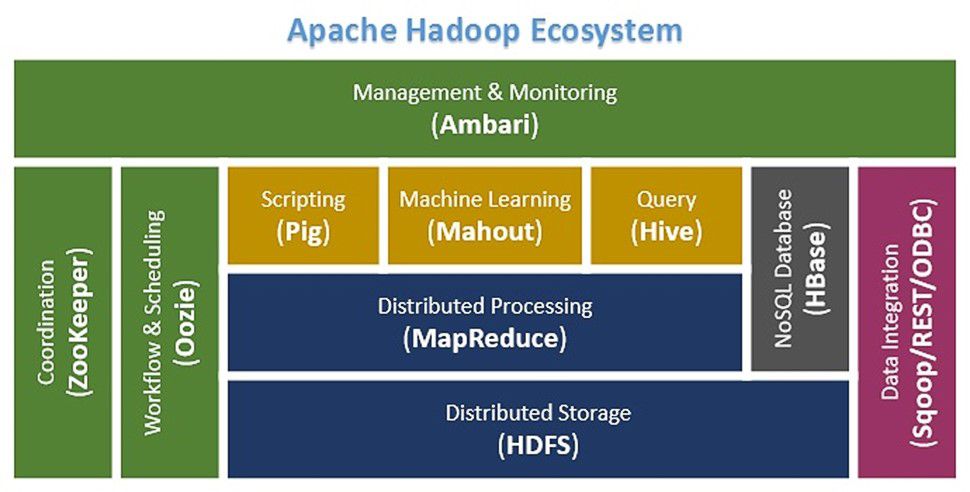
Figure 1: The Hadoop ecosystem
Let's review the components depicted here. Note that the list below doesn't follow a left-to-right or top-to-bottom order of Figure 1. Instead, it explains the components in order of importance and precedence. The list also includes a couple of components that are not shown in the ecosystem figure. Here's the breakdown of Figure 1:
- HDFS is a distributed, scalable, and portable file system written in Java. It was designed to span large clusters of commodity servers scaling up to hundreds of petabytes and thousands of servers. By distributing storage across many servers, the combined storage resource can grow linearly with demand while remaining economical at every amount of storage.
- MapReduce is the original framework for writing massively parallel applications that process large amounts of structured and unstructured data stored in HDFS. It does so by taking advantage of the location of the data and processing it near the place it is stored on each node in the cluster in order to reduce the distance over which it must be transmitted, as opposed to a supercomputer's typical functionality. For a while, MapReduce was the only way to get Hadoop to process data, but being an open-source framework has its advantages. Soon other tools were created to satisfy the growing needs of the Hadoop community.
- YARN (not shown in Figure 1 but of paramount importance to the ecosystem) opened Hadoop to other data-processing engines that can now run alongside existing MapReduce jobs to process data in many different ways at the same time. Introduced with Hadoop 2.0, YARN provides the centralized resource management that enables the user to process multiple workloads simultaneously. YARN is a "data operating system" in the sense that it works as a gateway to other tools to access the HDFS, as shown in Figure 2.

Figure 2: Applications that run natively in Hadoop, thanks to YARN
- Tez was created to address another problem of the MapReduce engine: its performance. Tez is an extensible framework for building high-performance batch and interactive data processing applications, coordinated by YARN in Hadoop. Tez improves the MapReduce paradigm by dramatically improving its speed, while maintaining MapReduce's ability to scale to petabytes of data.
- Pig was created to analyze huge datasets efficiently and easily. It provides a high-level data-flow language, known as Pig Latin, which is optimized, extensible, and easy to use. The most outstanding feature of Pig programs is that their structure is open to considerable parallelization, making it easy for handling large datasets.
- Hive is a data warehouse built on top of Hadoop, and it provides a simple language known as HiveQL, which is similar to SQL for querying, data summarization, and analysis. Hive makes querying faster through indexing, thus allowing business users and data analysts to use their preferred business analytics, reporting, and visualization tools with Hadoop.
- HBase provides random, real-time access to NoSQL data in Hadoop. It was created for hosting very large tables, making it a great choice to store mix-structured or sparse data. Users can query HBase for a particular point in time, making "flashback" queries possible. These characteristics make HBase a great choice for storing semi-structured data like the fitness tracker log data I mentioned in Part 1 of this article or, more commonly, data coming from IoT devices, and then providing that data very quickly to users or applications integrated with HBase.
- Solr (also not shown in Figure 1) is the go-to tool when it comes to searching data in the HDFS. Solr powers the search and navigation features of many of the world's largest Internet sites, enabling powerful full-text search and near real-time indexing. Whether users search for tabular, text, geo-location, or sensor data in Hadoop, they find it quickly with Solr.
- Sqoop is used for importing data from external sources into related Hadoop components like HDFS, HBase, or Hive. It can also be used for exporting data from Hadoop to other, external structured data stores. Sqoop parallelizes data transfer, mitigates excessive loads, allows data imports and efficient data analysis, and copies data quickly.
- Flume is another way to get data into the HDFS. Flume is used to gather and aggregate large amounts of data and send it back to the resting location (HDFS) via YARN. Flume accomplishes this by outlining data flows that consist of three primary structures: channels, sources, and sinks.
- Oozie is a workflow scheduler in which the workflows are expressed as Directed Acyclic Graphs. Oozie runs in a Java servlet container (Tomcat) and makes use of a database to store all the running workflow instances, their states and variables, and the workflow definitions in order to manage Hadoop jobs (MapReduce, Sqoop, Pig, and Hive). The workflows in Oozie are executed based on data and time dependencies.
- Zookeeper is a synchronization and coordination tool that provides simple, fast, reliable, and ordered operational services for a Hadoop cluster. Zookeeper is responsible for synchronization service and distributed configuration service and for providing a naming registry for distributed systems.
- Ambari is a RESTful API that provides easy-to-use web-based user interfaces for Hadoop management. Ambari includes step-by-step wizards for installing Hadoop ecosystem services and is equipped with a central management utility to start, stop, and re-configure those services. Ambari also facilitates monitoring the health status of a Hadoop cluster, as it provides metrics collection and an alert framework.
- Mahout is an important Hadoop component for machine learning (ML), as it provides implementation of various ML algorithms. Machine learning is a whole other world, which I'll explore later. Anyway, this Hadoop component helps with considering user behavior by providing suggestions, categorizing the items to their respective groups, and classifying items based on the categorization, among many other useful things.
There are many other tools built on top of (or integrating with) these, but the ones described here form the core of the ecosystem.
More About Hadoop Next Time
Next time around, I'll explain what a Hadoop Cluster is (I mentioned the term a few times but didn't explain what it means) and how MapReduce gobbles up entire datasets to produce useful insights.

Rafael Victória-Pereira has more than 20 years of IBM i experience as a programmer, analyst, and manager. Over that period, he has been an active voice in the IBM i community, encouraging and helping programmers transition to ILE and free-format RPG. Rafael has written more than 100 technical articles about topics ranging from interfaces (the topic for his first book, Flexible Input, Dazzling Output with IBM i) to modern RPG and SQL in his popular RPG Academy and SQL 101 series on mcpressonline.com and in his books Evolve Your RPG Coding and SQL for IBM i: A Database Modernization Guide. Rafael writes in an easy-to-read, practical style that is highly popular with his audience of IBM technology professionals.
Rafael is the Deputy IT Director - Infrastructures and Services at the Luis Simões Group in Portugal. His areas of expertise include programming in the IBM i native languages (RPG, CL, and DB2 SQL) and in "modern" programming languages, such as Java, C#, and Python, as well as project management and consultancy.
MC Press books written by Rafael Victória-Pereira available now on the MC Press Bookstore.
 |
Evolve Your RPG Coding: Move from OPM to ILE...and Beyond Transition to modern RPG programming with this step-by-step guide through ILE and free-format RPG, SQL, and modernization techniques. List Price $79.95 Now On Sale
|
|
 |
Flexible Input, Dazzling Output with IBM i Uncover easier, more flexible ways to get data into your system, plus some methods for exporting and presenting the vital business data it contains. Now On Sale
|
|
 |
SQL for IBM i: A Database Modernization Guide Learn how to use SQL’s capabilities to modernize and enhance your IBM i database. Now On Sale
|



 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online