















Vendors have so many different types of products to offer. How do you sort through it all?
It's easy to get confused when investigating the requirements and options for implementing a successful business intelligence (BI) initiative. There's an amazing array of product offerings from different vendors, each with its own unique mix of functionality, strengths, and weaknesses. If you are new to BI, it can be difficult to sort through these offerings and identify what is best for your organization.
You will likely hear conflicting messages from different "interested parties." The front-end tool vendor wants you to think that it's easy and that their tool is all you need to be successful with BI. The expert, speaking at COMMON or one of the other conferences, talks about best practices that include a data warehouse, data marts, metadata, and extract, transform, and load (ETL). And a few years ago, even IBM was confusing you by telling iSeries shops to implement BI on a pSeries box, even though you probably had no expertise in that platform. This was purely because some IBM executive had drawn up a matrix to specify that each workload belonged on an i, a p, or an x box. And BI just happened to end up on p. Thankfully, Big Blue eventually came to its senses on that idea and recognized that trying to foist a UNIX box onto die-hard i shops usually doesn't fly.
Just a few days ago, I heard that a "front-end" tool vendor was trying to convince one of my customers that they should throw away their data warehouse, and just implement this vendor's front-end (query/reporting) tool directly against their operational data. Because my customer has reaped the benefits of their data warehouse over the past several years and understands its value, they were not hoodwinked by this sales pitch and will keep their data warehouse.
With these confusing, sometimes contradictory messages, it's no wonder that the principles and best practices of a good BI implementation are not always well-understood. In the space of this article, we cannot explore all of the factors that you need to consider, but we'll try to cover the more important issues.
Of the many BI products available, which ones do you need, and why? The answer is, as usual "it depends." The correct approach (as with any project) is to determine what you are trying to achieve from a business perspective. This will be different from organization to organization, and for many, there will be several different distinct requirements. We can categorize the front-end BI tools into three broad categories, as shown in Figure 1.
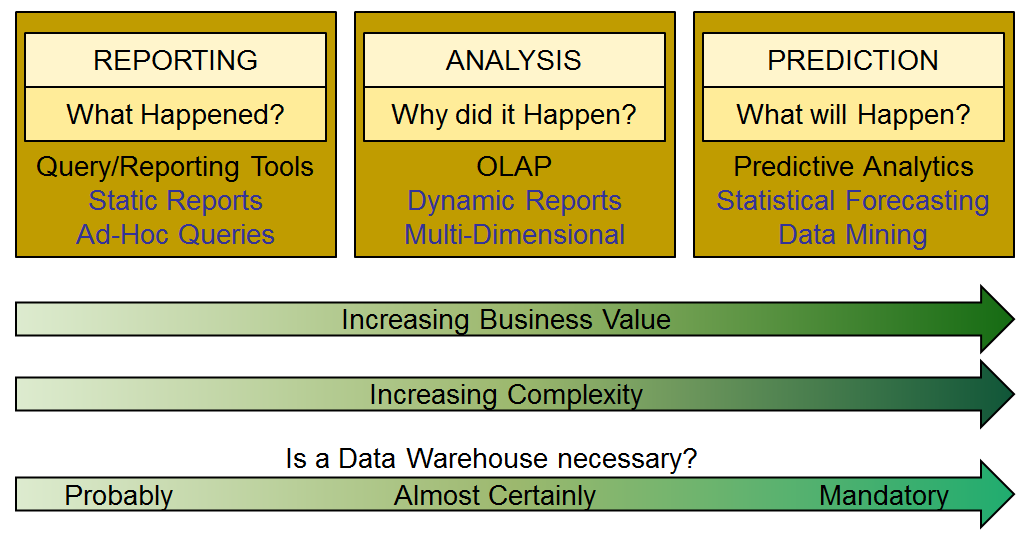
Figure 1: Front-end BI tools fall into three categories: reporting, analysis, and prediction. (Click images to enlarge.)
The most basic BI implementations simply focus on reporting what happened (last week, last month, etc). These are often static reports, produced on a scheduled basis. Many organizations successfully start their BI efforts at this level. Success, however, has its price: Not long after your business users get access to these useful reports, they'll start asking more difficult questions and want to analyze the data to understand why something happened. These questions are best answered by online analytical processing (OLAP) tools. Typically, these use a multi-dimensional data structure to provide fast drill down into the detail. There is a much higher business value here: Analysts can explore the data to understand trends and then use that information to make informed business decisions.
More advanced still are the "predictive analytics" applications that can use your historical data to predict what will happen in the future. Data-mining applications can tell you the answers to questions you never thought to ask, unlocking more of the value hidden in your data. Unfortunately, very few organizations achieve this level of sophistication. It's substantially more difficult to successfully implement these applications, partly because you probably won't have the skills in-house to use the tools (consultants are usually required), but also because the underlying data required to support them is more difficult to prepare and deliver. As you get further to the right (in the above figure), the need for clean, integrated, and well-organized data grows exponentially.
The only way to provide this data is by implementing a data warehouse and associated data marts. To understand why this is, let's explore some of the common issues that you'll encounter. Most of these are found in almost every organization, regardless of size.
Data Complexity
The data contained in an operational database can be quite difficult to interpret. There are a number of reasons for this:
- Data (information) in an operational database is designed to be accessed by applications, by the software that it was created to support. Therefore, the design of the database is based on principles and best practices that support this. Unfortunately, these design principles are often quite unfriendly when we try to access the data for business intelligence purposes. The principle of third normal form (avoid redundancy of data) results in many tables in the database. Even the simplest reports could need to join a dozen tables to bring in all the required data.
- There is usually no user manual describing the structure and meaning of the database. Again, this is because the database was not designed for human access.
- In all but the very best database designs, you will encounter all sorts of inconsistencies. This is usually because the application has grown over time and has been developed by many different programmers. The same piece of data may have a quite different name and description in different tables. Redundant columns may have been re-used for a different purpose, and therefore have totally incorrect names and descriptions. Meaningful information may be embedded inside another column. And so on.
Disparate Data
Understanding and using data coming from just one application may be difficult enough, but that pales in comparison to the task of joining data across applications. If those applications reside on different systems and use different database types, it gets even harder. What are the odds that similar, related pieces of information are stored in the same format?
Similarly, you may have the same piece of data in multiple databases, with different identifiers. In one example I came across recently, a manufacturing company found it had 90 different "parts" files, most using different parts numbers, such that the same part in different files could not easily be cross-referenced. This is an extreme example of a very common scenario.
Data Quality
This is arguably one of the biggest issues; however, data quality is given little attention in many shops. While there are many reasons for this, probably the one major underlying factor is the belief that "I don't have any data quality issues." While it is possible this is true, based on the experiences of every business intelligence consultant and data analyst, it is highly unlikely. Operational applications (e.g., ERP systems) generate enormous amounts of data in many tables and columns. When bugs (associated with data issues) are encountered in the daily use of the application, the problem gets attention and is fixed. However, there are many instances when data is generated by a process and not touched again by the application; or if touched, the error is such that it does not result in a recognizable problem. These data errors do not always get discovered and corrected.
So when you hear someone in your organization say, "We don't have any data problems," be very skeptical. You have a problem if you are using that suspect data for BI reporting. If you have done nothing to validate critical pieces of data (information), how confident can you be in the reports you are delivering or consuming?
Performance
When reporting directly from operational data, we must use whatever source of data is available to us containing the information we need. For transaction data, that usually means the most detailed level stored in the database (e.g., invoice line-item level). If you need a summary report by Division and Brand, and then another one by Customer Group and Region, your only option is to process all line items (matching the selection criteria) and perform the aggregation. And then do it again for the second report. This often leads to significant performance problems. If these reports are run on an ad-hoc basis during the day, they not only take a while to run, but also can affect everyone else using the system.
What to Do?
When you point a front-end reporting/OLAP tool toward operational data with any of the above issues, you'll need to attempt to solve these problems within the reporting tool itself. The problem is that the vast majority of these front-end tools are not designed to solve these data issues. Conversely, a well-designed data warehouse and associated ETL processes can address all of the above issues (and many more).
The following chart shows a typical data warehouse implementation.
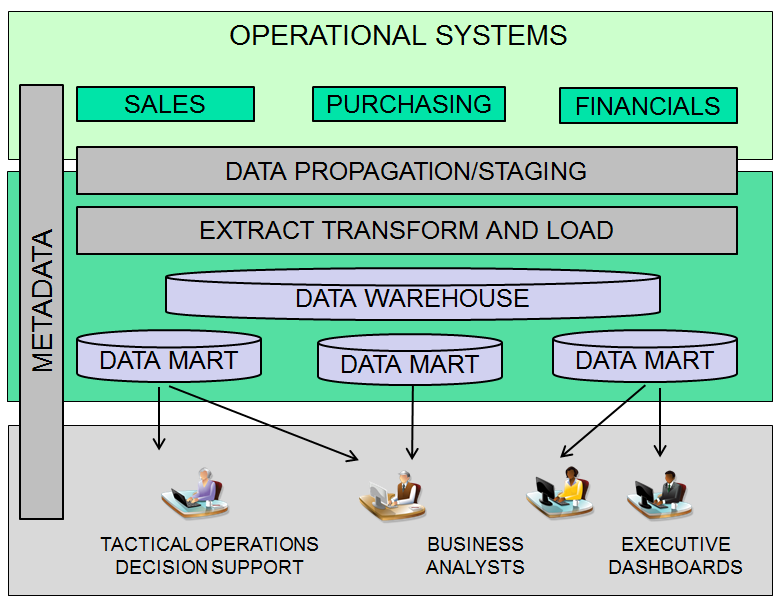
Figure 2: This is a typical data warehouse implementation.
The data warehouse contains the cleansed, consolidated, conformed data from all of your source systems. It always contains the most detailed level of information that is available. This is the "master collection" of data/information. Very few, if any, reports will be produced directly from the data warehouse.
A data mart is a table, or more commonly, a set of related tables that have been built for a specific reporting purpose. For example, you might design a data mart to support marketing reports, financial reports, or an executive dashboard. A multi-dimensional data structure used by an OLAP tool can also be considered to be a data mart. These are not usually implemented via tables but as a proprietary structure specific to the OLAP tool vendor.
You may ask, why do we need the data warehouse at all, if the marts are used for reporting? Why not just build the marts directly from the operational data? The answer is simple. Data marts are often at a summary level. They may contain derived values and calculations, and they eventually will contain many years of history. When the business requirements change (and they will) and you need, for example, to re-organize five divisions into four or change the calculation for net sales, you'll need to rebuild the affected data marts. Without the base detail level tables in the data warehouse, your only option is to go back to the operational data to perform the rebuild. If that data is no longer available, you're sunk. For this reason, it's imperative that you maintain detail-level data in a data warehouse as a means of rebuilding data marts (or creating new ones).
Metadata is an often-neglected aspect of BI infrastructure. This is the roadmap to the information stored in the data warehouse. End users can only be empowered by the warehouse if they understand the information it contains, and this can come only from the metadata. This should be a structured data repository that provides navigation, drill-down links, etc. to allow end users to explore the data warehouse structure. Business rules, descriptive text, and data lineage must be visible to the users, not buried in the extract, transform, and load (ETL) code.
Extract, transform, and load (ETL) is the technology that takes the raw, operational data and transforms it into the cleansed, conformed data in the data warehouse.
In a typical scenario, the data warehouse is built on a separate server, so none of the source data is local. If we're lucky, all of the data resides on another IBM i server or LPAR. Most likely, though, you'll also need to bring in data from other platforms or from text/delimited files, etc.
We also must consider what set or subset of data we want to extract. For transactional data, the requirement is usually to pull all new transactions since the previous extract. However, for non-transactional data (e.g., customer or product information), we often want to select only the changed records. Journal entries can provide this information for journaled files, using Change Data Capture technology. Another consideration is staging or moving the data to the target system, especially when dealing with non–IBM i data. Should a temporary copy of the data be staged on the target system as the input to the transform/load steps? Often this is a simpler approach (with fewer potential points of failure) and simpler recovery in the event of a network failure or other error during the load.
Business rules determine the transformations and logic required to translate the raw data from the data sources into meaningful information in the target database. Some data is simply mapped to the target column unchanged, but often simple transformations, such as changes from numeric to character, concatenation, substring processes, and arithmetic calculations need to be applied. And in some cases, complex conditional logic may also be required.
You must also expect to encounter errors or omissions in the source data. Therefore, the business rules must also specify data-quality criteria. This implies a supporting infrastructure to report and manage data errors. The business rules must either correct errors where possible (e.g., by substituting a default value for missing or invalid values) or set aside those errors that cannot be fixed automatically for later manual correction.
The final load outputs the transformed data to the target table(s) in the data warehouse. While in some cases this is a simple insert, it's often more involved. For changes to existing rows, the row must be updated: This could require numeric values to be aggregated rather than replaced and so forth, so more rules may be required.
Do It Right the First Time
While all this may sound complex and challenging, it's essential for long-term success with BI. You will find that there are good ETL tools available that dramatically simplify implementing ETL, as well as building the metadata repository. Those organizations that forego an architected data warehouse and ETL almost always end up building independent data marts, with quick-and-dirty load processes. This usually results in multiple versions of the truth, duplicated effort, no metadata, and no error management, which in turn leads to a maintenance nightmare and eventual failure.
Properly implemented BI has the capability to transform your business, with increased efficiency, reduced costs, and improved profitability. Your IBM i server is perfectly well-suited to hosting a data warehouse, so there is no need to take the workload off the platform you know and love.
as/400, os/400, iseries, system i, i5/os, ibm i, power systems, 6.1, 7.1, V7, V6R1



 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online