
















As artificial intelligence penetrates our daily lives, questions on trust and transparency arise. Without the right tools to manage, detect, and mitigate bias to what extent are we humans prepared to hand over control to AI systems for decision-making and taking actions?
Throughout history, some sectors of society have rejected automation and technology—partly because of the fear of “letting go” control to the machines. Yet if we don’t relinquish some control, we humans become a bottleneck.
Here’s why. Organizations are having to cope with analyzing data volumes that are growing exponentially, yet being under pressure to make decisions and take actions faster and more frequently while minimizing the associated risks. Examples include determining whether a financial transaction is fraudulent or not, deciding whether a loan request should be approved or rejected, predicting a customer’s propensity to buy a particular product, predicting the threat level and impending damage from an approaching storm, and even deciding if an incoming projectile is hostile and whether there is enough time to counter strike or take evasive action. In the case of real-time situations, multiple decisions and actions may need to be processed many times a second.
So, you might ask, what does this have to do with artificial intelligence?
Everything.
Machine learning (ML) is one of the core elements of AI. ML enables a machine to learn from data it encounters so it can recognize patterns and trends in data—and make predictions faster, more often, and more accurately than humans alone, without prejudice, while becoming progressively smarter.
If we humans want to be able to more accurately identify threats and opportunities that might otherwise be missed by the human eye and mind, then we need machines to augment or out-perform the tasks that are constrained by our own human cognitive limitations.
The opportunity lies in combining the capabilities of both humankind intelligence and artificial intelligence and letting each excel at what each can do best.
The question remains: To what extent are we prepared to hand over control to AI systems for decision-making and taking action? High-volume repetitive tasks that AI can learn from with vast quantities of data are clearly candidates. Studying medical images, patient records, and research papers in different languages on a particular disease might also benefit from AI. But would/should we allow an AI system to decide whether to turn off life support for a patient…or decide whether someone is guilty of a crime or not?
This takes us into a whole new realm of ethics and legal discussions that are best discussed in a future article.
Clearly, there are many factors when it comes to trust, such as balance of control, our individual comfort level, ethics, and quality of data. That said, I believe that organizations that embrace AI will outperform those that do not.
Trusting Data Is a Key Foundation of Trusting AI
While some claim that AI can help reduce prejudice and bias, if bad or biased data is used to train a model, then that model might also be biased or not perform well. Biased decision-making by staff is sometimes identified during ML customer engagements—just by looking at the training data being used. There are methods, of course, to identify whether the training data might be biased in the first place by using “validated” sets and “holdout” data sets to check the model’s performance and see if the model behaves as expected before being deployed.
In production, an AI system might make decisions that not everybody agrees with. AI consumers night want to know the reason for a particular outcome on a decision.
“Explainability” is the process of explaining why an AI model behaved in a certain way, such as approving or declining a bank loan. This form of transparency of the decision-making itself helps increase the confidence that AI can be trusted—if it can be investigated.
There have been several attempts to create methods and tools that can detect and observe biases within an algorithm. This emergent field focuses on tools that are typically applied to the data used by the program rather than the algorithm's internal processes. These methods may also analyze a program's output and its usefulness. A new IEEE standard is being drafted that aims to specify methodologies to help creators of algorithms eliminate issues of bias and articulate transparency (e.g., to authorities or end users) about the function and possible effects of their algorithms. The project was approved in February 2017. More information is available at https://standards.ieee.org/project/7003.html.
For AI to thrive and for businesses to reap its benefits, executives need to trust their AI systems. They need capabilities to manage those systems and to detect and mitigate bias. It’s critical—oftentimes a legal imperative—that transparency is brought into AI decision-making. In the insurance industry, for example, claims adjusters may need to explain to a customer why their auto claim was rejected by an automated processing system.
It’s time to start breaking open the black box of AI to give organizations confidence in their abilities to both manage those systems and explain how decisions are being made.
IBM recently announced its “Trust and Transparency” capabilities for AI on the IBM Cloud. Built with technology from IBM Research, these capabilities help provide visibility into how AI is making decisions and give recommendations on how to mitigate any potentially damaging bias. It features a visually clear dashboard that assists line-of-business (LOB) users to better understand these issues, reducing the burden of accountability for data scientists and empowering business users.
A Look at Trust and Explainability in Action
The goal should be to empower businesses to infuse their AI with trust and transparency, thus building confidence to deploy AI systems in production.
Trust and transparency capabilities for AI on the IBM Cloud are intended to support models built in any IDE or with popular, open-source ML frameworks. Once deployed, those models can be monitored and managed by capabilities at runtime, while the AI decisions are being made.
So, let’s say you build and deploy a system of models supporting an API your business can call whenever you need a prediction. These capabilities can hook into those models and help instrument a layer that enables organizations to capture the input the models receive and the output the models produce.
These capabilities can help provide a level of transparency, auditability, and explainability by logging every individual transaction throughout a model’s operational life. The lineage of these models is presented to business users at runtime in a way that’s easy to understand, something that’s unattainable with most of the tools available today.
Fairness is a key concern among enterprises deploying AI into apps that make decisions based on user information. The reputational damage and legal impact resulting from demonstrated bias against any group of users can be seriously detrimental to businesses. AI models are only as good as the data used to train them, and developing a representative, effective training dataset is very challenging.
In addition, even if such biases are identified during training, the model may still exhibit bias in runtime. This can result from incongruities in optimization caused by assignment of different weights to different features.
As they log each transaction, the trust and transparency capabilities feed inputs and outputs into a battery of state-of-the-art bias-checking algorithms to track bias in runtime. If bias is detected, the capabilities can help provide bias mitigation recommendations in the form of corrective data, which can be used to incrementally retrain the model for redeployment.
The problem of bias detection can be addressed by automatically analyzing transactions within adaptable bias thresholds, while values of other attributes remain exactly the same. Traditional methods of measuring bias at build time require techniques that are computationally prohibitive at runtime for a complex AI system.
These capabilities incorporate novel techniques that help automatically synthesize data in order to compute bias on a continuous basis. These techniques combine symbolic execution with local explainability for generations of effective test cases to create highly flexible, efficient, and comprehensive bias detection capabilities, as shown in Figure 1 below.
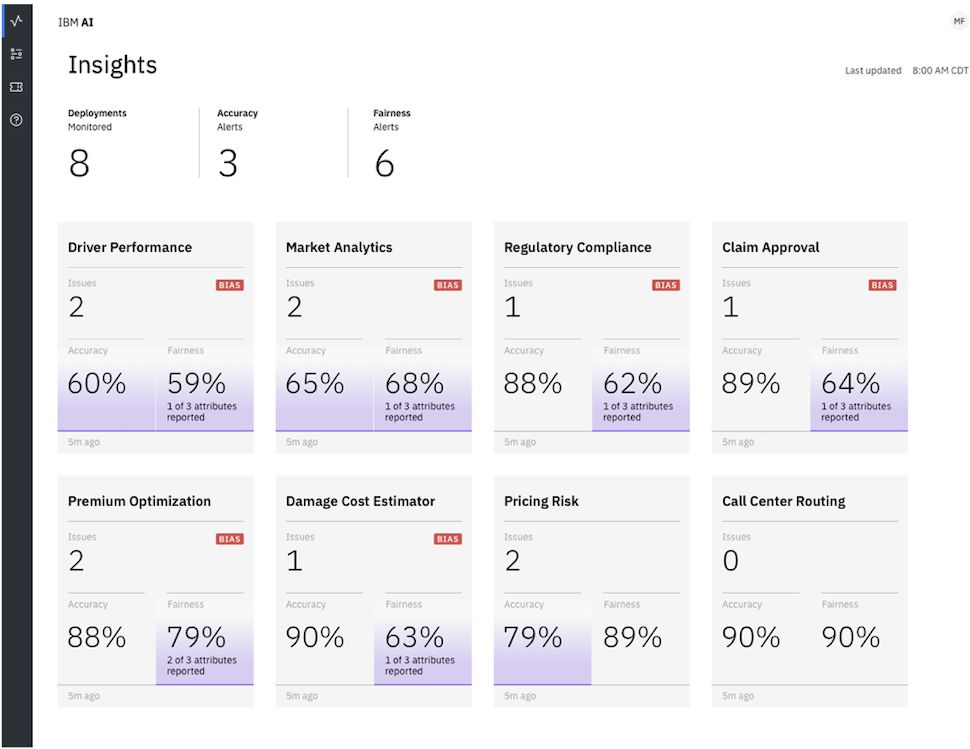
Figure 1: Comprehensive bias detection at run time
Trust and transparency capabilities can help bridge the gap between data scientists, developers, and business users within an organization, providing them visibility into what’s happening in their AI systems.
Through intuitive visual dashboards, businesses can access easy-to-understand explanations of transactions. They can simply type a transaction ID, which can be passed down from an application into the user interface, to get details about the features used to make a decision, the limits, the inputs passed, and most importantly, the confidence level of each factor contributing to the decision the AI helped make.
Thus, even though the business-process owners might have minimal understanding of how the model works, they can still gain insight into the decision-making process and can easily compare the model’s performance against a human decision. As a result, they can make decisions about AI model health and recognize when the system might need help from data scientists.
Through these capabilities, data scientists and developers can obtain insights into near real-time performance of their models, which can also be measured and better understood by business users. This insight helps provide visibility into whether models are making biased decisions and the effect of those decisions on the enterprise. It also includes the corrective feedback data scientists can incorporate into their models to address biased behavior. IBM’s Trust and Transparency capabilities are intended to help users understand the decisions their AI models are making during run time, something that was not previously available.
Trust Will Grow Over Time
If AI is truly going to augment operational decision-making, it’s critical to make AI outcomes transparent and explainable—not only to data science teams, but also to the line-of-business user responsible for those decisions.
Once one organization demonstrates competitive advantage over its industry peers, it doesn’t take long for others to follow—in fear of being left behind. Typically, as adoption increases, the associated misconceptions of trust will lower, paving the way for others to adopt with less fear and suspicion.
The potential that AI offers outweighs any negative perceptions in my opinion. Opportunity to unravel the mysteries of life itself, the world in which we live, and worlds we have yet to discover grow ever closer. The way we farm, work, think, eat, approach medicine, defend and protect our freedoms, and understand our world could change dramatically and for the better as we each embrace our individual AI journeys.
If you are interested in this and other aspects of AI, the book Artificial Intelligence: Evolution and Revolution helps provide a more comprehensive discussion.
References
“Explainability/Trust and Transparency Capabilities”: https://www.ibm.com/blogs/watson/2018/09/trust-transparency-ai/
“Ethically Speaking”: https://medium.com/inside-machine-learning/artificial-intelligence-ethically-speaking-a35174e561d6

Mark Simmonds is a Program Director in IBM Data and AI communications. He writes extensively on machine learning and data science, holding a number of author recognition awards. He previously worked as an IT architect, leading complex infrastructure design projects. He is a member of the British Computer Society and holds a Bachelor’s Degree in Computer Science.
MC Press books written by Mark Simmonds available now on the MC Press Bookstore.
 |
Artificial Intelligence: Evolution and Revolution Get started on your AI journey with insights for a path to success. List Price $19.95 Now On Sale
|




 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online