















It’s important to keep in mind that the naming conventions are not limited to variables, procedures, and files. Since you’re starting with ILE and building your first modules and service programs, this is the perfect time to start doing it the right way.
I mentioned that modules should aggregate procedures/functions by action and/or subject. For example, you should put all the functions related to database operations over the inventory files in the same module, while putting all the business logic functions (validations, rules enforcement, etc.) in another module. The next logical step is naming these modules (and the service programs that include them) following a proper naming convention and keeping everything organized in a simple, logical, and practical fashion.
The fact that the system object names are limited to 10 characters doesn’t help, so you need to set and follow a few standards that you’re comfortable with. I’ve seen many different approaches to this problem. My favorite solution is the following:
If an application has clearly defined parts (like a typical ERP), you can assign a three-letter code to the part name and use another three characters to identify the generic task performed by the procedures/functions of the module (such as database access, business logic, or calculations).
For example, a module of the inventory management part of an application that aggregates all the database operations related to the inventory files could be named IVM_DBO (or IVMDBO): IVM for inventory management and DBO for database operations.
When you consider changing a monolithic application structure to something more modular, it’s important to identify all the generic tasks that your application performs and define an abbreviation for each of them. Then, go over the application structure and do the same for all the “application parts.” (I’m using the expression “application parts” instead of “application modules,” which is a much more common term, so that you don’t confuse them with ILE modules.)
Tips for Organizing Your Code
In a traditional OPM environment, your programs are isolated silos that work alone or with some helper programs, so the need for real organization doesn’t go beyond separate libraries for sources, files, and programs. In an ILE environment, the complexity is much greater; you have a multitude of modules, service programs, programs, and binding directories to organize and manage. In order to build a program, you’ll probably need a “main flow” module and one or more service programs, which might have one or more modules. In the example in Figure 1, repurposed from one of the first TechTips of this series, M1 and M2 are the “main flow” modules of programs A and B, respectively. Modules M3 and M4 are part of the C service program that is used by both programs. Just ignore the names; they’re bland on purpose to keep the focus on the structure.
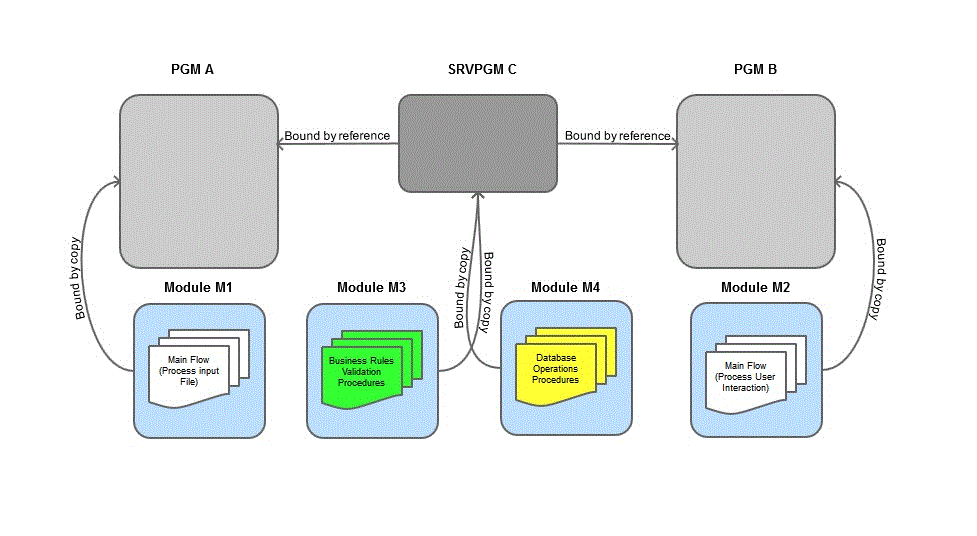
Figure 1: This is a basic module, program, and service program scenario.
This complexity increases in real-life situations, in which a program might use 10 or more service programs (depending on how you decided to organize the modules). So you really need to organize your code; otherwise, all the productivity gains that ILE potentially brings will be lost.
How to Organize Your Service Programs
This TechTip started by showing how to name your modules. It’s now time to talk about how to group those modules in service programs.
The service program organization usually follows one of two approaches:
- Create one service program per module if your modules group all the procedures/functions of a given combination of “application part” and “generic task.”
- Group all the “application part” modules into a single service program.
Each of these approaches has advantages and disadvantages. While having one service program per module provides maximum flexibility and decreases compilation time, it also requires that you know where to find the procedures you need and add the appropriate procedure prototypes to your program. As I explained before, it’s simply a matter of using a /COPY statement, specifying the name of the copy member that contains the procedure prototypes.
The other approach doesn’t require you to know which service programs to include in so much detail because you have one for each application “part.” However, it might cause other problems, such as duplicated function names in different modules (if you don’t prefix your functions with the module name) and longer compilation times, just to name a couple. I’ve seen the one-service-program-per-module solution work better, once you know where to find the procedures needed. You need to choose carefully, though, because reorganizing everything in an ILE environment is tricky!
No matter what your choice is, you’ll need to include the procedure prototype definitions in the “main flow” modules (i.e., programs) that need to use them, using /COPY or /INCLUDE. The most practical way to do this is to create a source member in a separate file (I like to use QCPYLESRC) for each module. This copy member would include all the module’s procedure prototypes, as well as common data structures and constants used to call the procedures. If you have one service program per module, then you just need to include the service program names in a binding directory (ideally, they’ll be the same as the modules’)…or not, depending on your binding directory organization, which will be the topic of the next TechTip!
Without wanting to turn this into a war between “groupers” (people that prefer the one-service-program-with-many-modules) and “splitters” (the guys and gals that advocate one-service-program-per-module), I’d like to hear about your preference and the reasons behind it. Speak your mind in the Comments section below!

Rafael Victória-Pereira has more than 20 years of IBM i experience as a programmer, analyst, and manager. Over that period, he has been an active voice in the IBM i community, encouraging and helping programmers transition to ILE and free-format RPG. Rafael has written more than 100 technical articles about topics ranging from interfaces (the topic for his first book, Flexible Input, Dazzling Output with IBM i) to modern RPG and SQL in his popular RPG Academy and SQL 101 series on mcpressonline.com and in his books Evolve Your RPG Coding and SQL for IBM i: A Database Modernization Guide. Rafael writes in an easy-to-read, practical style that is highly popular with his audience of IBM technology professionals.
Rafael is the Deputy IT Director - Infrastructures and Services at the Luis Simões Group in Portugal. His areas of expertise include programming in the IBM i native languages (RPG, CL, and DB2 SQL) and in "modern" programming languages, such as Java, C#, and Python, as well as project management and consultancy.
MC Press books written by Rafael Victória-Pereira available now on the MC Press Bookstore.
 |
Evolve Your RPG Coding: Move from OPM to ILE...and Beyond Transition to modern RPG programming with this step-by-step guide through ILE and free-format RPG, SQL, and modernization techniques. List Price $79.95 Now On Sale
|
|
 |
Flexible Input, Dazzling Output with IBM i Uncover easier, more flexible ways to get data into your system, plus some methods for exporting and presenting the vital business data it contains. Now On Sale
|
|
 |
SQL for IBM i: A Database Modernization Guide Learn how to use SQL’s capabilities to modernize and enhance your IBM i database. Now On Sale
|



 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online