















Analytics has greatly advanced with BLU Acceleration’s Column Store, Compute-Friendly Encoding and Compression, Parallel Vector Processing, Core-Friendly Parallelism, Scan-Friendly Memory Caching, and Data Skipping.
IBM BLU Acceleration is a collection of technologies from the IBM Research and Development Labs that accelerate analytics and reporting. It is one of the most significant pieces of technology that has ever been delivered in DB2 and, arguably, the database market in general; it delivers unparalleled performance improvements for analytic applications and reporting using dynamic, in-memory optimized, columnar technologies.
Simple to Implement and Use
Arguably, one of the most important design principles of BLU Acceleration was simplicity and ease of use. As a result, a significant amount of autonomics and intelligence around BLU Acceleration has been built into the DB2 engine. Basically, all a user needs to do to take advantage of this technology is configure a DB2 10.5 database environment for BLU Acceleration (by assigning the value ANALYTICS to the DB2_WORKLOAD registry variable), create the tables needed, load them with data, and then run queries against them. It’s that simple. Database administration procedures and the SQL language used remain unchanged, as do system commands, utilities, and the DB2 storage model.
Because of the way in which BLU Acceleration has been designed, there is no need to create indexes, multidimensional clustering (MDC) tables, materialized query tables (MQTs), statistical views, materialized views, or partitioned tables to improve query performance. And without these auxiliary objects, administrative and maintenance efforts are greatly reduced.
Column Store
The most prominent feature found in BLU Acceleration is a new, in-memory, columnar table type. Unlike row-organized tables, which store data for complete records (rows) in pages and extents, column-organized tables store data for individual columns in pages and extents. Figure 1 shows how data for a row-organized table is stored; Figure 2 illustrates the storage methodology that is used for a column-organized table that has similar characteristics.
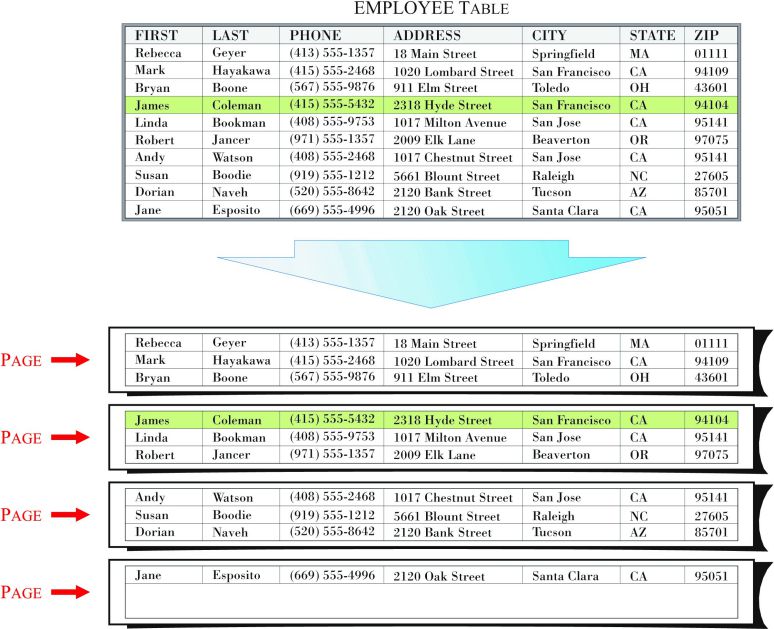
Figure 1: How data for a row-organized table is stored
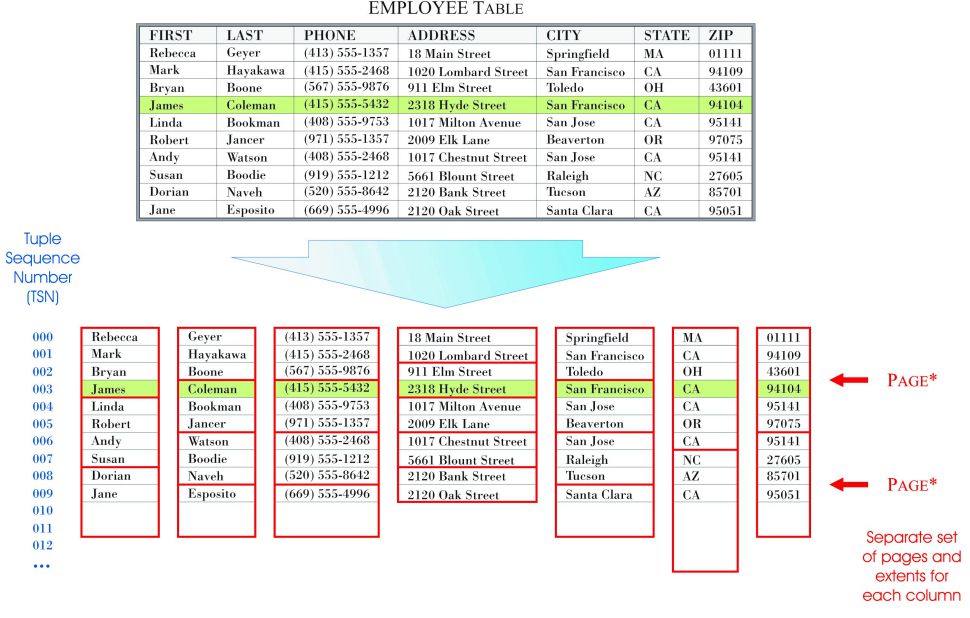
Figure 2: How data for a column-organized table is stored; the Tuple Sequence Number (TSN) is a logical row identifier that is used to “stitch together” values from the different columns that form a row.
Storing data by column offers several benefits to analytic workloads. For one thing, such workloads tend to access a subset of the columns found in one or more tables. So, by storing data using a columnar approach, DB2 only has to move data for the appropriate subset of columns from disk to memory (as opposed to having to move data for an entire row). This ensures that only the data that is needed is retrieved from disk with every I/O operation that’s performed. And, because more data values can be stored on a single page, fewer I/O requests are required. Another benefit is that column-organized tables tend to compress very efficiently—the probability of finding repeating patterns on a page is high when the data on that page comes from a single column.
Compute-Friendly Encoding and Compression
Another key feature of BLU Acceleration is the way in which data for column-organized tables is encoded and compressed—column-organized tables are compressed automatically, using a technique known as approximate Huffman encoding. With this form of compression, values that appear more frequently are encoded at a higher level than values that don’t appear as often. Using a serial stream of zeros (0s) and ones (1s), each value is assigned eight bits. Then, the encoded data is packed as tightly as possible into a collection of bits that equal the register width of the CPU being used. Figure 3 illustrates how this type of compression works.
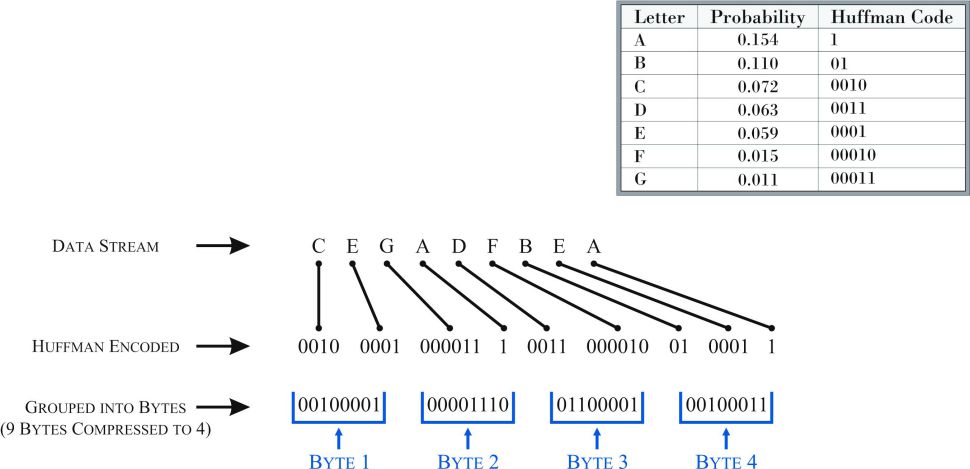
Figure 3: How approximate Huffman encoding works
Another compression optimization technique that’s used in BLU Acceleration is a process known as offset coding. Offset coding is very useful with numeric data; instead of trying to compress a set of numbers like 100, 101, 102, and 103, DB2 will store the first value (100) and then it will store the appropriate offsets from that value (1, 2, 3, and so forth) for the remaining numbers in the set.
Generally, compression for column-organized tables can be anywhere from 3 to 10 times better than that of similar row-organized tables. More importantly, data stored in column-organized tables does not have to be decompressed before it can be used in many SQL operations—operations that perform predicate evaluations, joins, and data grouping can work directly with encoded data. This enables DB2 to delay the materialization of compressed data for as long as possible, which leads to a more effective use of CPU and memory, along with a reduction in disk I/O.
Parallel Vector Processing
Another important feature of BLU Acceleration is its ability to exploit a leading-edge technology that is found in many of today‘s modern processors: Single-Instruction, Multiple-Data (SIMD) processing. SIMD instructions are low-level CPU instructions that enable an application to perform the same operation on multiple data points at the same time. BLU Acceleration will auto-detect when DB2 is running on a SIMD-enabled CPU and automatically exploit SIMD to effectively multiply the power of the processor. For example, suppose a query designed to produce a list of all purchases made in December is executed. Without SIMD, the processor must evaluate the query predicate (i.e., does MONTH = 'December'?) one value at a time. Each value for MONTH (for example, September, October, November) would be loaded into its own processor register, and multiple iterations of the instruction would be required. With SIMD, the results for all three months could be obtained with a single instruction, provided the values are loaded into the same register. This results in faster predicate processing. Figure 4 illustrates how the scenario just described might be processed by a SIMD-enabled CPU.
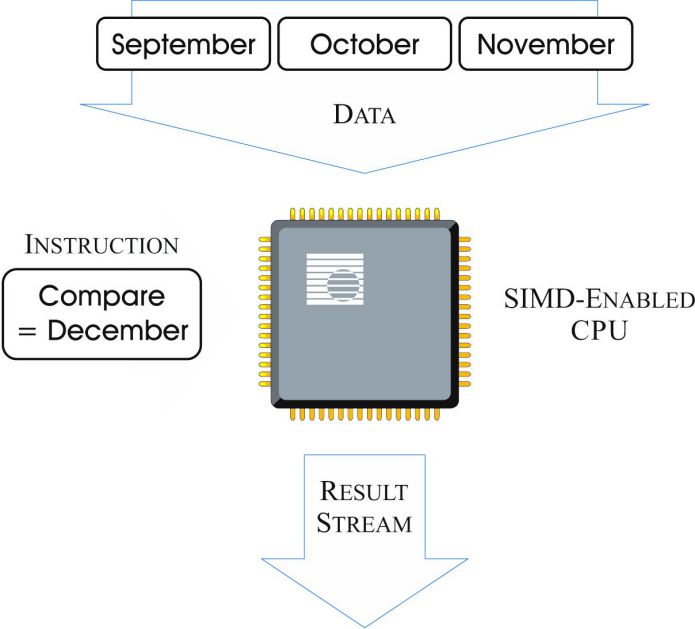
Figure 4: SQL query predicate evaluations with a SIMD-enabled CPU
Although the example just presented demonstrates how SIMD helps with predicate evaluation, it’s important to note that SIMD exploitation can be used to do scans, joins, grouping, and arithmetic operations. Also, in the previous example, three data values (September, October, and November) were used for display purposes only; the actual number of data elements that can be processed by a single instruction is determined by the size of each element.
Core-Friendly Parallelism
Core-friendly parallelism refers to BLU Acceleration’s ability to take advantage of the growing number of cores found on CPU processors to drive multicore parallelism for queries. This is accomplished through the use of several comprehensive algorithms that determine where data that will be revisited should be placed in CPU cache, as well as how work should be shipped across every socket. To maximize parallelization and throughput, all processor cores, memory, and threads available is utilized.
Scan-Friendly Memory Caching
Most databases employ variations of what are known as Least Recently Used (LRU) and Most Recently Used (MRU) paging algorithms to keep data that was recently accessed in memory and to remove older data when space for new data is needed. But these algorithms do not work well with analytical workloads. That’s because analytical workloads are likely to start at the top of a table and scan their way to the bottom. And if the table is large, the LRU algorithm will remove pages that were read at the start of the scan to make room for those read at the end. Consequently, the next time a scan of the same table is initiated (say, to perform an aggregation or join operation), memory is searched for pages that were read from the beginning of the table, and when they’re not found, they have to be retrieved from disk.
To resolve this issue, a special “scan-friendly” memory caching algorithm was developed and incorporated in BLU Acceleration. This algorithm works by detecting “interested” data patterns that are likely to be revisited, and then holding pages with similar data patterns in memory as long as possible.
Data Skipping
The last important feature that’s available with BLU Acceleration is the ability to skip ranges of data that are not relevant to an active query. For example, if a query needs to calculate the total dollar amount of every order placed during the month of January, BLU Acceleration can go straight to the data that contains order information for just that month and skip over all non-qualifying data. That’s because as operations are performed against column-organized tables, BLU Acceleration generates metadata that describes the minimum and maximum range of the data values found in “chunks” of data records. (The ranges are associated with approximately 2,000 records.) This metadata is then stored in a special internal table known as a synopsis table and is updated automatically as INSERT, UPDATE, and DELETE operations are performed.
When an analytic query is executed, BLU Acceleration examines the appropriate synopsis table(s) to identify “chunks” that contain data the query is looking for. It then goes straight to those “chunks” and retrieves the data desired.
Editor’s note: This article is adapted from DB2 10.5 Fundamentals for LUW: Certification Study Guide, chapter 2.

Roger E. Sanders is a Principal Sales Enablement & Skills Content Specialist at IBM. He has worked with Db2 (formerly DB2 for Linux, UNIX, and Windows) since it was first introduced on the IBM PC (1991) and is the author of 26 books on relational database technology (25 on Db2; one on ODBC). For 10 years he authored the “Distributed DBA” column in IBM Data Magazine, and he has written articles for publications like Certification Magazine, Database Trends and Applications, and IDUG Solutions Journal (the official magazine of the International Db2 User's Group), as well as tutorials and articles for IBM's developerWorks website. In 2019, he edited the manuscript and prepared illustrations for the book “Artificial Intelligence, Evolution and Revolution” by Steven Astorino, Mark Simmonds, and Dr. Jean-Francois Puget.
From 2008 to 2015, Roger was recognized as an IBM Champion for his contributions to the IBM Data Management community; in 2012 he was recognized as an IBM developerWorks Master Author, Level 2 (for his contributions to the IBM developerWorks community); and, in 2021 he was recognized as an IBM Redbooks Platinum Author. He lives in Fuquay Varina, North Carolina.
MC Press books written by Roger E. Sanders available now on the MC Press Bookstore.
 |
QuickStart Guide to Db2 Development with Python Discover how Python, SQL, and Db2 can successfully be used with each other. List Price $9.95 Now On Sale
|
|
 |
DB2 10.5 Fundamentals for LUW (Exam 615) Don't even think about attempting to take the DB2 Fundamentals exam without this indispensable study guide. Now On Sale
|
|
 |
DB2 10.1 Fundamentals (Exam 610) Let one of the world's leading DB2 authors and a participant in the exam development help you succeed. List Price $79.95 Now On Sale
|
|
 |
Artificial Intelligence: Evolution and Revolution Operational AI has become available to the masses, setting the wheels in motion for a worldwide AI revolution that has never been seen before. Now On Sale
|
|
 |
DB2 10.5 DBA for LUW Upgrade from DB2 10.1: Certification Study Notes Here's everything you need to know to take and pass Exam 311, complete with a practice exam and study key. List Price $21.95 Now On Sale
|
|
 |
From Idea to Print Here's everything you need to know to turn your technical knowledge and expertise into a published article or book. Now On Sale
|
|
|
DB2 9 Fundamentals (Exam 730) Use this review before taking the test to prove you've mastered the basics of DB2 9. List Price $59.95 Now On Sale
|
|
 |
DB2 9 for Linux, UNIX, and Windows Database Administration (Exam 731) Use this indispensable study guide to prepare to take, and pass, Exam 731. Now On Sale
|
|
 |
DB2 9.7 for Linux, UNIX, and Windows Database Administration (Exam 541) Get ready to take the DB2 9.7 certification exam with this handy study guide. List Price $21.95 Now On Sale
|
|
 |
DB2 9 for Linux, UNIX, and Windows Advanced Database Administration (Exam 734) Review all exam topics and take the included practice test to be sure you're ready on testing day. Now On Sale
|
|
 |
DB2 9 for Linux, UNIX, and Windows Database Administration Upgrade (Exam 736) Prep for success with the master of DB2 certification study guides! List Price $34.95 Now On Sale
|
|
 |
Data Fabric: An Intelligent Data Architecture for AI This book explains the concepts and values that a data fabric approach can deliver to both technical and business communities. Now On Sale
|
|



 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online