















A well-designed, well-implemented set of HA and DR technologies will protect an organization against equipment failures, utility interruptions, and natural disasters.
Editor's Note: This article is based on "Next-Generation Disaster Recovery and Availability Technologies for IBM Power Systems," a free white paper downloadable from the MC Press White Paper Center.
The High Availability/Disaster Recovery solution spectrum requires that you consider a technology's ability to protect data and keep operations online or bring them back online quickly. Each class of HA/DR technology exhibits different operating characteristics, providing a distinct range of data protection and downtime avoidance.
This article highlights different options available for IBM i and AIX environments, including the latest next-generation solutions. To evaluate and adopt those most effective and appropriate for your organization, you should perform these steps:
- Determine your organization's full range of HA and DR requirements. Issues such as regulatory compliance must be addressed in addition to general business operation needs.
- Evaluate the value of data and application availability for your organization. Can your business afford weekend and evening maintenance shutdowns?
- Review all HA/DR technologies on the market and then select those that meet your requirements and offer a competitive advantage.
The HA/DR Technology Spectrum
The most basic DR strategy requires you to store tape backups of critical data offsite in a secure location, but with this method, you can recover only those data updates applied up to the last save. If you save data to tape once each day, your data recovery point can be as much as 24 hours before the loss of the system. Another problem is the time required to recover from tape, which can range from multiple hours to multiple days.
At the opposite end of the spectrum is "clustering," which includes functionality that runs on the target (backup) system and monitors the availability of the source (primary or production) system. If a problem occurs on the source, the clustering software prompts an operator to initiate a switchover, or it can failover automatically, eliminating human response times. Hosting the target system in a different location further reduces risks.
Comparing all the HA and DR technologies can be simplified. Any HA or DR technology can be compared to others by looking at the time it takes to recover when using the technology and the state or condition to which recovery is possible. In other words, for each technology, the Recovery Time Objective (RTO) describes the goal for how quickly data will be recovered and made available to users after system failure or loss. Similarly, the Recovery Point Objective (RPO) measures the completeness of the data and/or application functionality ultimately recovered.
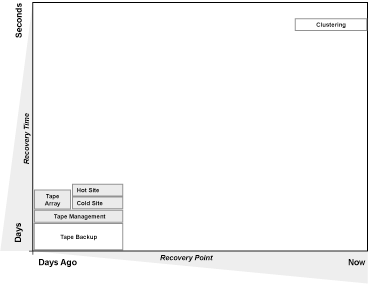
Figure 1: DR and HA technology options can be charted in an "RTO/RPO space" for quick comparison.
Another way to look at this tradeoff is to visualize the "coverage gap" inherent in each technology. Both downtime and data loss have a cost. No HA or DR technology is absolutely perfect. Each always requires some time to recover and has some limit to how complete the recovered data will be. Thus, there will always be potential for some downtime and some data loss: the coverage gap.
For comparison, the following diagram shows the coverage gaps that can be expected from the technologies shown at the two ends of the spectrum charted in Figure 1. The left-hand bar shows the data protection offered (RPO) while the right-hand bar shows the recovery capability (RTO.) In between is the coverage gap, the net tradeoff of potential lost data and downtime. The bigger the gap, the bigger the potential cost. Of course, closing the gap requires more-capable technology, which in turn requires greater investment.

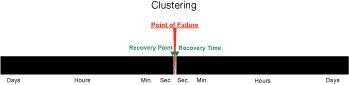
Figure 2: Your recovery gap depends on your HA/DR solution.
Single-System DR Solutions
Companies with a single Power Systems server have limited options for improving their RPO and RTO. Still, single-system solutions might be adequate to achieve an organization's RPO and RTO requirements. Storing data to tape forms the basis of single-system DR solutions. However, because of the time it takes to recover data from tape and help prevent gaps in the recovered data set, tape saves are augmented in several ways:
Tape Management Solutions
Various third-party solutions can help IT personnel better manage tape backup tasks so that the appropriate tapes can be located and loaded more quickly to improve recovery times and reduce the likelihood of errors.
Tape Arrays/Libraries
Employing an array of tape drives (i.e., tape libraries that can run multiple drives in parallel) reduces the amount of downtime caused by the tape-save process and shrinks the time it takes to restore data.
Cold Sites/Hot Sites
Many companies subscribe to a service that quickly accesses a similarly configured system at a protected site. These subscription plans typically offer either a cold or hot site:
- A cold site provides a basic computer room and telecommunication facilities. When a disaster or system failure occurs, the customer replaces the machine. Data and application code are then restored on the new hardware from the backup tapes.
- A hot site provides a system capable of running the customer's operations preconfigured and ready to go when a disaster is "declared."
Multi-System DR and HA Solutions
The second category of DR solutions increases resiliency by using one or more Power Systems servers. With these technologies, a second machine keeps a near real-time copy of critical data and objects, letting you recover transactions occurring just before the failure and providing a quicker recovery time.
When recovery time nears zero and the recovery point is at or near the point of failure, operations continue despite the disaster by switching to an unaffected system.
Replication
A variety of technologies maintain a continuously updated, duplicate image of application data and other critical system objects on a second server or storage environment. These solutions are referred to as "logical data replication" or just "replication."
Data and object replication are performed either synchronously or asynchronously. In synchronous replication, the application is paused until the replication process receives a message that the transmitted data change has occurred. In asynchronous replication, data changes are queued if the transmission, receive, and/or apply process falls behind, which allows the originating process to continue.
LPAR
Logical partitioning (LPAR) is virtualization technology provided by IBM i and AIX operating systems that lets you run more than one instance of these platforms on a single Power Systems server. When LPAR is implemented, a single system can adopt some multi-system characteristics. However, because all the data is on one physical storage device and server, most of the protection multi-server HA offers is not provided.
Managed Journal/Log Recovery
When relying on a combination of tape backups and journal or log entries to restore a system, onsite expertise and manual operations can delay recovery times. However, journaling or logging can reduce the recovery point close to--or possibly right up to--the point of failure in the event of single-point failures. Managed journal recovery sends journal entries offsite to another server at frequent, regular intervals.
Logical Data Replication Plus Switchover/Failover
Logical data replication, coupled with rapid switchover or failover to the backup environment, is really HA. Switchover quickly moves users and processes to a fully functioning, fully synchronized backup system during periods of planned maintenance, thus reducing or even eliminating downtime. Failover is essentially the same process, but it's executed after a system failure or site disaster.
Clustering and Clustered Applications
The IBM i and AIX operating systems use clustering to tightly integrate multiple servers so they essentially work as one but with multiple points of function.
Clustering provides extreme high availability by using shared disk pools, sometimes called Independent Auxiliary Storage Pools (IASPs). Two or more servers are connected to the IASP, but only one controls the disk at any time. An entire application typically resides on the connected IASP rather than on the internal Power Systems disk.
The IASP can be logically disconnected from one server and quickly connected to the other. Should the production server fail, the second server can rapidly access the application while the primary server is repaired or replaced.
Cluster-Enabled Applications
The most aggressive, stringent recovery time and recovery point objectives, ranging from minutes to seconds or even sub-second recovery, can be achieved with cluster-enabled applications. With this capability, software hooks (APIs) are built into the application so that the application communicates intelligently with the clustering technologies of the operating system and the HA solution.
With cluster-enabled applications, users can potentially be presented with the partially completed transaction they had been working with--and so quickly that they may not even be aware that a failover to another server in the cluster has occurred.
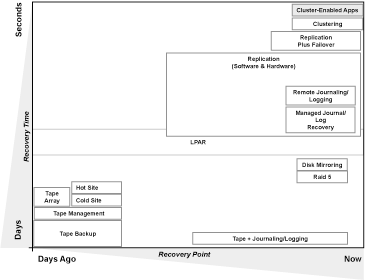
Figure 3: The HA/DR technology space offers a variety of options.
Toward Business Continuity
A wide variety of technologies can improve data recovery time and the amount of data that can be recovered in the event of a system failure or site loss. Yet no single solution can provide the answer for an organization's business continuity; sometimes you must balance, blend, and even compromise between these technologies.
You also must consider many other factors that can affect business continuity, such as data security, platform and application integration, Web- and EDI-interfaced environments, communications reliability, peripheral redundancy, and so on. A well-designed, well-implemented set of HA and DR technologies will extend protection against any threats and protect an organization against the costly business impacts of equipment failures, utility interruptions, and natural disasters.
To find out more about HA/DR solution options, download the free white paper "Next-Generation Disaster Recovery and Availability Technologies for IBM Power Systems" from the MC Press White Paper Center.




 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online