















I like to consider myself an active user of the many discussion forums that are available on the Internet. In Midrange Computing’s discussion forums (www.midrangecomputing.com/ forums), the Usenet discussion forums (comp.sys.ibm.as400. misc), and the MIDRANGE-L mailing list (www.midrange.com), I’ve noticed a few requests from new users, and experienced users, that keep popping up. One of these questions deals with report duplication and distribution.
If you aren’t familiar with this question, here’s the basic idea. People are looking for a way to duplicate spooled files, and, in most cases, they also want to be able to send the duplicated report to another output queue for distribution. For example, let’s assume you have a program that generates a sales report. At first, this program simply printed the report to your default printer. The printed report was then sent to the appropriate department or personnel in your company. Now that it is simple to attach almost any network printer to your AS/400, you are probably getting requests from users to send the report to another output queue so they do not have to jaunt down to the printer in the computer room to pick it up. This situation is usually easily remedied by a simple Override Printer File (OVRPRTF) statement in your application to redirect the output.
But now comes another twist to the request that you hadn’t expected. Multiple users are requesting copies of the same report. And, to make this even worse, these users would like to have the report sent to more than one output queue. This makes your task a little more difficult than simply changing the number-of-copies attribute on the spooled file. Sure, there is an option to have your program create another spooled file with another name and then override this report to another printer. But what do you do if the request is for three reports to be sent to different locations? What about ten different locations? You soon realize that a different approach is needed to solve this problem, yet it must keep your programming and future maintenance of this report program within a reasonable scope.
In this article, I will show you an application that I have written called Duplicate Spooled File (SPL2SPL), which allows you to duplicate a spooled file to up to ten different output queues with one command. I will also show you how to attach a data queue to an output queue to make this duplication process automatic. Think of this as a “trigger” on an output queue.
Step One: Duplication
In breaking down the process of report duplication and distribution, the first logical step is to create an application that will duplicate a spooled file. There is more than one way to perform this task, but I chose to use the spooled file APIs that are included with OS/400. This required more research and programming in the front-end, but, once it was complete, I had the base to duplicate any spooled file I needed to. Also, I was not limited to only SNA Character Stream (SCS) spooled files as I would if I were using the Copy Spooled File (CPYSPLF) command.
Duplicating a spooled file required six different APIs, and three additional APIs were used for user space manipulation. So a total of nine APIs were used for this process. Don’t let this number throw you off. It may sound like a lot of work, but it actually isn’t. Most of the APIs use parameters retrieved by others; so, for the most part, duplication is simply calling one API after another.
The six spooled file APIs used are shown in the S2SP01RG RPG program, which can be downloaded from Midrange Computing at www.midrangecomputing.com/mc. Figure 1 contains a table that shows what each API is used for. This doesn’t go into too much detail, but if you wish to read more on these APIs, they can be found in OS/400 Print APIs V4R4.
The first thing you must do to use the spooled file APIs is create a user space to store the spooled file data you will be retrieving. Next, you retrieve the spooled file attributes of the spooled file you wish to duplicate. The entry parameters to program S2SP01RG contain fields, such as file name, job number, and spooled file number, that allow you to identify the spooled file you wish to duplicate. These parameters are then put into a format that can be used by the Retrieve Spooled File Attributes (QUSRSPLA) API.
After you have the attributes of the spooled file to duplicate, you create a new empty spooled file, which will become the duplicated spooled file. This is done by using the Create Spooled File (QSPCRTSP) API. This API creates a new spooled file, opens the new spooled file, and returns to the calling program a “handle” that is used to identify the new spooled file. The handle is a unique identifier used by the system to identify the spooled file. The attributes returned from the Retrieve Spooled File Attributes API are passed into the Create Spooled File API so that your new spooled file will contain the same attributes as the original. You will see in the source that a couple of the attributes can be changed, such as Output queue, Hold, and Save. The use of these parameters will be explained later.
Next, open the original spooled file using the Open Spooled File (QSPOPNSP) API. This opens the spooled file, just as you would open a database file, making the data contained within available to your program. It also returns a unique handle for the original spooled file, which you can then use to identify this spooled file for most of the remaining API calls.
After the spooled file is open, you can retrieve all of the spooled file data and place it in the user space you created. This is done by using the Get Spooled File Data (QSPGETSP) API. Notice in the S2SP01RG RPG program that you are using the spooled file handle returned from the Open Spooled File API. After calling this API, your user space will contain the data from the original spooled file.
The next step is to place the spooled file data from the user space in the new spooled file you created earlier. This is where the spooled file handle returned from the Create Spooled File API comes in handy. You use it as a parameter on the Put Spooled File Data (QSPPUTSP) API to identify the spooled file that you wish to put the data in. After calling this API, your newly created spooled file will contain a duplicate of the data contained in the original.
Last in this process, you must close the spooled files. The Create Spooled File API not only creates a new spooled file but also opens it. And because you manually opened the original spooled file, you must close this as well. This is done by using the Close Spooled File (QSPCLOSP) API. This API is called twice using the handle of each spooled file to close.
The S2SP01RG RPG program can be used alone to duplicate a spooled file in the same or a different output queue. The Output queue and Output queue library parameters specify the new location for the new spooled file. But, to make this command a little more user-friendly, a command front-end, SPL2SPL, was added.
Step Two: Distribution
I mentioned earlier that not all of the attributes of the original spooled file will be duplicated to the new spooled file. With the SPL2SPL command, I am allowing the user to specify new parameters for the Hold, Save, and Output queue parameters. Hold and Save are self- explanatory, but let’s take a closer look at the Output queue parameter.
Using the SPL2SPL command, a user can either simply duplicate a spooled file using the default parameters or, if the user pressed F10 on the SPL2SPL command, enter up to ten different target output queues where he can place the spooled file. See Figure 2 for an example of what the SPL2SPL command looks like.
You remember that the S2SP01RG RPG program can be used to duplicate a spooled file once. To make up to ten separate copies, the SPL2SPL command, along with the S2SP01CL CL program, is used. The S2SP01CL CL program accepts the data from the SPL2SPL command, reads through the output queues entered, and calls S2SP01RG for each output queue. If the default of *SAME is specified, S2SP01RG is called only once, and a duplicate is placed in the same output queue as the original. But, if the user enters one or more specific output queues on the list, the S2SP01RG program is called once for each output queue specified, passing the output queue value into the program.
This command limits the user to ten output queues. But the command and CL front- end could be easily modified to allow more if you see the need for it.
Step Three: Automation
Now that you have a command that will allow you to duplicate and distribute spooled files, I’d like to show you a brief example of how you can make this process automatic.
One of the parameters on the Create Output Queue (CRTOUTQ) or Change Output Queue (CHGOUTQ) command allows you to specify a data queue to associate with the output queue. When a spooled file enters the *RDY status on an output queue, an entry is added to the data queue. The entry contains information that you can use to decide what you want to do. For example, you could use this method to set up a “trigger” on an output queue to duplicate and/or distribute a spooled file depending on one of the parameters shown in Figure 3. When certain criteria are met, you could call the SPL2SPL command and distribute the report to the output queues that you need.
Entries are read from the data queue by using the Receive Data Queue (QRCVDTAQ) API. When called, this API retrieves and removes an entry from a data queue, making it available to your program for processing. For the format of data returned from a data queue that is attached to an output queue, see OS/400 Printer Device Programming V4R4.
Of course, another option is to simply add a call to the SPL2SPL command after your report program has completed. This would be the simplest and safest method, because using triggers can be dangerous. Be very careful if you are using the data queue method of distribution. Accidentally setting up triggers that are recursive this way may cause a never- ending spooled file duplication process that will be hard to stop.
Putting Automatic Distribution to Work
Sometimes users request something that, although we know it is possible, we may not be familiar with or have the time to work on. Because requests to duplicate and distribute spooled files are common yet require the use of cumbersome APIs, I put together the SPL2SPL command to help those without the time or the resources to accomplish this task.
In putting together this application, I started at the lowest level, developing a procedure that would first duplicate a single spooled file. Then I modified it so that the Output queue, Hold, and Save parameters could be changed for the new spooled file. Next, I created a command that allows the input of up to ten output queues and called the main procedure one time for each output queue specified on the command. Breaking the application down this way made the development much easier than if I were to start with the command. This was good practice in creating functional and modular applications, and it worked out rather well.
I hope you find this application of use. If you haven’t received requests for report distribution yet, chances are one day you will. It may happen when a user gets tired of walking to a particular printer when the report could just as easily be sent to a printer that is closer to him. Or a user may grow weary of photocopying large reports simply because more than one copy is needed. Either way, I think you will find the SPL2SPL command very helpful, whether or not you choose to automate it using data queues.
References and Related Materials
• OS/400 Print APIs V4R4 (SC41-5874-03, CD-ROM QB3AMZ03)
• OS/400 Printer Device Programming V4R4 (SC41-5713-03, CD-ROM QB3AUJ03)
• System API Programming V4R1 (SC41-5800-00, CD-ROM QB3AVC00)
API Name API Description
QUSRSPLA Retrieve Spooled File Attributes QSPCRTSP Create Spooled File
QSPOPNSP Open Spooled File
QSPGETSP Get Spooled File Data QSPPUTSP Put Spooled File Data QSPCLOSP Close Spooled File
Figure 1: These spooled file APIs are used to duplicate a spooled file.
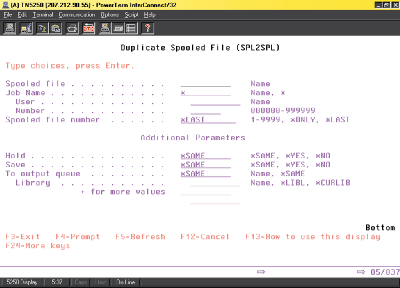
Figure 2: This is an example of the Duplicate Spooled File (SPL2SPL) command.
Function The function that created the data queue entry. The value for spooled files is *SPOOL. Qualified Job Name The qualified job name that created the spooled file that was placed on the output queue. This parameter is in the format Job name, User name, and Job number. Spooled File Name The name of the spooled file placed on the output queue. Spooled File Number The spooled file number of the spooled file placed on the output queue. Qualified Output Queue Name The qualified output queue name of where the spooled file was placed. This parameter is in the format Output queue name and Library of the output queue library.
Figure 3: Parameters are available from data placed on a data queue associated with an output queue.



 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online