















Oh, the times they are a changing! Slowly but surely, our systems are being opened up to multiple points of access (the Web, Web services, Java programmers, VB programmers, .Net programmers, etc.); correspondingly, our databases are open to multiple points of potential violation. The whole security issue is for others to discuss, but what about the integrity of the data in the database? Are all of those other programmers aware of the rules that are so lovingly coded in our RPG programs? Do they know that you shouldn't delete a customer if there are outstanding invoices? Do they know that a status code of "C" is not allowed if the customer balance is greater than the credit limit?
The solution has been at hand for quite a while (V3R1), but most of us didn't delve into it too much because we were already doing the hard work in our RPG programs. In this article, I will discuss database constraints—how to define and maintain them and how they can help reduce the amount of coding required in your RPG programs while decreasing the risk of database corruption from other sources.
What Are Constraints?
There are three types of constraints: key constraints, foreign key constraints, and check constraints.
- A key constraint is used to prevent duplicate information on a table. This corresponds to first normal form for a relational database (define the key). Key constraints are a prerequisite for foreign key constraints.
- A foreign key constraint (also referred to as referential integrity) defines a relationship between two tables: a dependant and a parent. A foreign key constraint ensures that rows may not be inserted in the dependant table if there isn't a corresponding row in the parent table. It also defines what should be done if a row in the parent table is changed or deleted (more details in a moment).
- A check constraint defines the rules as to which values can be placed in a column.
There are commands available for dealing with constraints on green-screen (ADDPFCST, CHGPFCST, DSPCPCST, EDTCPCST, RMVPFCST, WRKPFCST), or you can define them in SQL using the CREATE TABLE or ALTER TABLE commands.
But by far the easiest ways of handling constraints is using the Database function in iSeries Navigator. You can define constraints by selecting Database > System > Schemas > Your Schema > Tables. (In case you are not yet familiar with SQL terminology, a schema is a library and a table is a physical file.) Right-click on a table name and select Definition; the resulting window contains a tab for each type of constraint, as shown in Figure 1. On each of these tabs, you have options for Add, Remove, and Definition. The Definition option simply shows you the definition of the constraint; in order to change the definition of a constraint, you must remove it and add it again. The examples shown in these figures are taken from the database we use in the management of the RPG & DB2 Summit conference.

Figure 1: Define constraints. (Click images to enlarge.)
Key Constraints
Figure 2 shows the definition of a key constraint. You provide a name for the constraint, specify whether it is a primary key or a unique key constraint, and identify the columns used to construct the key.
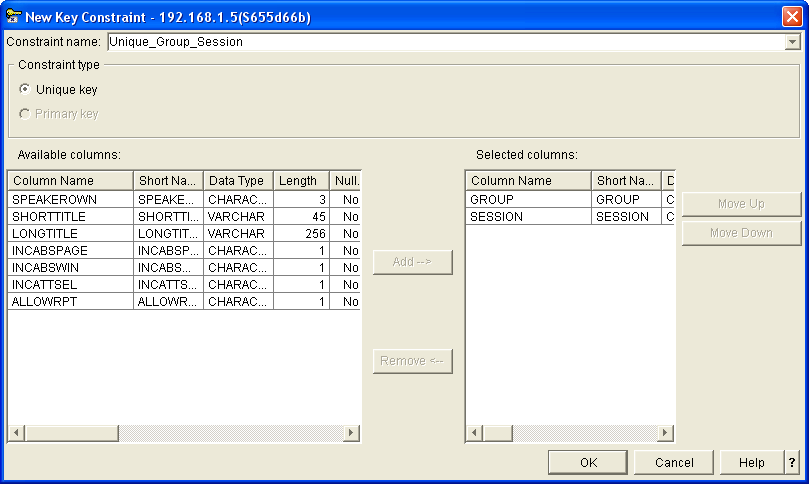
Figure 2: Define key constraints.
For any table, you may define one primary key constraint and as many unique key constraints as required. Normally, each table should at least have a primary key constraint that identifies the main key for the file. Note that constraints are not objects; therefore, you're not confined to 10 characters for the constraint name, so you can give your constraints descriptive names.
Defining a key constraint results in the creation of an access path but not a logical file. This access path will be available for sharing with any indexes (or logical files) that are created at a later stage.
Foreign Key Constraints
A foreign key constraint defines a relationship between a dependant table and a parent table. For example, in the relationship between the invoice table and the customer table cited above, the invoice table is the dependant and the customer table is the parent. Foreign key constraints are defined for dependant tables.
Figure 3 shows the definition of a foreign key constraint. You provide a name for the constraint and identify the parent table, the key constraint of the parent table to be used, the fields in the dependant that correspond to the fields on the selected key constraint, and the delete and update rules to be used.
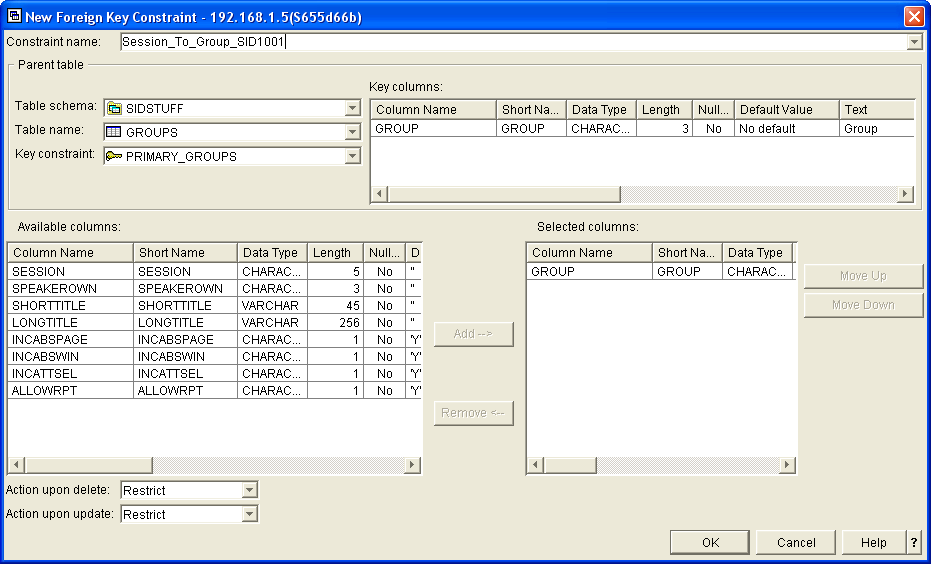
Figure 3: Define foreign key constraints.
Using a foreign key constraint is very much like defining a join logical between two files.
In the example shown in Figure 3, the seven characters at the end of the constraint name are a message ID. This is a technique I use to provide helpful information about the constraint when an application program causes a violation. (This technique is described later in the article.)
The main reason for defining a foreign key constraint is to select the relevant delete and update rules. These are the possible delete rules:
- Restrict means rows cannot be deleted from the parent table if there are corresponding rows on the dependant table.
- Cascade means the row may be deleted from the parent table and all corresponding rows on the dependent table will be deleted automatically.
- Set Null is very much like the cascade rule except that null-capable columns, in the dependant key, are set to null as opposed to the dependant row being deleted.
- Set Default is very much like the cascade rule except that columns in the dependant key are set to their default values as opposed to the dependant row being deleted.
- No Action is the same as the restrict rule; however, triggers will be fired before checking foreign key constraints.
The possible update rules are Restrict and No Action, and the Insert rule is implicit (no rows may be inserted in a dependant table if there are no matching parent rows).
All rules except Restrict require that both the parent and dependant files are journaled to the same journal. Take a moment to consider a Cascade delete rule. Your program deletes a customer (from the parent customer table), and the database manager deletes 200 corresponding invoices (on the dependant invoice table). You can see why the need for journaling.
Both the parent and dependant files must be single-member, externally defined files. As with key constraints, a referential constraint results in the generation of an access path but not a logical file.
Check Constraints
Check constraints allow you to define validation for columns in a table. This validation is performed every time a row is inserted or updated in the table.
The nearest to this in DDS are the COMP, RANGE, and VALUES keywords, but they apply only to display files. And they come nowhere near the power of what you can do with check constraints.
Figure 4 shows the definition of a check constraint.
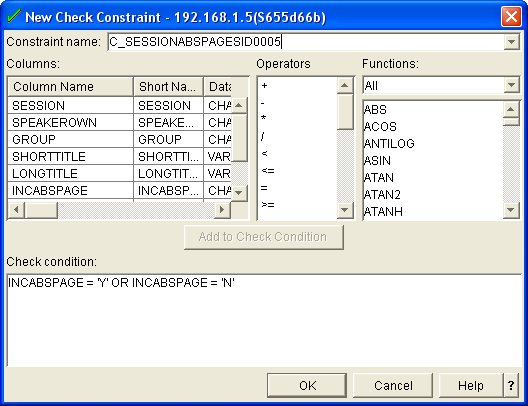
Figure 4: Define check constraints.
If you're already familiar with SQL, you can simply key in the check condition; alternatively, you can build the check condition by using the Add to Check Condition button to add a selected column name, operator, or function.
A check condition can range from simple conditions such as checking that the value entered is one in a specific set (as shown in the example in Figure 4) to complex conditions such as making comparisons in the values between different columns in the row. For example, an employee table might contain a check condition to ensure that employees are over the age of 17 when they join the company: YEAR ( JOINEDDATE - BIRTHDATE ) > 17.
Check constraints remove an incredible amount of code from our RPG programs.
Managing Constraints
Having a whole lot of constraints defined is marvelous, and they ensure the integrity of the database no matter who is trying to access it or where they are trying to access it from. But there is a price to pay if you wish to perform a batch process on the database because all of the constraints will be checked every time a row is inserted, updated, or deleted.
But you can have the best of both worlds! If you perform a batch process, you can simply disable any constraints and then re-enable them once the batch process is completed. When you re-enable the constraints, all of the rows are checked to ensure that they do not violate a constraint. If a row violates a constraint, your table is put in a "check pending" state. This means that the table may not be accessed for update until the problem has been corrected.
Again, the easiest way to manage constraints is from iSeries Navigator. The constraints option for a schema lists all constraints defined for that schema. The context menu for a constraint allows you to enable or disable it, as shown in Figure 5, and it will also have an option to allow you to edit rows in a check pending state if the constraint has caused a check pending violation.

Figure 5: Manage constraints from iSeries Navigator.
In this example, I have disabled a check constraint that ensures that the value entered for a field is Y or N. I then inserted a row that contains an invalid value for that column and re-enabled the constraint. Of course, when the constraint is re-enabled, the table is placed in a check-pending state. Taking the option to edit a check-pending constraint results in the window shown in Figure 6, where I can now correct any of the columns that may be causing a violation.

Figure 6: Correct columns causing violations.
Violating Constraints
How does a program know it has attempted to violate a constraint? The database manager generates a file error, which you trap in your program.
- ILE RPG—Use the %Error BIF with an E extender on the operation code and check for status codes 01222 and 01022.
- ILE COBOL—The file status is 9R.
- ILE C—Errors are mapped to existing error numbers.
- SQL—Check for SQLCODES 530, 531, and 532.
Now, instead of having code in your programs, which performs field validation or checks for integrity with other tables, all you have to do is check for an I/O error when you perform a write, update, or delete. The problem is determining which constraint caused the violation and providing a meaningful explanation as to why the operation failed.
When a program receives an I/O error or a constraint violation, the procedure message queue will contain a message whose second-level message text identifies the name of the constraint that caused the violation. You need to use the QMHRCVPM API to read back through the procedure message queue—looking for one of the message IDs CPF502D, CPF502E, CPF502F, CPF503A, or CPF503B—and extract the constraint name from position 177 of the message data.
This brings me to the technique I mentioned earlier. Since the last seven characters of the constraint name are a message ID, I wrote a procedure that retrieves the constraint name and then uses the last seven characters as a message ID to resend a more meaningful message.
Figure 7 shows a snippet of code with an error being trapped on an UPDATE operation in an RPG program, which results in a call to the subprocedure SndFileError().
|
Figure 7: A trapped error causes a call to subprocedure SndFileError().
SndFileError() checks the status code passed as a parameter and, if it is a constraint violation (Status = 01022 or Status = 01222), calls the subprocedure SndConstraintMsg(), which performs the actions described above.
AddMessage() is another subprocedure, which simply sends a message.
A Last Word...
As well as ensuring the integrity of your database when outside influences are allowed to update it, constraints can also make life a lot easier when it comes to coding traditional programs; it means a lot of code can be removed.
And here is a final thought: Why not try defining a constraint on one of your existing databases and seeing just how good the data is? Has your application been doing the job properly all these years?
Paul Tuohy has worked in the development of IBM Midrange applications since the ’70s. He has been IT manager for Kodak Ireland Ltd. and Technical Director of Precision Software Ltd. and is currently CEO of ComCon, a midrange consultancy company based in Dublin, Ireland. He has been teaching and lecturing since the mid-’80s.
Paul is the author of Re-engineering RPG Legacy Applications, The Programmer's Guide to iSeries Navigator, and the self-teach course “iSeries Navigator for Programmers”.
He is one of the partners of System i Developer and, as well as speaking at the renowned RPG & DB2 Summit, he is an award-winning speaker at US Common and other conferences throughout the world.
Paul may be contacted at

Paul Tuohy has worked in the development of IBM midrange applications since the 1970s. He has been IT manager for Kodak Ireland, Ltd., and technical director of Precision Software, Ltd., and is currently CEO of ComCon, a midrange consultancy company based in Dublin, Ireland. He has been teaching and lecturing since the mid-1980s.
Paul is the author of Re-engineering RPG Legacy Applications, The Programmer's Guide to iSeries Navigator, and the self-teach course "iSeries Navigator for Programmers." He is one of the partners of System i Developer and, in addition to speaking at the renowned RPG & DB2 Summit, he is an award-winning speaker at COMMON and other conferences throughout the world.
MC Press books written by Paul Tuohy available now on the MC Press Bookstore.
 |
The Programmer’s Guide to iSeries Navigator Get to know iSeries Navigator and all the powerful tools and interfaces that will expand your programming horizons. List Price $74.95 Now On Sale
|




 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online