















Virtualization has multiple meanings and purposes. Learn how you can use it to increase data and application availability.
Virtualization can serve a number of valuable purposes in IT departments, but exactly what is virtualization?
There are at least two definitions of the term. Server virtualization allows multiple logical servers--possibly using different operating systems--to run on a single physical machine. On IBM Power Systems, server virtualization services are provided primarily through PowerVM. Its hypervisor can run multiple instances of IBM i, AIX, and Linux in separate partitions on a single physical system.
The PowerVM hypervisor is a "type 1" hypervisor, meaning that it runs directly on the hardware. This makes it more efficient than type 2 hypervisors, which run under another operating system.
The hypervisor isolates the operation of the various virtual server partitions. As a result, if one partition crashes, the others are unaffected.
The Micro-Partitioning feature of PowerVM allocates resources, including fractional portions of processors, among partitions, allowing up to 10 partitions for each processor core. Thus, for example, a four-core system can run up to 40 partitions, and an IBM Power 570 with 16 installed processors can run as many as 160 separate virtual server partitions.
The other definition of virtualization refers to resource virtualization, which either amalgamates or subdivides resources, such as storage, and makes them available to physical or logical servers as if they were the servers' dedicated resources.
There are a few technologies that can be used to virtualize storage. For example, an Independent Auxiliary Storage Pool (IASP) is a collection of disks that allows you to "vary on" or "vary off" systems independent of any other storage attached to a system. Thus, an IASP can be switched between servers if necessary.
Storage Area Networks (SANs) are another common way of virtualizing storage. A SAN amalgamates a collection of storage devices, often of different types and from different vendors, and presents them to one or more systems as a single data store that appears to the user to be homogeneous. This collection of disks may be spread over a large geographical area using a Wide Area Network (WAN).
Both types of virtualization--server virtualization and resource virtualization--can be used to increase the availability of data and applications.
HA Defined
This article assumes the broadest possible definition of HA. This includes the avoidance of downtime due to unplanned events--disasters, hardware failures, power outages, etc.--as well as due to planned events such as system maintenance. In this context, the nature of the downtime or the reason for it is irrelevant. System and data are available or not; the reasons are immaterial from the perspective of business continuity.
HA and disaster recovery (DR) are often discussed together, but there is a critical difference. In a DR scenario, systems must be recovered from an offline source, typically tape or possibly a disk-based data store. By definition, disaster recovery requires some downtime.
The efficiency and effectiveness of disaster recovery solutions are measured by two variables:
- Recovery time: How quickly can you restore operations after a disaster?
- Recovery point: How much recent data might you lose due to a disaster?
HA differs from DR in that HA strives to eliminate the need for any recovery--i.e., it attempts to achieve instantaneous recovery and no lost data. It does this by maintaining redundant hardware, software, and data. When implemented comprehensively and well, if the primary system becomes unavailable or the primary data store is destroyed, a hot-standby backup system and data can take over almost immediately.
Clearly, achieving a high level of availability requires planning, processes, and vigilance, but from a technology perspective, comprehensive HA demands three things: redundancy, geographic separation, and the ability to switch rapidly, and preferably transparently, between redundant components when the need arises.
The word "comprehensive" is relevant because an organization that can afford some downtime in the event of a disaster may opt for a less-than-complete HA solution, as described in the next section. If so, the "geographic separation" factor in the above formula may not be required in an HA solution, although backup tapes will still need to be shipped offsite to protect them from destruction should a disaster occur.
HA implies redundancy, but it is possible to virtualize some of that redundancy and thereby eliminate the cost of duplicate hardware.
Because virtualization allows you to run multiple virtual servers on a single physical system, your production and backup servers do not have to be on separate physical systems. As depicted in Figure 1, HA software can replicate production data onto disks attached to a backup virtual server on the same system.
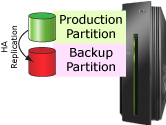
Figure 1: HA software replicates data onto a backup virtual server on the same system.
Obviously, this will not maintain data and application availability under all circumstances. For example, if a disaster destroys the physical server or if you need to take the whole box offline (perhaps to upgrade hardware), both the primary and backup virtual servers will be unavailable.
However, these types of downtime are rare. Much more common is downtime that is required to reorganize or back up databases, upgrade or patch the operating system, or install new application software versions. The virtualized HA environment depicted in Figure 1 can eliminate these types of downtime because users can be switched to the backup partition while performing maintenance on the primary partition.
Resource virtualization, particularly using SANs, makes it easy to avoid downtime due to hardware failures or upgrades.
Without any HA protection in place, data may be intact, but if the hardware that runs the applications required to access the data is down, the data is, for all intents and purposes, unavailable.
The answer, as depicted in Figure 2, is to employ a SAN to connect multiple systems to the same virtualized set of disk units. Each system can treat those resources as its own homogenized data store. Because technologies such as RAID have made disk storage very reliable, this can be a viable option for increasing data and application availability.
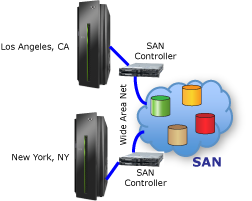
Figure 2: SANs connect multiple systems to the same virtualized set of disk units.
If there is sufficient distance between the two systems depicted in Figure 2, a disaster that destroys one will not destroy the other. Thus, this configuration may allow operations to continue unabated after a disaster.
The question then becomes, where is the SAN? If it is in a single location and that location happens to be in the path of the disaster, this design will not prevent downtime. Fortunately, SANs can be geographically dispersed over a WAN. Furthermore, some SAN technologies incorporate built-in replication functions, allowing you to spread copies of your data over a wide enough area to protect it from disasters.
Before you can be confident in the ability of this architecture to provide very high availability, you must consider two other issues.
First, is all of the necessary data stored within the LAN? If, for example, system data and/or user profiles are stored on disk drives or IASPs attached directly to the primary system, that data must be replicated independently. Otherwise, the backup system will not be able to run the business' critical applications if the primary system is unavailable.
Second, the replicators that are part of purpose-built HA products are often application-aware, meaning that it is possible to stop replication for a single application, while allowing it to continue for other applications. This can be useful if, for example, you want to keep your Web store systems running but stop your back-office databases so you can create a stable checkpoint when creating tape backups.
Application awareness also ensures that only committed data is represented on the replica database. Consequently, should the primary system fail in mid-transaction, the replica database will contain a reliable restart point, which might not be the case if only half of the transaction is stored on the replica database.
Application awareness is generally not possible when using the replication features, if any, inherent within a SAN. Thus, a SAN-based HA solution may be less flexible and less reliable than an HA-specific solution.
Even ignoring the data completeness and application awareness issues, there is still one missing feature that keeps a SAN-based architecture from being a complete HA solution. This architecture does not inherently include any automated means to switch operations from the production server in one location to the backup server in the other location. Without that capability, the switchover process may take so long and be so error-prone as to leave an organization unable to meet its availability objectives.
Under certain conditions, virtualization may allow an organization to avoid the cost of buying redundant hardware, while still achieving exceptionally high availability.
Consider the hypothetical organization depicted in Figure 3. Before implementing an HA environment, this organization had two IBM Power Systems servers, one in Boston and one in Seattle.
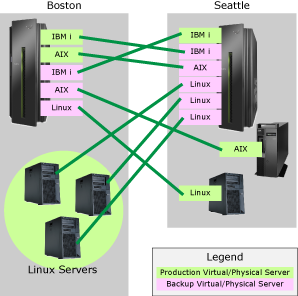
Figure 3: This hypothetical company is running two Power Systems servers.
The Boston server runs an IBM i virtual production server and an AIX virtual production server, each in its own partition. In addition, the Boston facility runs three standalone production Linux servers.
The Seattle-based Power Systems server runs just a single instance of IBM i for production purposes. However, the Seattle office also has a standalone AIX production server and a standalone Linux production server.
As depicted in Figure 3, this organization can implement a complete HA environment without purchasing additional hardware. The way to do that is to add three additional virtual servers in partitions on its Boston-based Power Systems machine to serve as backups for the Seattle-based production servers.
Likewise, five new virtual servers can be added in partitions on the Seattle-based Power Systems server to back up the Boston-based production servers. The result would be highly available data and applications that, in addition to being available during planned maintenance and isolated hardware failures, are protected from disasters because of the distance between the production and backup servers.
There is, however, a caveat to keep in mind. HA replication adds only minimal load to the source and target systems, so performance under normal circumstances will usually not be an issue when implementing the above HA configuration. However, if the Boston or Seattle Power Systems server is already running close to a critical performance threshold before implementing the HA solution, the additional replication workload may push it over the line.
The amount of workload that replication adds during normal operations depends largely on the nature of the applications that use the data. Replication occurs only when data is inserted, updated, or deleted. No data is replicated when users simply query data. Thus, if all of the production applications that use the affected data have very low update-to-query ratios, there will be little replication to the backup server.
Unfortunately, you cannot count on normal operations. If you could, there would be no reason to implement HA.
What happens when what had been the backup server has to assume the production role for some reason? If the server was sized to handle just the production roles that it was assigned before the HA solution was implemented, it will become overburdened when it has to assume additional production roles beyond the ones it normally handles.
Depending on your circumstances, this may be an acceptable risk. Unplanned downtime is rare, particularly when using IBM Power Systems hardware and IBM i, which are very reliable. It may be acceptable to curtail or shut down non-essential applications during these exceptionally infrequent outages, thereby freeing up sufficient capacity for critical applications.
Planned downtime required to upgrade hardware or software or to back up or reorganize databases is much more frequent. However, because this maintenance can be scheduled for when business operations are slow--or, preferably, closed--the system that is still functioning may have adequate capacity to run its own normal production load along with the load of the servers for which it normally plays a backup role.
Mix-and-Match HA
Employing virtualization to achieve HA doesn't have to be an "either/or" proposition. You can combine HA architectures, including multiple levels of replication, to achieve the highest possible level of availability.
For example, a switchover from the primary server to a backup server usually takes less time and requires fewer human resources when both of the systems are at the same site. Thus, redundancy in the primary location, whether that is achieved with two physical or virtual servers connected to shared storage or with two physical or virtual servers, each with its own replica data store, might be used to keep business applications and data available during software and database maintenance activities.
However, as discussed above, this scenario will not prevent all types of downtime. Thus, in addition to the local redundancy, remote replication can be used to maintain a backup server in a secondary location sufficiently distant to keep it out of harm's way should a disaster strike.
By combining local and remote HA solutions in this way, it is possible to have the best of both worlds: rapid switchovers during minor maintenance and protection against downtime due to disasters.




 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online