















In client/server computing, the three most important things are performance, performance, and performance. Therefore, when IBM began redesigning the AS/400 ODBC driver, you can guess what moved near the top of the priority list. This article provides detailed information about the performance features of the Client Access/400 ODBC driver. I'll start with a quick review of key performance issues.
Three characteristics describe the performance of any computing environment:
o Response time: The amount of time required to process a request.
o Utilization: The percentage of resources consumed when processing requests.
o Throughput: The volume of requests being processed per unit of time.
Response time is the critical performance issue for system users, while utilization concerns system administrators. Maximum throughput indicates the performance bottleneck and may or may not be a concern. All of these characteristics are interrelated, but all you need to remember is this: Throughput governs performance, and when utilization goes up, response time degrades.
In many systems, the bottleneck is wide enough that the users hardly notice it. In others, it's the primary performance concern. Response time is important, and the question is how much you can increase utilization before people start complaining.
The performance characteristics of centralized environments are far different from those of client/server environments. In centralized environments, a program has a guarantee that the memory and disk drives are paying full attention. Client/server architectures are split between the client and the server, and they communicate with each other by sending and receiving messages.
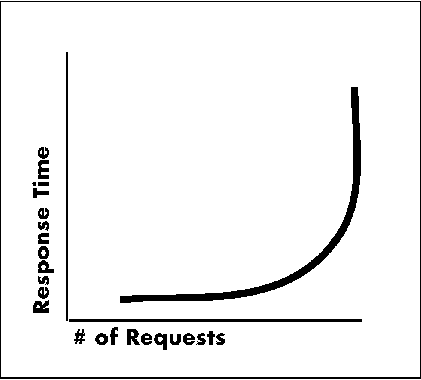
When a client requests something of the server, the client places the request on the wire, where it travels to the server and waits in a queue until the server finds time for it. Response times increase gradually as more requests are made, but then increase dramatically at some point. Actually, "dramatically" is an understatement, as shown in 1.
When a client requests something of the server, the client places the request on the wire, where it travels to the server and waits in a queue until the server finds time for it. Response times increase gradually as more requests are made, but then increase dramatically at some point. Actually, "dramatically" is an understatement, as shown in Figure 1.
The $64 question is "At what point do things get ugly?" The answer varies with every client/server installation, which is why 1 has no numbers. Worse yet, you typically won't know where the wall is until you run into it.
The $64 question is "At what point do things get ugly?" The answer varies with every client/server installation, which is why Figure 1 has no numbers. Worse yet, you typically won't know where the wall is until you run into it.
A very important rule of client/server architectures is this: Don't go to the server unless you have to, and, when you have to, go there in as few trips as possible. It's a simple rule that people understand in their everyday lives (I drive to the grocery store once a week rather than bring my milk and cookies home one trip at a time). Unfortunately, programmers, and therefore users, too often break this client/server rule. Opening a file and reading one record at a time has gotten many client/server projects and tools into trouble. It can be expensive for a business to learn this lesson when trying to go, for example, from 60 to 90 users, only to find out that the wall is somewhere in between.
When IBM rewrote the Client Access/400 ODBC driver, the performance characteristics of client/server architectures significantly affected the design. For example, all of the internal data flows between the client and the server are chained together and make the trip only when needed. This reduces server utilization because the overhead of the communications layer is executed only once. Response times decrease correspondingly.
These types of enhancements are transparent to the user, while other enhancements are externalized as configuration entries in the ODBC.INI file. The following sections discuss some of these entries.
The Client Access/400 ODBC driver is configured by editing configuration parameters in the ODBC.INI file. This file is located in the directory where Windows is installed on your system. Many configuration parameters are available, but the ones shown in 2 are of special interest when looking at performance.
The Client Access/400 ODBC driver is configured by editing configuration parameters in the ODBC.INI file. This file is located in the directory where Windows is installed on your system. Many configuration parameters are available, but the ones shown in Figure 2 are of special interest when looking at performance.
Don't use commitment control unless you have to. The overhead of locking not only drives up utilization but also restricts the ability to update data. Of course, if your application isn't read-only, it might require commitment control. A common alternative, however, is to use "optimistic" locking. This method involves issuing explicit UPDATEs using a WHERE clause that uniquely determines a particular record and ensures that the record has not changed since being retrieved.
Many third-party tools use this approach, which is why some require defining a unique index for updatable tables. A record update can then be made by fully qualifying the entire record contents. Take the following example:
UPDATE table SET C1=new_val1, C2=new_val2, C3=new_val3 WHERE C1=old_val1 AND C2=old_val2 AND C3=old_val3
This statement guarantees that the desired row is accurately updated only if the table contains three columns and each row is unique. The following alternative performs better.
UPDATE table SET C1=new_val1, C2=new_val2, C3=CURRENT_TIMESTAMP WHERE C3=old_timestamp
However, this method works only if the table has a timestamp column that holds information about when the record was last updated. Always setting the new value for this column to CURRENT_TIMESTAMP then guarantees row uniqueness.
If commitment control is required, though, use the lowest level of record locking possible. For example, use *CHG over *CS when possible, and never use *ALL when *CS gives you what you need. For more information on commitment control, refer to OS/400 DB2/400 Database Programming Guide V3R1.
There are two ways to invoke multiple SQLrequests. The first approach is to construct each SQL statement by using "literals" for the data. For example, the following operations insert two rows into the EMPLOYEE table:
s1 = INSERT INTO EMPLOYEE VALUES ('BOB') s2 = INSERT INTO EMPLOYEE VALUES ('John') SQLPrepare( s1 ); SQLExecute( s1 ); SQLPrepare( s2 ); SQLExecute( s2 ); An alternative approach is to construct one SQL statement using "parameter markers," which allow variable substitutions at run time. For example:
s1 = INSERT INTO EMPLOYEE VALUES (?) SQLPrepare( S1 ); SQLBindParameter( s1, 'Bob' ); SQLExecute( s1 ); SQLBindParameter( s1, 'John' ); SQLExecute( s1 );
This approach offers a significant performance advantage over using literals because resources associated with the preparation of the statement can be used for multiple executions. It is not unusual for the parameter marker approach to run 2-3 times faster than when using literals.
Because the performance advantage of using parameters markers is so large, we have added an ODBC.INI option, called ConvertLiterals which automatically translates some SQL statements containing literals into their parameter marker equivalents. At the present time, only SQL INSERT statements are converted, and the default is to not do the conversion (for backward compatibility). In addition, the 5763XC1 PTF SF26466 is required to enable this feature.
The record blocking technique greatly reduces the number of network flows by returning a block of rows from the server on a cursor's first FETCH request. Subsequent FETCH requests are retrieved from the local block of rows rather than from the server. This technique dramatically increases performance when properly used, and the default settings should be sufficient for most situations.
From a scaling perspective, however, a change to one of the record blocking parameters can make a significant difference when your environment's performance is approaching the "exponential" wall in 1. For example, assume that your environment has n decision support clients working with large queries that typically return 1MB of data. Using the default BlockSizeKB parameter of 32KB, each time a user queries the database, it takes 32 trips between the server and the client to return the data. Changing the BlockSizeKB value to 512 reduces the number of server requests by a factor of 15 and might make the difference between approaching the exponential wall and being squished up against it.
From a scaling perspective, however, a change to one of the record blocking parameters can make a significant difference when your environment's performance is approaching the "exponential" wall in Figure 1. For example, assume that your environment has n decision support clients working with large queries that typically return 1MB of data. Using the default BlockSizeKB parameter of 32KB, each time a user queries the database, it takes 32 trips between the server and the client to return the data. Changing the BlockSizeKB value to 512 reduces the number of server requests by a factor of 15 and might make the difference between approaching the exponential wall and being squished up against it.
In the opposite extreme, you might have users consistently asking for large amounts of data but looking at no more than a few rows. Returning 32KB of rows when only a few are needed could hurt performance. Setting the BlockSizeKB parameter to a lower value, or even disabling record blocking altogether, might increase performance.
As always in client/server, your performance mileage may vary. You might make changes to these parameters and not see any difference, indicating that your performance bottleneck is not the client request queue at the server. What this parameter gives you, however, is one more tool in the box to use when your users start complaining.
Traditional SQL interfaces used embedded SQL. SQL statements were placed directly in an application's source code, along with high-level language (HLL) statements written in C, COBOL, or RPG, for example. The source code was then precompiled, which translated the SQL statements into code that the subsequent compile step could process. One advantage of this approach, called static SQL, is that the SQL statements are optimized in advance rather than at run time while the user is waiting, thus improving performance.
ODBC, however, is a call-level interface, which uses a different approach. Using a call-level interface, SQL statements are passed to the database management system (DBMS) within a parameter of a run-time API. Since the text of the SQL statement is never known until run time, the optimization step must be performed every time an SQL statement is run. This approach is known as dynamic SQL.
DB2/400 supports both static and dynamic SQL and a sort of hybrid called extended dynamic SQL, which allows applications to use dynamic SQL without having the optimization step performed for each execution of a particular statement. For example, an application uses a SELECT statement containing parameter markers, which provide run-time-specific variables for the query. Using an extended dynamic approach, DB2/400 optimizes the query the first time it is PREPAREd and stores the executable form of the statement in a package for later use. When the same statement is subsequently PREPAREd, its executable form is simply retrieved from the package and run, saving the overhead of reoptimization.
Using the extended dynamic feature (which is enabled by default) can not only reduce response times, but also dramatically decrease server utilization. Optimizing SQL queries can be expensive, and performing this step only once is advantageous. This method works well because, unlike other DBMSs, DB2/400 has a unique feature that ensures that statements stored in packages remain optimized without administrator intervention. Even if a statement was prepared for the first time months ago, DB2/400 automatically regenerates the access plan when it determines that sufficient database changes warrant reoptimization.
Only those SQL statements likely to be reexecuted go into the package. This includes only SQL statements with parameter markers. Other SQL statements, containing only literals, are prepared, executed, and discarded to avoid unreasonable package growth.
The LazyClose ODBC.INI option can increase performance in situations with many cursor opens and closes, such as those often found in online transaction processing (OLTP) applications. The Client Access/400 ODBC driver buffers server requests at the client until either a server response is required or the client buffer gets full. In either case, all buffered requests are sent to the server, and return information is provided. Close cursor requests are a good candidate to defer because, while they do work on the server, they do not return data other than a return code, which is almost always successful. Therefore, by default, we hold these requests at the client until other operations force a trip to the server.
One situation could have adverse side effects when using this option. If a program reads some records using commitment control and obtains locks, these locks are not released until the CLOSE cursor operation is performed at the server. If the program issues a CLOSE operation and the user goes home without exiting the program or performing an ODBC operation that would cause a server flow, one or more locks might be held in the database. This is unlikely, however, because many ODBC programs do not use commitment control and, thus, do not obtain locks. Of those that do, many call the SQLTransact API after typical operations, and the CLOSE cursor request flows then.
Obviously, performance is a key issue in matters of client/server connectivity. I've only gotten started on the topics you'll need to know about to have a better understanding of client/server performance issues. In a future article, I'll discuss general client/server performance issues and the performance implications of using ODBC with popular query tools and development environments.
Lance C. Amundsen is a member of the Client Access/400 ODBC development team in Rochester, Minnesota. His primary responsibility is identifying and imple-menting performance enhancements in the ODBC driver.
REFERENCE
OS/400 DB2/400 Database Programming Guide V3R1 (SC41-3701, CD-ROM QBKAUC00).
Maximizing Performance with Client Access/400 ODBC
Figure 1: Typical Response Time Curve
Maximizing Performance with Client Access/400 ODBC
Figure 2: ODBC.INI File Configuration Parameters
CommitMode=[0,1,2,3]
0-*NONE
1-*CS
2-*CHG
3-*ALL
ConvertLiterals=[0,1]
0-No action
1-Transform inserts u
sing literals
into parameter marker
equivalents
RecordBlocking=[0,1,2]
0-Disabled
1-Block if FOR FETCH ONLY specified
2-Block except when FOR UPDATE OF specified
BlockSizeKB=[1...512]
From 1- to 512KB (Default = 32)
ExtendedDynamic=[0,1]
0-Do not use packages
1-Use packages
LazyClose=[0,1]
0-Force close cursor requests
1-Defer close cursor requests

 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online