















CCSID (pronounced see-sid) is not just another acronym that you pronounce; it is a very important feature of the AS/400 and the iSeries 400. Yet, as something so important, very few of us programmers fully understand it. This article takes a look at what coded character set IDs are and how they are used. It is intended for anyone looking for a basic under- standing of CCSIDs, but this article is also targeted at software developers. It does not fully explain national language support; IBM provides some really great manuals for that. (See the Reference and Related Materials list at the end of this article.)
All Developers Need CCSIDs
There are many reasons why software developers need to understand CCSIDs, even if they are not developing international software. CCSIDs require consideration when software is being developed under any of the following conditions (this list is not all-inclusive):
- The software will run on a system with a different primary language than the system on which the software was developed.
- The software will run on a system with one or more secondary languages installed.
- The software communicates with other systems, such as ASCII-based Unix systems or systems running with a different primary language.
- The software ports data to or from other systems using tools such as FTP.
- The software converts data from EBCDIC to ASCII, or vice versa.
All of the above conditions may require some form of data conversion. In some cases, data conversion is performed implicitly by OS/400; in other cases, the software has to perform an explicit conversion of the data. For example, software that communicates with another system may need to convert data that it sends from EBCDIC to ASCII, and vice versa for data that it receives. Data conversion is performed using CCSIDs, even when converting from EBCDIC to ASCII. This is evident by examining the CCSID attribute of the TCP/IP servers (such as FTP and SMTP). These servers have a CCSID attribute with a default value of 00819, which represents the most common version of ASCII. The point here is that all developers need to understand how CCSIDs work—their use is not exclusive to international software authors. Now, take a look at the specifics of why you need to understand this stuff.
Character Sets, Code Pages, and Code Points
As with any technical subject matter, national language support has its own terminology. At the basic level, there are character sets, code pages, and code points.
A character set is simply a group of letters, numbers, or other characters. By itself, a character set does not have an encoding scheme that assigns a numeric value to each character. An example of a character set is the English alphabet used in the United States. Another example is the Danish alphabet, which has some different characters than the English alphabet and is, therefore, a different character set. In and of itself, the English alphabet does not have an encoding scheme associated with it, although it is included in the popular EBCDIC and ASCII encoding schemes, among others.
To a computer, all data is just a series of bits. These bits represent binary values. As it is difficult to read binary data, a graphical representation is needed. This is where encoding schemes come into play. An encoding scheme cross-references binary data with character sets. This allows the computer to display its data as graphical characters, a form pleasant to the human eye.
The EBCDIC (extended binary-coded decimal interchange code) encoding scheme, used by IBM, supports many different character sets. The iSeries uses what is known as a code page to allow for different character sets. A code page is a combination of a character set and an encoding scheme, where each character is represented by a unique binary value. The binary value for each character is known as a code point. Code pages contain many code points, not all of which are displayable characters. (Nondisplay characters are referred to as control characters.)
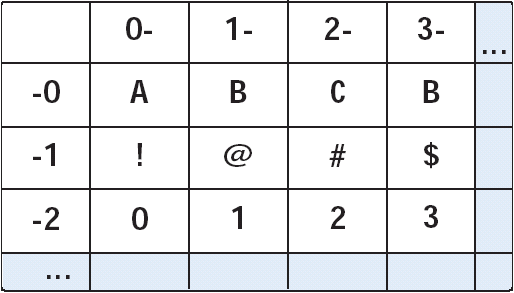
Figure 1: In this excerpt from a hypothetical code page, each cell is a code point.
A code page is displayed as a matrix and usually indicates the hexadecimal value of a code point rather than the binary value, simply because it is easier for developers to work with hexadecimal numbers than binary ones. Code pages exist for many different countries and languages, each one being assigned a unique numeric value. To clarify this, I'll use an analogy: If each character set is assigned a page, and those pages are put into a book, that book would be called EBCDIC. Each page in that book would be a code page. Each code page would be referenced by its page number. There would also be a similar book for the ASCII encoding scheme (American Standard Code for Information Interchange). The iSeries reads both the EBCDIC and the ASCII books, with the former being read more often.
Figure 1 shows an excerpt from a hypothetical code page. Each cell in that matrix is a code point. The hexadecimal value for each code point is determined by combining the value from the column heading as the first hex digit and the value from the row heading as the second hex digit. Thus, code point X'10' in the hypothetical code page is an uppercase B, and code point X'31' is the character $.
Different code pages represent different character sets. The code points for a given character may vary between code pages. For example, in code page 819, code point X'42' is an uppercase B. In code page 37, an uppercase B is at code point X'C2', and X'42' is the character ‚. Therefore, to preserve the integrity of the data when moving between a system that uses code page 37 and one that uses 819, a conversion must take place to convert X'C2' to X'42'. The conversion will preserve the B so that the user on the 819 system sees the same character as the user on the 37 system. See Appendix F of IBM's International Application Development manual for the actual IBM code pages. (Both 37 and 819 are listed.)
A code page is associated with a particular character set, but a character set may be represented by more than one code page. For example, the U.S. English character set is represented by several code pages, including 37 (United States) and 277 (Denmark). On the other hand, code page 37 is only associated with one character set, U.S. English. More precisely, the character set used by code pages 37 and 277 is the Country Extended Character Set, which includes the U.S. English alphabet as well as many characters used in other languages.
Coded Character Set Identifiers
The iSeries supports many languages, character sets, and code pages. In fact, the iSeries even allows different users running on the same system to use different languages. Having this integration of code pages presents a data integrity problem. Figure 2 illustrates this problem.
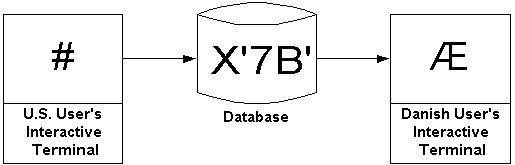
Figure 2: Here is an example of a data integrity problem resulting from integrating code pages.
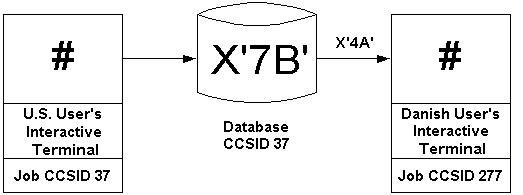
Figure 3: CCSIDs solve the data integrity problem by allowing data to be converted.
As shown in Figure 2, the U.S. user writes a record to the database containing the pound sign (#) character. The U.S. code page 37 assigns code point X'7B' to the # character, so a X'7B' is stored in the database. The Danish user then reads the same record from the file, but code point X'7B' on the Danish code page 277 is the [.Delta] character, which is what the Danish user sees. These results are not acceptable.
To address the issue of data conversion between code pages, the coded character set identifier (CCSID) was created. A CCSID is an attribute (or field) of an object that identifies how data inside the object is encoded, indicating the code page and character set of the data. In most cases, the CCSID is actually the same value as the code page. (U.S. CCSID is 37, and the associated code page is also 37). Having data tagged with CCSIDs allows the system to automatically convert between code pages when necessary. This data conversion is generally referred to as CCSID conversion; however, the end result is really a conversion from one code page to another, so it can be thought of as code page conversion.
Figure 3 revisits the example in Figure 2, only this time using CCSIDs to allow for the data to be converted. As in the first example, the U.S. user writes a record to the database containing the #, and a value of X'7B' gets stored. Now, when the Danish user reads the record, the system realizes that the job's CCSID is 277 and the CCSID of the data is 37. So, the system performs an implicit conversion of the data from CCSID 37 to 277. The X'7B' gets converted to X'4A', the code point for the # on the 277 code page. The Danish user sees the # character as he is supposed to. This also works conversely; if the Danish user writes a # character to the database, it gets converted to X'7B' before it is actually stored.
CCSID conversion can be implicit or explicit. Implicit conversions are performed by OS/400 when it determines that it is moving data between two different code pages. Explicit conversions are performed by software when developers require a conversion. Developers can code calls to the CCSID conversion APIs to explicitly perform the conversion. One instance where explicit conversion is required is when writing communications software that talks to a non-iSeries platform, such as UNIX. UNIX systems use ASCII character sets; thus, a conversion to ASCII is required when communicating with those systems. Since the iSeries also supports ASCII code pages, this conversion can be performed using the conversion APIs.
One final thing to note is that a given character may appear in one code page but not another. The system has different ways in which it handles this condition when it occurs. For an explanation of how this is handled, see IBM's International Application Development manual.
CCSIDs, CCSIDs Everywhere
Now that you have an understanding of what CCSIDs are, take a look at where they are used. CCSID attributes appear in a lot of places. I will focus on the most relevant ones: jobs, user profiles, the QCCSID system value, and objects containing data.
One of the more important CCSID attributes is the job CCSID. The job CCSID attribute is used by the system to decide if implicit conversions are needed when objects are accessed. When an object is accessed—for example, when a file is read—the system compares the job CCSID to the object's CCSID. If the two are different, the data is converted to the job CCSID (code page) before the program even gets the data returned to it. This is exactly the case in the example given for Figure 3. The job attribute can also be used for explicit CCSID conversions using conversion APIs.
Job attributes are assigned when a job enters the system. The job CCSID value comes from the user profile of a job. Thus, when a job starts, the system looks at the CCSID attribute of the user profile and then assigns that value to the job attribute. Actually, it's a little more complicated, as the user profile's CCSID may have the special value *SYSVAL. *SYSVAL tells the system to look at the system value QCCSID to get the value for the job attribute. The QCCSID system value defines the default CCSID used on the system. Many, if not all, user profiles will point to the system value for their CCSID.
Many objects also have CCSID attributes. The objects to be most concerned with are ones that contain data, such as database files, message files, and message queues. An object's CCSID attribute identifies how the data inside the object is stored. It is then used by the system to determine if conversion is needed when the object is accessed.
Jobs have another CCSID attribute called the default CCSID. To understand the default CCSID, you first need to look at the special CCSID value 65535. When a CCSID attribute has the value 65535, the system does not perform conversions on that data. This special value is also called *HEX, as it is intended to indicate hexadecimal data (although I prefer to call it binary data, but there is no *BIN). True binary data is not represented by characters, so therefore, no CCSID is necessary. Binary data should not be converted, as a conversion will destroy the data, so it should be tagged with CCSID 65535. I should note that numeric fields are automatically treated as *HEX.
The iSeries ships with the QCCSID system value set to 65535, and many systems actually run this way. This works okay, but it does present a couple of problems. If a job is running with a CCSID of 65535 and it creates an object containing data, what CCSID should that object be assigned? Using 65535 defeats the purpose of even having the CCSID in the first place (refer to Figure 2). What about the case when a CCSID conversion is absolutely required? If a job is talking to an ASCII-based system, a conversion to ASCII is required. However, if the job is running with 65535, you do not know what CCSID to use as the From CCSID on your conversion to ASCII. To solve these problems, the job default CCSID attribute was introduced. This attribute is only used when the job CCSID is 65535. If the job CCSID is 65535, the system determines the default CCSID by looking at the language ID of the job; language IDs have corresponding CCSIDs and are also an attribute of a job.
One other thing to note is that the iSeries does allow for field-level CCSID attributes. A field-level attribute allows an override of the object-level CCSID for a specific field. One use for this is when a file contains some fields with character data and some with binary data. Just use a field-level CCSID attribute set to 65535, and all is well.
See-Sid, See-Sid Run
Hopefully, this article was enough to get you up and running with CCSIDs. Now that you have a basic understanding of how they work, making sense of the manuals should be a little easier. The Native Language System is a complex topic. For a more complete explanation of the iSeries' national language support, see the References and Related Materials list at the end of this article. Also, look for the second part of this article, which will cover using CCSID conversion APIs, among other things, in the August issue of Midrange Computing .
Matt Bresnan is a software engineer and project lead for Help/Systems, Inc. He lives in Chaska, Minnesota, where the winters are cold but the iSeries is hot! He can be reached by email at
REFERENCES AND RELATED MATERIALS
- International Application Development manual:http://publib.boulder.ibm.com/ pubs/pdfs/as400/V4R2PDF/qb3aq501.pdf
- National Language Support: http://publib.boulder.ibm.com/pubs/ pdfs/as400/V4R2PDF/qb3awc01.pdf
- System API Reference, Version 4: http://publib.boulder.ibm.com/pubs/ pdfs/as400/V4R4PDF/QB3AMA03.PDF
- "Speak the Right Language with Your AS/400 System,"www.redbooks.ibm.com/ pubs/pdfs/redbooks/sg242154.pdf



 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online