















An approach to meeting the demands of a 24/7 availability environment and reducing the risk of downtime events.
Editor's Note: This article is an extract of the white paper "How to Achieve High Availability with System Management in Five Simple Steps" available free from the MC White Paper Center.
A hard-working System i environment is never more visible (or expensive) to an organization than when it becomes unavailable. The expectation is for optimal performance on a 24/7 basis, and beyond that, any system issues should be the remit of the IT manager—not seen, not heard, and most definitely not felt by the user community. Sadly, the realities of system availability can fall short of these exacting standards—whether the systems are truly available or not. This is because the definition of high availability means different things to different groups within an organization.
Some may say that unless a system fails, it is, technically speaking, still available. In the real world, however, these technical definitions will be of little persuasion to the user who is unable to access an application because a TCP port has stopped listening or others who are experiencing poor response times due to the "lack of availability." Similarly, when a system performs below agreed SLA standards but does not necessarily fail altogether, then the financial penalties will resonate louder than any justification. Creating a high availability environment must account for all definitions and perceptions. In short, when it comes to high availability, the system must be all things to all people at all times.
(Click image to enlarge.)
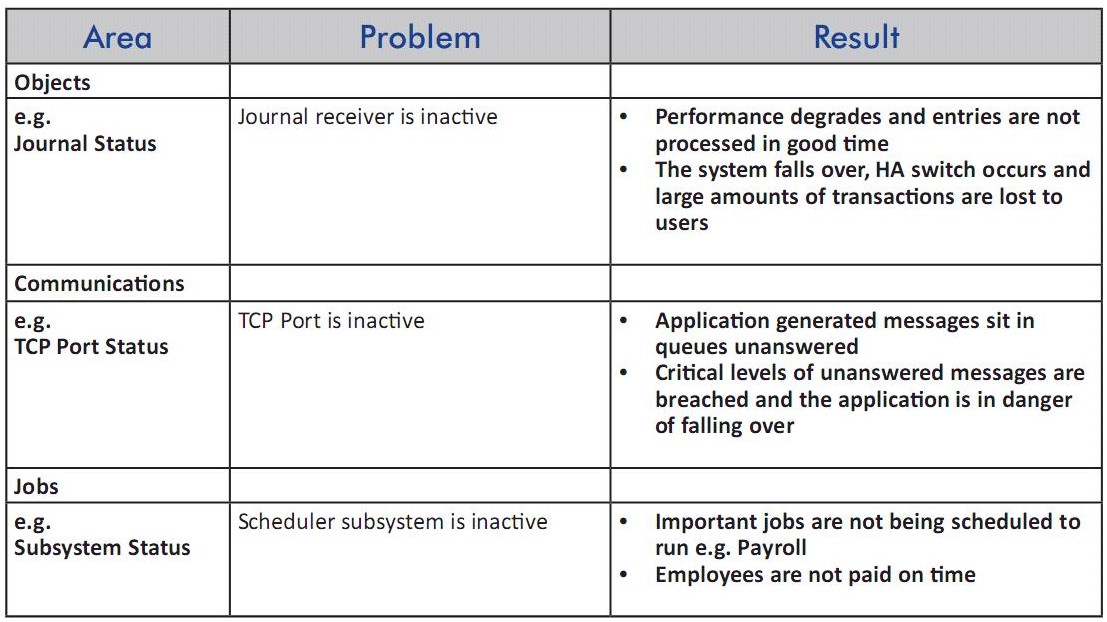
Identify Threats to Availability
Identifying the threats to availability will require both a historical knowledge of past events—for example, those leading to a specific downtime incidence—and also an examination of the lines of dependence that stretch from the user group back to the system. In some cases, these can also include dedicated high availability (HA) solutions or other resources used for disaster recovery. Analysis of all these links between the system and the people who rely on it can help to determine potential areas of vulnerability where adverse conditions could not only impact availability, but also create serious secondary issues on the system.
Applications, jobs, subsystems, and communication elements can all give rise to potential availability issues, and as such, these key areas should be identified and monitored in real time for abnormal status or performance conditions. The chart below looks at how some of these system elements could transform into availability issues and what their impact could mean for the organization experiencing them.
Want to learn more? Download the complete white paper "How to Achieve High Availability with System Management in Five Simple Steps" from the MC White Paper Center.
as/400, os/400, iseries, system i, i5/os, ibm i, power systems, 6.1, 7.1, V7, V6R1




 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online