















We've been using XML data in our relational world; now let's turn the tables.
The previous "Practical SQL"articles have followed a theme of accessing your XML data in a relational way. Every article led us a little further down that path, and future articles will continue to do so. I've got a way, for example, to easily create a relational table from an XML document with a single line statement that you'll really love. But for now, I'd like to take a little detour and show the other side of the world: creating XML data from your relational files.
Why Again Are We Using XML?
Last time, I suggested that nobody stores their data solely in XML. At the same time, there's almost no business today that doesn't use XML at all. Most often, XML is used for communicating, whether between programs or between business partners. More and more, XML is becoming the communication protocol of choice between computers because it combines a strict, easily validated syntax with an almost limitless customizability. As long as your tags are set up correctly, you can use XML to transmit just about anything. Personally, I draw the line at binary data because I think there are better vehicles, but if the data is any sort of textual information (including numeric fields), then XML is something nearly everyone can agree on.
That agreement means that XML does a great job as a replacement for a couple of our old standbys: flat files and comma-delimited text files. Both have served us well over the years (decades!), but both are a little long in the tooth. Do you really want to have to sift through a whole set of records looking for the letter M in position 12 to find a particular record? Or even worse, have to count commas to find the 16th field in a record starting with "HDR"? The latter technique gets especially fun when you have to remember not to count the commas that are embedded inside of quoted strings. XML isn't always easy because of the non-positional (and hierarchical) nature of the data, but with the tools we've been getting acquainted with in these articles, you can see that it's actually getting pretty easy to extract data from an XML file. But what about getting data into XML? Well, that's today's topic!
Converting from Relational to XML
As always, we'll continue to use the appliance that we installed back in the first article and draw from the data supplied there. We're going to do two simple things: create an XML element from a relational field and then create a complex XML tag from a record. Creating an XML element is simple; the XMLElement function does precisely that:
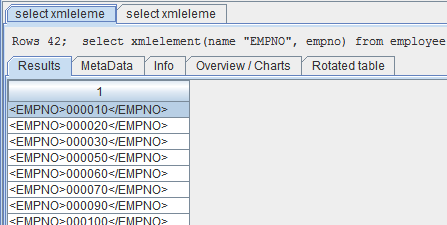
Figure 1: The XMLElement function embeds relational data within an XML element.
As you can see in Figure 1, the XMLElement function takes relational data (in this case, the employee number) and surrounds it with an opening and closing tag. The value of the enclosing tag is the first argument to the XMLElement function, and it must be preceded by the keyword "NAME". The second argument to the function is the expression that describes the data. The data is converted to a chaarcter expression and then embedded within the tag.
You can actually embed multiple pieces of relational data this way by nesting the XMLElement function:
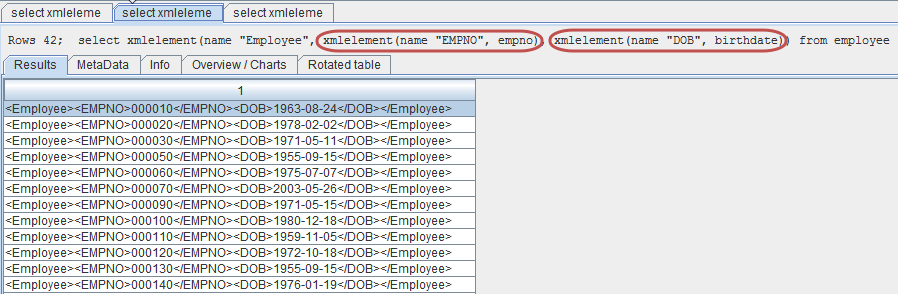
Figure 2: The XMLElement function can take multiple data arguments, each of which can in turn be an XMLElement.
In Figure 2, you'll see an XMLElement function with three arguments. As in Figure 1, the first element is the name of the enclosing tag. But then you'll see two more arguments, each of which is itself an XMLElement, each transforming a relational field into an XML tag. Specifically, the Employee element is the outer tag, which contains the inner tags of EMPNO and DOB. Note especially that the tag name does not have to be the same as the column name; it can be any valid XML tag name.
The XMLElement is a powerful function that allows you to completely tailor the data, defining not only the content of the tag but the attributes as well. You add attributes to your tags using the XMLAttributes function.
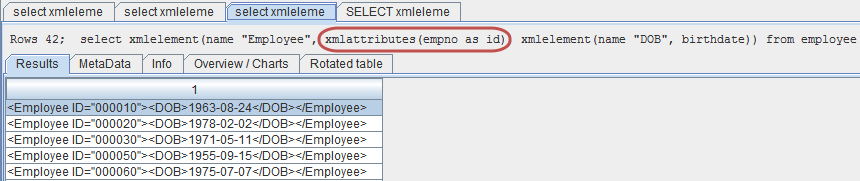
Figure 3: The XMLAttributes function can be used to move data into the attributes of the tag.
In Figure 3, I've moved the employee number from an embedded tag to an attribute of the Employee tag. As always, I can rename the attribute as I please, although you should note that the tag will default to uppercase. In this instance, the uppercase value of ID is fine, but I might want to use mixed case for other tags; to do that, I would enclose the tag name in double quotes. Let me do that for our last example, which also introduces the XMLForest function. Because the SQL statement is a little longer than the other, I'm going to show it separately.

Figure 4: This is an SQL statement using XMLForest.

Figure 5: These are the results of the previous SQL statement.
The final SQL statement in Figure 4 combines several things we've learned and adds the XMLForest function. The first line tells us that we're creating an XML tag named Employee. The last line tell us we're creating one of these tags for every record in the employee file where the field workdept starts with the letter A (that's the LIKE clause). This was just meant to show that even though we're creating XML using the fancy new XML functions, underneath it's still the standard SQL syntax we know and love.
In between those two is the meat of the tag, which includes one line for the attributes and one for the tag data. We've only defined a single attribute, ID, whose value comes from the field empno. Since we didn't enclose the tag name in double quotes, it will be rendered in uppercase. The new function is the XMLForest function, which takes as its argument a list of expressions. Each expression selects the data for a tag with the AS clause identifying the actual tag name. Since we've specified three arguments, that means the Employee element will have three nested elements, and the use of double quotes means the first two will be First and Last, while the last tag, being unquoted, will be uppercase DOB. So for every record, you have an XML element with an outer tag of Employee with an attribute of ID and three inner tags of First, Last, and DOB.
While perhaps not as simple as the CPYTOIMPF command, this translation is eminently flexible and allows you no end of creativity. It is also very fast. So get out your DB2 appliance and have some fun generating XML!

Joe Pluta is the founder and chief architect of Pluta Brothers Design, Inc. He has been extending the IBM midrange since the days of the IBM System/3. Joe uses WebSphere extensively, especially as the base for PSC/400, the only product that can move your legacy systems to the Web using simple green-screen commands. He has written several books, including Developing Web 2.0 Applications with EGL for IBM i, E-Deployment: The Fastest Path to the Web, Eclipse: Step by Step, and WDSC: Step by Step. Joe performs onsite mentoring and speaks at user groups around the country. You can reach him at
MC Press books written by Joe Pluta available now on the MC Press Bookstore.
 |
Developing Web 2.0 Applications with EGL for IBM i Joe Pluta introduces you to EGL Rich UI and IBM’s Rational Developer for the IBM i platform. List Price $39.95 Now On Sale
|
|
 |
WDSC: Step by Step Discover incredibly powerful WDSC with this easy-to-understand yet thorough introduction. Now On Sale
|
|
 |
Eclipse: Step by Step Quickly get up to speed and productivity using Eclipse. Now On Sale
|




 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online