















The need to protect data and ensure its availability under all circumstances has businesses and organizations of all sizes exploring a variety of backup and recovery strategies. One of the most effective strategies is to implement high availability (HA) software. Very simply, HA software replicates entire applications and databases to one or more additional live environments, and then keeps the environments synchronized as data changes occur in the production environment. This replicated, synchronized data can then be quickly retrieved to recover the system in the event of a failure or disaster, or it can be directly accessed by users and processes during scheduled or unscheduled downtime events.
The Components of High Availability Software
Let's take a quick look at the basics of HA solutions:
System-to-System Communications
To start, communication needs to be established between your production and your backup iSeries machine(s). Typically, TCP/IP is the best way for two iSeries machines to communicate with each other, particularly with HA software. Machines can be located in the same computer room and connected by high-speed line (HSL), or the backup machine can be located in another building or, ideally, in another city for optimum disaster recovery capabilities. With communications, the challenge is determining the amount of bandwidth needed to handle the volume of data to be regularly replicated and the distance that the data is to be transmitted. Of course, the more bandwidth needed, the more it costs.
Data Replication Engine
A core HA component is an engine that replicates transactions and their changes between the production (source) and the backup (target) machines in real time. In iSeries HA solutions, all replication engines for databases use OS/400 journaling to monitor for changes. This journaled data is sent to the backup and applied to copies of the objects to keep them synchronized with the production environment. The process of extracting data change information from the journal entry is called "harvesting," and all HA software products use this process. A primary difference among HA solutions is whether harvesting occurs on the production system or the backup system. HA solutions that harvest from the production system use their own proprietary "harvest-and-send" process. HA solutions that harvest from the backup system use OS/400 remote journaling functions, which also take care of transmitting journal entries to the backup.
Let's take a closer look at the pros and cons of the "harvest-and-send" and remote journaling data replication methods:
"Harvest-and-Send"--In this method, the HA software harvests information from journal entries on the production system and then transmits that information to the backup system with its own data transmission process. Once the data changes reach the backup, the HA software synchronizes the objects.
Remote Journaling--In this method, as changes are made to application data files on the production system, journaling detects these changes and sends copies of the journal entries to an identical journal receiver on the backup system. Once the journal entry lands on the backup, the HA software harvests the journal information and applies the changes, thus synchronizing the data.
Remote journaling typically offers many advantages over harvest-and-send. The biggest is that it creates very little overhead on the production machine because remote journaling sends copies of journal entries to the backup system via the operating system; therefore, data is extracted from journal entries on the production system. The remote journaling process also puts data changes on the wire very quickly because it works at the level of the operating system, beneath the machine interface (MI).
In contrast, harvest-and-send extracts data from journal entries on the production system as well as uses its own process to transmit the journal information, all of which happens on top of the operating system. This activity creates a significant amount of overhead on the production system, thus competing with applications for processor time.
Sometimes, production-side "harvest-and-send" has benefit, since this kind of process filters the harvested data and removes extraneous information prior to transmission, which can reduce the amount of bandwidth needed. With remote journaling, most changes to mirrored files are transmitted to the backup system; however, since the remote journaling process transmits data quickly and efficiently, this disadvantage is often not an issue. Additionally, by using the journal-minimal-data function, you can reduce the amount of data sent by remote journaling, further reversing any disadvantage.
Another advantage of remote journaling is that data can be replicated between systems either synchronously or asynchronously. In synchronous mode, the program waits for acknowledgement from the backup before continuing. This is often a requirement for financial companies. The downside is that it will slow system response time unless a fast machine and sufficient bandwidth are in place. When data is sent asynchronously, programs will continue without waiting for acknowledgement that journal entries have been received on the backup. Asynchronous data transmission is usually acceptable for most companies.
For detailed information on remote journaling in HA solutions, see the IBM Redbook Striving for Optimal Journal Performance on DB2 Universal Database for iSeries at www.ibm.com/redbooks. Keep in mind that HA software must be able to keep all system-critical objects updated on the backup system, not just data files. Journaling, however, only accommodates data files, IFS, data areas, and data queues; therefore, program objects, spool files, user profiles, device configurations, etc. are typically replicated using proprietary object-monitor-and-copy processes.
System Monitor
Once a data replication process is in place, it needs to be continuously monitored, as thousands or even millions of transactions may be replicated each hour. If there is a glitch in communications, journaling components, or journal-entry-apply processes, objects can easily lose synchronization, jeopardizing data integrity on the backup. Monitoring, therefore, is critical. If any problem arises, it should appear on monitoring screens, and the HA software should automatically attempt to correct the problem. For instance, if the monitor finds an object on the backup that is out of synchronization, the HA software should automatically resynchronize the object without halting or slowing the ongoing replication of other objects or interfering with production-side applications.
Several HA vendors have graphical OS-independent (Java) monitors that can run on any platform and even monitor HA activity on multiple platforms if cross-platform HA solutions are in place.
Role Swap/Failover
The process of moving users to a backup system is called a "role swap" or "switchover" because the backup system essentially takes the role of the production system when the production system is down--due to either planned or unplanned causes. When a role swap occurs as the result of a system failure, it is called a "failover."
Once you have the components of data replication and system monitoring in place, it is vital that you regularly test the role-swap process (ideally, monthly) to ensure smooth execution and data integrity.
The role-swap process should automatically activate many of the components needed for the backup system to assume the role of the production system. This includes system addressing, as well as HA replication and job monitoring. If the process has been fine-tuned, users should only have to wait a few minutes before a new sign-on screen appears. If clustering is enabled and integrated into the solution, users may not have to wait at all. More on clustering shortly.
When you are ready to return to the production system, you will need to repeat the role swap, which is referred to as a "rollback."
HA Topologies
Let's look at some of the ways that HA technology can be put to use.
Single-System
The most fundamental benefit of HA software, in addition to the ability to recover data in the event of a disaster, is the elimination of downtime for daily and system backups. The simplest HA topology is single-system replication, which replicates essential data into a second environment within a separate partition on the same machine. Very often, single-system replication is implemented to perform tape saves from the backup environment. This function alone can eliminate hundreds of hours of downtime each year.
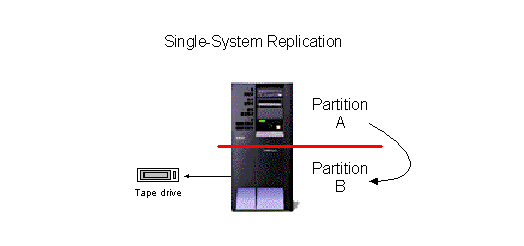
Figure 1: Single-system replication is the simplest HA topology. (Click images to enlarge.)
One-to-One
HA software is commonly used to replicate essential data to a second backup iSeries. The second machine doesn't need to be a dedicated backup machine; it could be a development machine or another machine handling workloads. In all but single-system configurations, HA can provide a significant performance benefit by moving non-update workloads--such as reports and queries--to the backup.

Figure 2: One-to-one replication allows you to replicate essential data to a second machine.
Keep in mind that if you intend to move all users and processes to the backup machine during a role swap or failover, the machine must have sufficient horsepower to accommodate this workload. If you only want to move essential users and processes, or simply use the backup as a disaster recovery environment to more quickly restore data, a smaller machine is sufficient. As mentioned earlier, to realize full disaster recovery benefits, the backup machine should be located offsite--ideally in a different city or even different part of the country. FYI: There are companies that will lease you space on an iSeries for this purpose.
Bi-directional
If you are using your backup machine for other workloads (like development), you may also want to protect that data through replication. In this case, you would set up a bi-directional HA topology in which each environment is replicated to the other machine. Typically, you would want to have a partition on each machine that acts as the backup environment.

Figure 3: With a bi-directional system, each environment replicates to the other.
Many-to-One
In a many-to-one or hub-type configuration, shops that have several iSeries sites can replicate all sites to individual partitions on a larger machine. For example, a company with many satellite offices would replicate critical data from branches to a machine located at the central office via the Internet.

Figure 4: With many-to-one replication, remote sites replicate to one central machine.
One-to-Many (Broadcast)
Some companies need to replicate simultaneously to multiple backup sites for a variety of purposes: to add an additional layer of protection, to create data warehouses, to migrate to a new machine, etc. Keep in mind, some additional overhead is created on your production machine for each additional backup environment, although this can be offset by moving read-only workloads to a backup environment.

Figure 5: With one-to-many, you can replicate simultaneously to multiple backup sites.
Cascade
For shops that have multiple iSeries, several HA solutions can be configured to replicate from one to another in a "cascade" topology. In other words, machine A replicates to machine B, machine B replicates to machine C, etc. Typically, this topology is used to broadcast to multiple machines, but without loading the production machine with all of the overhead. For instance, if the intent is to replicate for both disaster recovery and data warehousing purposes, a shop may replicate first to the backup machine and then have the backup machine replicate necessary data to the data warehouse machine.
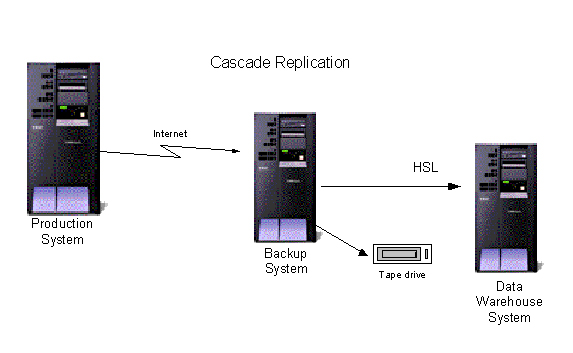
Figure 6: Cascade replication allows you to replicate from one machine to another to another....
Cluster
IBM defines a cluster as "a configuration or a group of independent servers that appear on a network as a single machine." When a cluster is defined in Cluster Resource Services of OS/400, all resources defined in the cluster can more easily be shared to distribute workloads and can be managed from a single workstation. When HA middleware is integrated with clustering, enhanced automated switching of resources can occur in the event of an iSeries server failure.

Figure 7: A cluster allows for enhanced automated switching of resources.
Clustering requires multiple machines to have HA middleware installed and to be connected and then identified as part of a cluster in OS/400. In addition, the business applications that are being replicated must typically be designed to take advantage of clustering. When properly configured, systems have an additional advantage of automatically detecting node failures and executing self-correcting actions, particularly the initiation of a failover with another designated node. The cluster-enabled HA software can even track where users and processes were within an application, potentially allowing users to pick up a transaction on the very screen they were on when the failure occurred. Very often, users don't even know there was a failure. Despite how good all of this sounds, keep in mind that clustering takes a significant amount of time and training to properly configure.
IASPs (Switched Disks)
Independent auxiliary storage pools (IASPs) are external disk towers that are connected to two or more servers, with application data residing on the disk tower. If the primary server fails (or is taken offline for maintenance), the IASP (and the applications therein) can be switched to the other server, and work resumes once workstations and other devices are redirected to this backup server. HA software isn't required in this configuration, but it is useful for replicating non-data objects such as user profiles, configuration files, and other system objects that cannot reside on the common IASP. This ensures that all the necessary systems objects are available. HA software can also be used to manage the switching of the IASP to the backup server, and if configured as part of a cluster, failover switching can occur quickly and automatically. Keep in mind that IASPs must be located close to the connected servers.

Figure 8: IASPs are external disk towers that are connected to two or more servers.
This topology minimizes the DASD normally required for HA because only one set of data is needed; however, if a critical disk in the IASP fails, data could be unrecoverable (although disks could be mirrored). Additionally, backups cannot be performed on the IASP without restricting users during the process. The IASP is sometimes chosen because it is typically easier to manage and is less costly than full cross-server replication while still providing protection from server failures.
Finally, IASPs can be included in HA clusters to provide a more flexible and redundant means of moving users, devices, and processes in the event of a failure.
Storage Area Network (SAN)
In environments with extremely large data storage requirements, a dedicated high-capacity storage device called a storage area network (SAN) is often implemented. In this scenario, a redundant SAN can be attached to an HA backup server. The two manufacturers of SANs for iSeries servers (IBM and EMC) sell technology that allows ongoing replication of specified applications (residing on defined logical volumes) from one fiber-connected SAN to another.

Figure 9: SANs are useful if you have large data storage requirements.
IBM's SAN device is called Enterprise Storage Server (ESS, aka "Shark"), while EMC's version is called Symetrix. Each uses proprietary technology to continuously mirror the logical volume(s) to the backup SAN. IBM's mirroring technology is called Peer-to-Peer Remote Copy (PPRC); EMC's is called Symetrix Remote Data Facility (SRDF). This mirroring typically runs synchronously over distances of less than 100 km and asynchronously over longer distances. This technology can even be used for role swap or failover without HA software.
HA software adds value in this topology when all or part of the data that is being disk-mirrored by PPRC or SRDF is replicated to another set of disks on the backup SAN. This redundant backup provides two benefits: First, at designated points, HA replication can be paused, and transactions can be completed in order to get a tape save without downtime; second, the redundant data replica can be used as a second recovery resource in case the first resource has been damaged or corrupted.
Each SAN uses proprietary technology to quickly make the initial copy of the data for HA replication. IBM's is called FlashCopy, and EMC's is TimeFinder. An additional benefit of this quick-copy technology is that it executes rapid resynchronization of large objects when needed. Keep in mind that this configuration can also be used in a cluster environment.
Integrated Windows Servers
There are many advantages to integrating Windows servers with iSeries, either through internal xSeries IXS servers or externally connected xSeries servers. The largest advantage with either is that data is stored on iSeries DASD, making it easier to manage and back up. Most iSeries HA software replicates IFS, but in order to make sure Windows environments can fully role swap and failover, matching integrated Windows servers need to be attached to the backup iSeries, and HA software for Windows must be running. Many HA vendors also sell Windows HA software, which usually integrates with the HA monitor that manages iSeries replication.
With replication of Windows objects, it is important that only the changed portion of the data is replicated (rather than entire objects) to reduce bandwidth requirements.

Figure 10: Use xSeries Windows servers in an iSeries replication topology.
Supporting Replication of All Data
As mentioned, in addition to data files and program objects, HA software needs to replicate all critical objects, including spool files, device configurations, data queues, data areas, and scheduled jobs.
IFS
Replication of IFS can be especially critical. As with Windows servers, to maximize performance and minimize bandwidth requirements, only the actual changes to IFS objects should be replicated, rather than entire objects.
MQ Series
If your applications use MQ Series, it is vital that the HA software properly manages the replication of MQ Series messages and environments. Since MQ Series uses journaling, the MQ Series messaging events can be replicated to the backup, but what is most critical is the management of the MQ Series environments on each system.
Domino
With Domino environments on your iSeries, HA is executed exclusively through iSeries clustering, which not only does the replication of data, but also handles all failover and role swap functions.
Linux
Replication and switching of Linux environments on iSeries is handled much like integrated Windows environments. You will need to purchase a separate Linux-specific HA solution and manage it separately, although some iSeries HA vendors are now beginning to sell Linux solutions and incorporate them in their cross-platform HA monitors.
Keep in mind that Linux partitions can be defined in an IASP switched disk, which can then be switched to another iSeries server if the primary server fails.
High Availability "Lite"?
Some iSeries HA vendors offer intermediate disaster recovery solutions that fall somewhere between tape saves and HA software. These products increase point-of-failure data recovery far beyond the recovery point from tape backups, although there is no role swap capability.
Currently, two intermediate solutions exist:
- GuardianSave, by iTera, Inc., transmits copies of journal receivers to any IP-connected device, whether it's an iSeries server or another computing resource. When recovering from a failure, the latest tape save is restored, and the journal receivers that were transmitted are automatically retrieved and applied to bring the data to its state as of the last time journal receivers were changed and transmitted.
- Mimix DR1 by Lakeview Technologies takes "snapshots" of critical data and transmits them to another connected iSeries without journaling. When data needs to be recovered, the entire snapshot is retrieved and applied, bringing data to its state as of the time of the last snapshot.
High Availability Vendors
iSeries
•DataMirror
• iTera, Inc.
• Lakeview Technology
• Maximum Availability
• Vision Solutions
Windows Servers
•iTera, Inc.
• Lakeview Technology
• NSI Sofware
• Vision Solutions
Linux
•H.A. Technical Solutions
• High-Availability
• Radiant Data
• Steel Eye Technologies
What Are You Waiting For?
In today's world of ever-expanding hours of business operation and increasing reliance on data availability, it is becoming easier for companies of all sizes to cost-justify HA. Keep in mind that the total cost of ownership for HA is not cheap. In addition to the expense of redundant servers, bandwidth, software, installation, and maintenance, you also need to consider the time it takes to manage the system. The good news is that many of these costs have dropped in recent years, making HA cost-justifiable for even small companies.
One parting caveat: Depending on the size and complexity of your IT department, there are many factors to consider besides HA software when working to reduce vulnerability to planned and unplanned downtime. HA is clearly a significant component in an overall data recovery/system availability strategy, but it often takes a variety of software and hardware components to provide maximum protection against all exposures to downtime.
Bill Rice is a freelance technology writer and a marketing consultant for iTera, Inc., an iSeries high availability software vendor. He can be contacted at




 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online