
















This article provides the details on how to use one of the most useful system management APIs, QUSROBJD.
Whether you're looking for unused objects, analyzing library differences, or checking how current your source is, QUSROBJD provides a wide range of valuable information—so much, in fact, that you might want to spend a little time up front to make it really easy to use in your programs. IBM provides predefined /COPY books to access their APIs, but this article will introduce you to a more modern approach that can be used for QUSROBJD and throughout the IBM i API universe.
What Is QUSROBJD?
QUSROBJD (officially known as the Retrieve Object Description API) provides a programmatic way to retrieve the information you would normally get through the DSPOBJD command. QUSROBJD is probably one of the first APIs I ever used, along with QWCCVTDT. I checked, and QUSROBJD has been around since V1R3 of the operating system, so it's not surprising that it's one of the first APIs I used.
QUSROBJD lets you retrieve nearly everything you need to know about an object. In fact, until the advent of ILE programming, there wasn't anything I needed to know about an object that I couldn't get from this API. A bit further on in this series of articles, we'll get to a discussion of the QBNLPGMI API and why we need it, but for now we can concentrate on QUSROBJD.
Like many IBM i APIs, QUSROBJD can return many different formats of data. The format of the returned data is specified as one of the parameters to the API. You can see the parameter list in Figure 1.
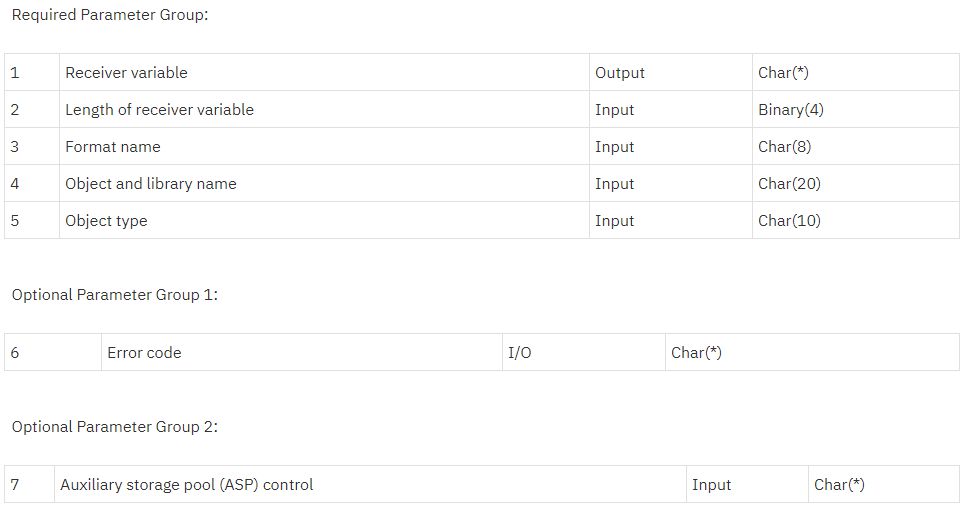
Figure 1: Here’s the parameter list for QUSROBJD from the IBM website.
As you can see, there aren't many parameters. QUSROBJD uses a relatively standard configuration shared by many IBM i APIs: a pointer to the receiver variable, its length, a format name that identifies the data to return, and one or more parameters to identify the object being queried. In this case, the values are the object library and name and the object type. The library and name are passed together in a single 20-character variable. This is very traditional in API programming; the object name is in the first 10 characters, and the object library is in the other 10. You'll notice two optional parameter groups. The word “group” is very loose; in this case, each group consists of a single parameter. I don't use the ASP parameter, but the error parameter is very important. For much more detail on it, please refer to my earlier article on API error handling.
So to clarify, the API can return several different configurations of information. Currently, QUSROBJD can return data in one of four layouts. Each has its own format identifier, and you specify that identifier as the third parameter when you call the API.
Doing Things the IBM Way
As I noted at the beginning of the article, IBM provides you with /COPY books to use to access the API. They're pretty barebones; they provide very simple definitions of the data structures that are geared toward programming in fixed-format RPG. They've got both RPG/400 and ILE RPG versions, but the ILE RPG uses fixed-format D-specs. Here is a comparison of the two styles (after removing the comments):
I 'QUSROBJD' C QUSFDB
IQUSFF DS
I B 1 40QUSFFB
I B 5 80QUSFFC
I 9 18 QUSFFD
I 19 28 QUSFFF
Listing 1: This is the RPG/400 version of the QUSROBJD definition in QRPGSRC in QSYSINC.
D QUSROBJD C 'QUSROBJD'
DQUSD0100 DS
D QUSBRTN06 1 4I 0
D QUSBAVL07 5 8I 0
D QUSOBJN00 9 18
D QUSOBJLN 19 28
Listing 2: This is the ILE RPG version of the QUSROBJD definition in QRPGLESRC in QSYSINC.
As you can see, it's a pretty low-tech conversion from one to the other. They updated the field names, and the numeric value changed from binary (B) to integer (I), but other than that it's still old-school RPG. Not that there's anything wrong with that, mind you; it meets the requirements of the lowest common denominator. But it's definitely not my preferred technique, especially the from and to positions for the field definitions. Something else becomes clear once you start looking at the other data structures, such as the one below for QUSD0200.
DQUSD0200 DS
D QUSBRTN07 1 4I 0
D QUSBAVL08 5 8I 0
D QUSOBJN01 9 18
D QUSOBJLN00 19 28
Listing 3: The first lines of the OBJD0200 layout are nearly identical to the OBJD0100 definitions.
This is the definition for the OBJD0200 format, and you'll see that the first fields are the same as the first fields of the OBJD0100 format, except with slightly different names. Why is this? Well, the QUSROBJD API has a quirk in that every format is like the previous format but with more fields. In fact, in the definition on the IBM website, the first line of the definition for OBJD0200 literally says "everything from the OBJD0100 format." That being the case, you have to replicate all the fields for OBJD0100 in each of the four data structures. And since this is old-school RPG with no concept of qualified names, you have to have slightly different names for each field, hence the strange (and somewhat inconsistent) suffixes on the end of the repeated fields. As you can imagine, it's even worse in the /COPY books for RPG/400, with the six-character field name limitation.
In a fixed-format ILE RPG program, your code might look like this:
C CALL QUSROBJD
C PARM QUSD0100
C PARM QUSD0100L
C PARM 'OBJD0100' QUSDFMT 10
C PARM OBJNAMLIB
C PARM OBJTYPE
C PARM ErrorDS
Listing 4: This would be a standard fixed-format call to the API.
There are a couple of additional definitions; the value QUSD0100L must be a four-byte integer (10I0, or int(10)) containing the length of the QUSD0100 structure, OBJNAMLIB must be a 20-character field with the object name and library as noted earlier, and OBJTYPE is a 10-character field containing the object type. ErrorDS needs to be a structure in one of the formats detailed in the API error handling article.
Freeing Your APIs
There's really no problem with the /COPY books that IBM provides. They're perfectly functional. But even after all that, you still have to figure out where the data is. And does a field name like QUSTD13 really indicate to you that it's the object's description? No, it doesn't. So instead, let me show you what I've done. Since the beginning of each data structure is exactly the same as the entire preceding data structure, I've created a set of templates. I've done one for each of the four structures, defining the fields unique to that structure. Here are the first two:
dcl-ds T_OBJD_0100 template qualified;
BytesRtn int(10);
BytesAvl int(10);
Object char(10);
Library char(10);
ObjectType char(10);
LibFound char(10);
ASP int(10);
Owner char(10);
Domain char(2);
CreateTS13 char(13);
ChangeTS13 char(13);
end-ds;
dcl-ds T_OBJD_0200 template qualified;
ExtendedAttr char(10);
Description char(50);
SrcFile char(10);
SrcLib char(10);
SrcMbr char(10);
end-ds;
Listing 5: These are the first two of the four templates for QUSROBJD.
The T_OBJD_0100 template contains all the fields for the OBJD0100 data structure. T_OBD_0200 contains all the fields for the OBJD0200 that are not in the OBJD0100 structure. The T_OBJD_0300 and T_OBJD_0400 templates follow the same pattern. You may notice that I do not use positioning for the subfields of the data structure. Instead, I define every spot in the data structure. This works as long as the data structure is entirely defined, which it is in the IBM /COPY books, even if they do occasionally resort to defining "reserved" sections. We can debate the pros and cons of sequential definitions versus positioned definitions another day, but sequential definitions are essential for the next part. Now I use those templates as building blocks for my actual structures:
dcl-ds T_OBJD0100 qualified template;
A0100 likeds(T_OBJD_0100);
end-ds;
dcl-ds T_OBJD0200 qualified template;
A0100 likeds(T_OBJD_0100);
A0200 likeds(T_OBJD_0200);
end-ds;
dcl-ds T_OBJD0300 qualified template;
A0100 likeds(T_OBJD_0100);
A0200 likeds(T_OBJD_0200);
A0300 likeds(T_OBJD_0300);
end-ds;
dcl-ds T_OBJD0400 qualified template;
A0100 likeds(T_OBJD_0100);
A0200 likeds(T_OBJD_0200);
A0300 likeds(T_OBJD_0300);
A0400 likeds(T_OBJD_0400);
end-ds;
Listing 6: Using the first template, I can now build the data structures.
So, as an example, my T_OBJD0300 structure contains three substructures, one for each set of fields. This is where qualified data structures become so much fun! Whenever I want to get at, say, the object owner, I simply access dsObject.A0100.Owner. It doesn't matter which data structure I used to define dsObject; the Owner subfield is always in the A0100 substructure. This is why I define even my highest-level structures as templates: that way, I can name my structures whatever I want in the calling program. Finally, I have the actual prototype here:
// QUSROBJD - Retrieve object description
dcl-pr QUSROBJD ExtPgm;
iData char(32767) Options( *VarSize );
iDataLen int(10) Const;
iDataFmt char(8) Const;
iObjQName char(20) Const;
iObjType char(10) Const;
ErrorDS char(32767) Options( *VarSize );
end-pr;
Listing 7: This is the prototype for the API itself.
Now that you have the infrastructure in place, calling the API becomes very simple. Let's take a situation: you want to write a procedure that will return the program type for a program (e.g., RPG, RPGLE, or CLLE). You can now write a procedure to do that with about 10 lines of code:
dcl-proc getAttribute;
dcl-pi *n char(10);
iPgm char(10);
iLib char(10);
end-pi;
dcl-ds dsObject likeds(T_OBJD0200);
dcl-ds apiError likeds(api_ErrorDS);
QUSROBJD( dsObject: %size(dsObject): 'OBJD0200':
iPgm+iLib: '*PGM': apiError);
return dsObject.A0200.ExtendedAttr;
end-proc;
Listing 8: Using the free-format QUSROBJD prototype.
That's all there is to it. I'm glossing over a bit, such as error handling, but that's been covered in detail in the other article. What's important about this is how simple it is to call the API. I can easily call it to get additional information by simply using a different template (i.e., T_OBJD0400) and passing in a different format name. It's that easy.
Of course, the trick now is to create all those free-format API definitions for other APIs. I'm tempted to write a program that will extract that information from the IBM /COPY books. While the data structure field names are very cryptic, the comments are quite good, and I could probably extract meaningful field names from them.
It's something to think about. But until then, I hope you enjoyed this introduction to QUSROBJD and free-format APIs.

Joe Pluta is the founder and chief architect of Pluta Brothers Design, Inc. He has been extending the IBM midrange since the days of the IBM System/3. Joe uses WebSphere extensively, especially as the base for PSC/400, the only product that can move your legacy systems to the Web using simple green-screen commands. He has written several books, including Developing Web 2.0 Applications with EGL for IBM i, E-Deployment: The Fastest Path to the Web, Eclipse: Step by Step, and WDSC: Step by Step. Joe performs onsite mentoring and speaks at user groups around the country. You can reach him at
MC Press books written by Joe Pluta available now on the MC Press Bookstore.
 |
Developing Web 2.0 Applications with EGL for IBM i Joe Pluta introduces you to EGL Rich UI and IBM’s Rational Developer for the IBM i platform. List Price $39.95 Now On Sale
|
|
 |
WDSC: Step by Step Discover incredibly powerful WDSC with this easy-to-understand yet thorough introduction. Now On Sale
|
|
 |
Eclipse: Step by Step Quickly get up to speed and productivity using Eclipse. Now On Sale
|



 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online