















Referential integrity (RI) is one of several important new database functions announced in V3R1. RI is inherent in any database integrity scheme, whether it is implemented by an application or by the database software itself. The simplest definition of RI is that it defines a relationship between two files in which one is the parent and one is the dependent (child). Records in the dependent file are joined to a unique key in the parent file. For example, the order header file is a dependent file to the customer master file and must contain a valid customer number.
On the AS/400, data integrity rules have typically been enforced by application programs. RI enforces those same rules at the database level, and there are certain advantages inherent in this approach.
? RI is enforced no matter what application updates the database. Whether you use an RPG program, a client/server application, a DFU, or a query, the rules are enforced.
? RI reduces redundant code, and the remaining code is more standardized because each application is not maintaining the data relationships.
On the other hand, you must take some design considerations into account if you want to use RI effectively. For instance, RI will not function well unless you normalize your database (see "Common Sense Normalization" elsewhere in this issue). Some RI rules require journaling both files to the same journal receiver, and, in general, you'll need to reconsider your use of journaling and commitment control. There is an implicit performance, maintenance, and disk usage overhead in applications that utilize journaling.
Most important of all, using RI requires a level of design discipline that may not be available in your installation. It's up to each application to handle violations of the RI rules. What if somebody assigns RI rules to a file that your program uses and doesn't notify you? The database will enforce the rule, your program will get an error, and the users will call you. If there was ever a clear case for why complex databases require database administrators, this is it.
You must consider these issues before you can use RI effectively, but, in this article, I'll concentrate on how RI is defined and the different ways you can implement it.
Referential Constraints
When the rules that govern the relationship between two files (e.g., the order header file must contain a valid customer number) are implemented at the database level, they are called referential constraints. A single file can have many referential constraints, and one file can be the dependent file for some constraints and the parent file for others. An example is the order header file, which is the dependent file in its relationship with the customer master file but the parent file in its relationship with the order lines file.
Selecting referential constraint rules is the process of determining what you want to do if an application violates the relationship between the two files. For instance, what do you want to do if a user attempts to delete a customer record that has outstanding orders? The answer depends on the particular needs of the business. One company might prohibit such customer deletions; another company might delete all outstanding orders; a third company might run a special report notifying the sales manager of the potential lost sales. DB2/400 does not provide the business rules; it provides programming tools that you can use to enforce some business rules.
On the AS/400, referential constraints can only be defined for physical files, but they automatically apply to any logical file based on the physical files. 1 provides a listing of the AS/400 commands associated with referential constraints.
On the AS/400, referential constraints can only be defined for physical files, but they automatically apply to any logical file based on the physical files. Figure 1 provides a listing of the AS/400 commands associated with referential constraints.
Referential constraints are based on the concept of a database event. A database event is an add, change, or delete to a record in a file. In database terms, add transactions are usually called inserts, and change transactions are almost invariably called updates. I'll use this terminology because it meshes with what you'll find in the IBM manuals and the names and parameters of OS/400 commands.
Some RI terminology makes sense to database designers but seems foreign to many AS/400 programmers. I'll avoid most of this terminology, and I'll define the other terms as I use them. Here are a few that you'll need to get started.
Dependent (or child) file: As you might expect, the dependent file is the "lower" of the two files whose relationship is described by an RI constraint. In our example, the order lines file is a dependent file to the order header file; the order header file is a dependent file to the customer master file; and the customer master file is a dependent file to the salesman file because the salesman code in the customer master file must match a valid salesman number defined by the salesman file.
Parent file: A parent file is the "upper" member of the pair of files described by an RI constraint. The customer master file is the parent file to the order header file because each order header record must contain a valid customer number defined by the customer master file.
Parent key: A parent key is a field or a set of fields used to join the parent file to the dependent file. For example, when a referential constraint defining the relationship between the order header file and the customer master file is established, the customer number in the customer master file is the parent key. An access path must be established for the parent key, and either a primary key constraint or a unique constraint must be defined for the parent key. (Primary key constraints and unique constraints are explained in the next section.)
Foreign key: A foreign key is the field (or fields) in a dependent file that match the parent key of the parent file; an access path must be maintained for this key. Like any OS/400 function, RI will utilize an existing access path if one is available.
Primary Key Constraints and Unique Constraints
There are actually three types of constraints?primary key constraints, unique constraints, and referential constraints. In most cases, when the term constraint is used without qualification, it refers to a referential constraint. Before you can add a referential constraint to a pair of files, either a primary key constraint or a unique constraint must be defined for the parent key.
This terminology would be easier to understand if a unique constraint was called a unique key constraint. In fact, that is what a unique constraint is?a unique key to the parent file. The difference between a primary key constraint (*PRIKEY) and a unique constraint (*UNQCST) is defined in the following paragraphs.
Primary key constraint: A parent file does not necessarily have to have a primary key; it is a special case of the unique key. A logical way to define a primary key is as the most commonly used unique key for any file. Examples include the customer number for the customer master file and the order number for the order header file. In many cases, only a primary key constraint will be defined for the parent file; no unique constraints will be defined.
Unique constraint: A unique constraint is any unique key to a parent file other than the primary key. The usual purpose is to define the key in the parent file that specifies the relationship with the dependent file.
There are two major differences between primary and unique keys.
1. There can be only one primary key for a file, but as many unique keys as necessary (up to the maximum of 300 constraints per file) can be defined.
2. Null values are allowed for unique keys but not for primary keys.
Primary key and unique constraints define keys in the parent file that will be used by referential constraints. A primary key or unique constraint is required before a referential constraint can reference a parent file.
In some cases, OS/400 will create a primary key or unique constraint automatically when a referential constraint is defined. Regardless of whether the constraint that defines the parent key is a primary key constraint or a unique constraint, defined explicitly or defined automatically by OS/400, it must exist before a referential constraint can be defined.
Primary key and unique constraints are included in the maximum of 300 constraints allowed for a file and are displayed when you run the Work with Physical File Constraints (WRKPFCST) command for the parent file.
Defining Referential Constraints
Three constraint rules describe the relationship between each dependent file and its parent file. If you assign referential constraints to a file at all, you must define a rule for each transaction type?insert, update, and delete. Each transaction type may use a different rule.
To illustrate a simple example of RI, I'll use a customer master file and an order header file. The logical relationship between these files is familiar to most AS/400 programmers, and the rules that I'll be implementing using RI are usually implemented using application programs. The advantage of RI is that I can implement the rules once and be confident that OS/400 will always enforce them.
The Insert Rule: Inserts are the simplest type of constraint. Only one possibility is valid: a record cannot be added to the dependent file unless there is a matching key in the parent file. In this example, an order cannot be added unless it contains a valid customer number. The name of this rule is "No Action." No Action is used repeatedly to describe RI constraints that forbid completion of a transaction.
The Update Rules: Update constraints are also relatively straightforward. There are two possible values: No Action or Restrict. Both prevent any update that results in a dependent file record that has no matching record in the parent file.
In our example, this means two things: it is invalid to change a customer number in the order header file to a customer number that does not exist; and (less obviously) it is invalid to change a customer number in the customer master file if any orders exist for the old customer. This second rule is seldom enforced because most applications do not allow changes to a file's key. However, part of the benefit of implementing RI at the database level is that OS/400 enforces the rules regardless of any misbehavior by an application.
The difference between No Action and Restrict is subtle and doesn't become entirely clear until you look at applications that use both RI and triggers. (Triggers are another new database function introduced in V3R1. OS/400 automatically calls a trigger program when a specific database event occurs. For more information, see "Referential Integrity & Triggers in DB2/400," MC, November 1994.)
For the sake of definition, the difference between No Action and Restrict is that Restrict checks whether the relationship between the parent file and the dependent file is valid before other database events (e.g., a trigger program) occur; No Action checks for a constraint violation after other database events have completed.
For a quick illustration of the difference between No Action and Restrict, consider the situation in which an order is updated and the new customer record doesn't exist yet. If the No Action rule is used, the order header file update could fire a trigger program that creates the new customer record before the constraint is checked.
The Delete Rules: Delete rules are the most complex referential constraints. You should consider delete rules from the perspective of the parent file because any record can be deleted from the dependent file without violating any referential constraint. Restrictions for deleting records are less straightforward than for inserting or updating. For example, a No Action rule for insert and update transactions raises no logic issues. It is invalid to have orders for customers that don't exist. The only issue is how new customers should be added during order entry.
A No Action restriction for delete transactions poses other problems. It may be perfectly logical to delete a record from the parent file, but if the delete is simply allowed to take place, the relationship between the parent file and the dependent file that was previously enforced is invalidated. The other delete constraint rules give the application designer options so that records can be deleted from the parent file when necessary. The net result in all cases is that records in the dependent file are not allowed to point at a parent file record that has been deleted.
No Action and Restrict for delete constraints are very similar to the update rules. You cannot delete a record from the parent file if any records in the dependent file are associated with it.
The Cascade rule deletes all associated dependent file records when a record is deleted from the parent file. The Cascade rule provides programmers with a very powerful function, but it also creates design and performance considerations.
The Set Null and Set Default rules are very similar to each other. In both cases, foreign key values (the values that point from the dependent file to the parent file) are reset when the parent file record is deleted. Because deleting a single parent file record may affect multiple dependent file records, Set Null and Set Default are subject to performance considerations similar to those for the Cascade rule.
The values that the foreign keys are set to depend on whether Set Default or Set Null is used and what the default values for the foreign key fields are. Default values, including null, can be specified in DDS. If no defaults are specified in the DDS, the defaults for the field type are used (e.g., character fields are set to blanks). Set Default will be processed only if the default values result in a valid key to the parent file.
For example, suppose a salesman leaves the company; you can use the Set Default constraint to assign his orders to the house account. This is a four-step process.
1. Define the house account in the salesman master file.
2. Make the salesman number of the house account (e.g., 001) the default for the salesman number in the order header file.
3. Use RI to define the relationship between the order header file and the salesman master file. Use a delete constraint of Set Default.
4. Delete the salesman's record from the salesman master file. His accounts will be set to salesman number 001 based on the default value assigned to the order header salesman number field.
Set Null only makes sense for foreign key fields defined as null-capable (i.e., ALWNULL keyword specified in the DDS field definition). Currently, null-capable fields are fairly rare in AS/400 databases. Set Null is included as a valid constraint to improve conformance with other databases and to allow for future changes to the database.
Assigning Constraints
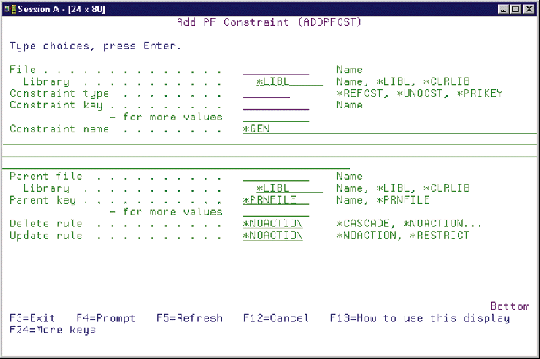
On the AS/400, all types of constraints?primary key, unique, and referential?are defined using the Add Physical File Constraint (ADDPFCST) command. The ADDPFCST panel is shown in 2. This command is central to the implemen-tation of RI on the AS/400.
On the AS/400, all types of constraints?primary key, unique, and referential?are defined using the Add Physical File Constraint (ADDPFCST) command. The ADDPFCST panel is shown in Figure 2. This command is central to the implemen-tation of RI on the AS/400.
Several rules apply to all constraints?primary key, unique, or referential.
? Constraints can only be defined for physical files, although referential constraint rules will be enforced if a physical file is updated through a logical file.
? The files involved in a constraint definition can have a maximum of one member each. The file must be defined as MAX-MBR(1). No more than one member can actually exist.
? Constraint names must be unique in a library.
? Constraints cannot use a file in the QTEMP library.
Four parameters of the ADDPFCST command are used to define primary key or unique constraints.
FILE: This parameter designates the file you are defining an access path for.
TYPE: *UNQCST defines a unique key, and *PRIKEY specifies that the fields entered for the KEY parameter make up the primary key of the file.
KEY: This parameter designates the field or fields that are used to build the access path.
CST: Use this parameter to designate the constraint name. The special value *GEN will generate a constraint name, but I recommend that you name your constraints.
A primary key or unique constraint may be created implicitly by OS/400 when a referential constraint is added if a unique keyed access path already exists on the designated parent key.
Referential constraints are attached to the dependent file and are assigned using the ADDPFCST command.
FILE: The first parameter of ADDPF-CST designates the dependent file for RI constraints.
TYPE: An entry of *REFCST specifies a referential constraint.
KEY: For a referential constraint, the field or fields entered in this parameter determine the foreign key in the dependent file that points to the parent key (either a primary key constraint or a unique constraint) in the parent file.
CST: This parameter can be used to assign a name to a constraint.
PRNFILE: This parameter designates the parent file for a referential constraint.
PRNKEY: This parameter defines the key to the parent file used to enforce the referential constraint. You can specify one or more fields. The default is the special value *PRNKEY.
A value of *PRNKEY will use the primary key if one has been defined for the parent file. It can also use a unique constraint if only one is defined for the parent file. If more than one unique constraint is defined for the parent file and no primary key constraint is defined for the parent file, specifying *PRNKEY generates an error message.
UPDRULE and DLTRULE: These two parameters are used to designate the referential constraint rules to be used for updates and deletes, respectively. The insert rule is not explicitly defined because only one value is valid for an insert constraint?No Action. When you add constraints to a physical file, all three types?insert, update, and delete?are added with a single ADDPFCST command. You cannot add just an insert constraint. Therefore the UPDRULE and DLTRULE parameters are required if the TYPE parameter is *REFCST.
Once you create a referential constraint for a file, you cannot change it; you can only remove it by using the Remove Physical File Constraint (RMVPFCST) command.
You can view all constraints for a dependent file by using the Display File Description (DSPFD) command.
RI Design Errors
When you run the ADDPFCST command, all the relationships between existing records in the two files are verified. A check pending condition occurs when the existing data in the file violates the referential constraint rules. In this case, the ADDPFCST command issues an error. The constraint is added to the file, but it is immediately disabled.
By running the Work with Physical File Constraints (WRKPFCST) or the Display Check Pending Constraint (DSPCPCST) commands, you can see the records that caused the check pending situation. In most cases, these records actually contain invalid data that other data validation techniques did not catch. You can eliminate the check pending condition by using a DFU or an application program to correct the data, and then using the WRKPFCST or Change Physical File Constraint (CHGPFCST) command to enable the constraint.
Deciding When to Use RI
Like any other development tool, RI is useful in some situations and harmful in others. There is no set of specific rules that you can use to make these design decisions. The most important design consideration for RI is whether to use it at all. A more complex overall application design and more stringent database administration are intrinsic in the use of RI.
Should you use it? I believe the answer is yes. However, RI is no magic bullet. If difficulties can occur because each applications programmer has implemented a business rule differently, imagine the potential havoc inherent in interpreting the business rules and enforcing them using RI.
Before you can take full advantage of RI, you should be able to draw a diagram of the relationships between all the files on your system. Not that you necessarily need to actually produce the diagram, it's just that you need that level of understanding about how the data elements interact.
You'll also have to deal with some database design issues. At a minimum, you'll need to implement journaling for the specific cases that require it. (In 3, the rules that require journaling are shown in red.) More realistically, you must completely examine your journaling and commitment control strategy.
You'll also have to deal with some database design issues. At a minimum, you'll need to implement journaling for the specific cases that require it. (In Figure 3, the rules that require journaling are shown in red.) More realistically, you must completely examine your journaling and commitment control strategy.
Before RI is implemented for any pair of files, make sure that you know all the applications that affect those files and that you have a good mechanism in place so that new applications will be designed with the RI constraints in mind.
A key issue is ongoing development. Once you've added referential constraints to a pair of files, the constraints will always be enforced. Your developers must include error-handling routines in every application?whether it is host-based or client/server, interactive or batch. (An upcoming article will illustrate RI error-handling.)
Next, there are performance issues. As an example, if an average customer has 1,000 open orders, you may not be able to use a delete Cascade constraint even though it accomplishes your logical goal. You probably don't want to delete 1,000 orders interactively when you delete a customer number. In this case, you might consider using a trigger program that calls a batch process instead. Again, the specific situation governs the design decision.
As a rule of thumb, use RI when the relationship between two files is inviolable. For instance, order line records must be associated with an order header record, but you may allow situations where the customer number is assigned after the order is created. If this is your application design, the relationship between order line file and the order header file is a prime RI candidate, but the relationship between the order header and the customer master may require a different solution.
Don't let these restrictions scare you off. It's easy to start small with RI because any referential constraint involves only two files. This point is worth reiterating because the overall database design involves much more complex relationships. For example, the relationships between the order line file, the inventory file, the order header file, the sales analysis file, the customer master file, the salesman file, and a variety of code files actually describe the entire order entry application and may have implications for accounts payable as well. If you attempt to resolve all these relationships before you start using RI, you may end up with a stalemate. My recommendation is to bear in mind the big picture but to go ahead and start using RI in specific applications when you are confident that you have defined all the relationships between a pair of files.
RI exists because it makes more sense to control database relationships at the database level than to let each applications programmer try to implement the rules. Like any component of your programming toolkit, you cannot put it to work until you've learned its strengths and weaknesses. Properly used, RI can help ensure the integrity of your data and implement your business rules more consistently.
Sharon Hoffman is the editor of Midrange Computing.
References
Database 2/400 Advanced Database Functions (GG24-4249, CD-ROM GG244249).
OS/400 CL Reference V3R1 (SC41-3722, CD-ROM QBKAUP00).
OS/400 DB2/400 Database Programming V3R1 (SC41-3701, CD-ROM QBKAUC00).
DB2/400 Referential Integrity
Figure 1: Referential Constraint Commands
Add Physical File Constraint (ADDPFCST)
Assign the constraint rules for insert, update, and delete to a pair of files.
Change Physical File Constraint (CHGPFCST)
Change the status of a referential constraint from enabled to disabled or vice versa.
Display Check Pending Constraint (DSPCPCST)
Display the records causing the check pending condition for a constraint that is in check pending status.
Edit Check Pending Constraints (EDTCPCST)
Display constraints in check pending status and schedule reverification of the constraint relationships.
Remove Physical File Constraint (RMVPFCST)
Delete the constraint relationship assigned with an ADDPFCST command.
Work with Physical File Constraints (WRKPFCST)
Display and edit constraints including files and records in check pending status.
DB2/400 Referential Integrity
Figure 2: The ADDPFCST Command
DB2/400 Referential Integrity
Figure 3: Journaling Requirements for Constraints
Insert Update Delete Constraints Constraints Constraints No Action No Action No Action Restrict Restrict Cascade Set Default Set Null ? Requires Journaling


 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online