















Learn ways to keep your database code lean and mean, resulting in better performance.
This third tip in the series continues where Part 1 and Part 2 left off. Presented herein are some general guidelines for how to make your database code purr like a kitten.
Combine Individual Insert Statements
I often see developers do things in SQL one step at a time, when the steps can be combined into a single statement. Consider the following code that inserts data multiple times into the same table:
INSERT INTO SPECIAL_CHARGES
(SalesOrderId,ChargeDesc,ChargeAmount)
VALUES(@SalesOrderId,'Taxes',@TaxAmount);
INSERT INTO SPECIAL_CHARGES
(SalesOrderId,ChargeDesc,ChargeAmount)
VALUES(@SalesOrderId,'Freight',@FrtAmount);
INSERT INTO SPECIAL_CHARGES
(SalesOrderId,ChargeDesc,ChargeAmount)
VALUES(@SalesOrderId,'Handling',@HndAmount);
These three INSERTs can be combined into one:
INSERT INTO SPECIAL_CHARGES
(SalesOrderId,ChargeDesc,ChargeAmount)
VALUES
(@SalesOrderId,'Taxes',@TaxAmount),
(@SalesOrderId,'Freight',@FrtAmount),
(@SalesOrderId,'Handling',@HndAmount);
According to my SQL monitor, DB2 processed the tri-row INSERT statement in about the same amount of time as one of the single-row statements. Prior to IBM i 6.1 and the VALUES clause, a UNION ALL operator could be used to create a single result set as well:
INSERT INTO SPECIAL_CHARGES
(SalesOrderId,ChargeDesc,ChargeAmount)
SELECT @SalesOrderId,'Taxes',@TaxAmount
FROM SYSIBM.SYSDUMMY1
UNION ALL
SELECT @SalesOrderId,'Freight',@FrtAmount
FROM SYSIBM.SYSDUMMY1
UNION ALL
SELECT @SalesOrderId,'Handling',@HndAmount
FROM SYSIBM.SYSDUMMY1
In this case, the UNION ALL statement is only slightly faster than the three individual insert statements.
With simple examples like this, it’s not likely to make a big impact on the system, and users will not notice a small fraction of a second difference. However, as I mentioned in Part 1 about combining multiple update statements into one, think about the many things DB2 has to deal with when changing table data:
- Security authorization check
- Constraint processing (primary key, foreign key, unique index, check constraint)
- Update of secondary indexes
- Trigger processing
- Checking for locks held by other processes
- RCAC processing (optional)
- Transaction processing (optional)
- Generating journal entries (optional)
Why make DB2 for i do the work several times instead of once? Coding correctly, even in trivial cases, will foster good habits as developers realize the implications of their code in the eyes of DB2.
One more thing: Not every group of INSERTs into the same table should necessarily be combined into one statement for optimization purposes. If the data sets being inserted are large, there could be a decrease in performance for other users due to DB2 holding locks for a longer period of time (potentially blocking other processes, etc.) due to DB2 having to take longer to sort the combined rows before inserting into the table, etc.
Avoid Operations That Cause Table or Index Scans
In contrast to the prior tip about combining several steps into one, this tip involves breaking apart a complicated SQL statement into simpler parts that are easier for DB2 to digest.
Consider this seemingly innocuous query that gets the order detail for a parent order and companion child orders (with SalesOrderId as the high order primary key column):
SELECT *
FROM SalesOrderDetail
WHERE SalesOrderId=@ParentOrderId
OR SalesOrderId IN (SELECT ChildOrderId FROM Session.ChildOrders)
The WHERE predicates contain two simple requests that should be easy for DB2: Get the detail for the parent order (stored in a variable) and any child orders (stored in a temporary table). However, because of the OR operator, DB2 has to scan through all the order IDs to see if there is a match with the requested parent order ID or child order IDs.
There are 121K rows in the SalesOrderDetail table, and DB2 decided to scan one of the table’s smaller indexes to find which order numbers are a match, as shown in the Visual Explain plan in Figure 1a:
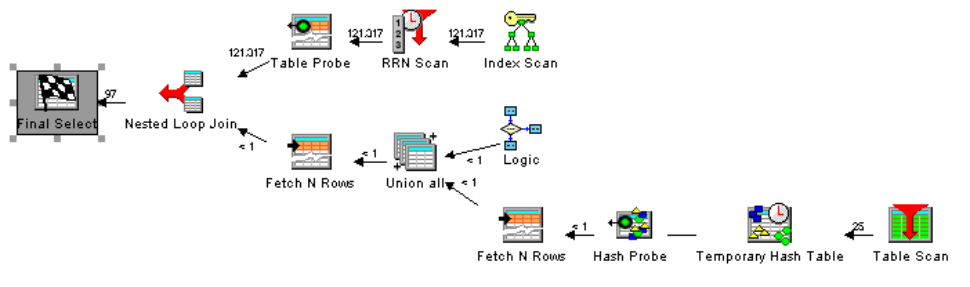
Figure 1a: In this Visual Explain representation of the steps taken to access the data, notice how the OR in the WHERE clause forces DB2 to scan all of the order IDs in one of the table’s secondary indexes (top right index scan operator).
In contrast, if the query is broken into two segments (one for each search type: parent order ID and child order IDs), the resulting query actually reduces the work for DB2:
SELECT *
FROM SalesOrderDetail
WHERE SalesOrderId=@ParentOrderId>
UNION ALL
SELECT *
FROM SalesOrderDetail
WHERE SalesOrderId IN (SELECT ChildOrderId FROM Session.ChildOrders)
The reason that this type of query is better for DB2 is because the simplified WHERE predicates (without an OR) allow DB2 to access the data by the table’s primary key for just the requested SalesOrderIds without having to read through every SalesOrderId. The improved access plan is evidenced by the simplified Visual Explain diagram:
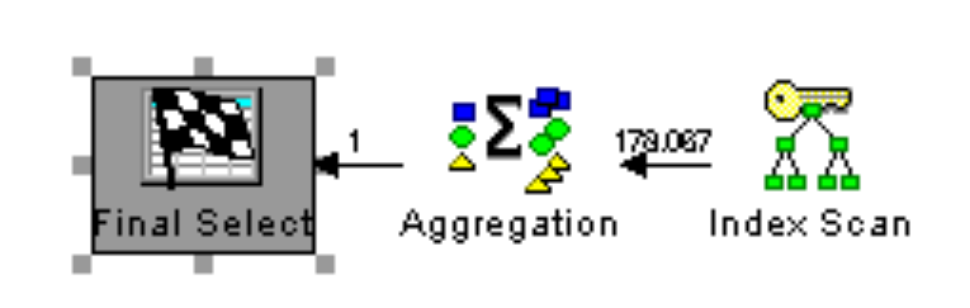
Figure 1b: This query plan is much simpler than its predecessor because, even though there are two separate queries combined with a UNION ALL, DB2 can use the table’s primary key to get the information it needs without having to scan through all of the sales order IDs.
Between these two scenarios, on average, the second version of the query performed 2–3 times faster than the first one. The speed improvement can be even more dramatic when the queries are run the first time or when there is a greater volume of data.
Alternatives for simplifying the query would be to add the parent ID to the temporary table of child IDs (if possible) or to combine the child order IDs with the parent ID in a single subquery as follows:
SELECT *
FROM SalesOrderDetail>
WHERE SalesOrderId IN
(SELECT ChildOrderId FROM Session.ChildOrders
UNION ALL
SELECT * FROM (VALUES(@ParentOrderId)) D(ParentOrderId)
);
Refactoring Reaps Benefits
When refactoring database code, as a general rule, I will combine smaller steps (in terms of work done by a single SQL statement) into a single step where possible (as shown in the first example). But for medium and larger statements, I’m more cautious about combining them in the manner shown above (and if I don’t have time to test my changes compared to the original, I leave existing code alone!). In contrast, sometimes SQL statements doing a large amount of work can be broken into multiple statements or rewritten to allow DB2 to process the data more efficiently.
Optimize, Optimize, Optimize
These code samples are presented to demonstrate how certain coding practices can make DB2 work harder than it needs to. Whether preventing a trigger from needlessly firing multiple times or preventing DB2 from doing a full index scan (often a waste of I/O and memory), good coding practices lead to better-performing applications.


 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online