















XML is great for hierarchical data, but sometimes you still need a plain old table, and this article will show you how to build one.
Last time, we took a little segue into creating XML from relational data. Now it's time to return to the other direction, making relational tables from XML data. XML can easily support a complex nested relationship of data with both optional and repeating elements, but that doesn't always translate very well to the relational world in which the data is presented as nice tables of rows and columns. In this article, I'll introduce you to the techniques you can use to turn hierarchies into grids.
XML Versus Relational—A Story of Structure
The real thing I've been trying to do in all of these articles is to compare how data is stored in XML as opposed to our more traditional relational data approach, and how to exploit the differences by building on the similarities. The subject of this article is the XMLTable function, which in a lot of ways really defines how these two data storage techniques equate to one another.
Let's start by taking a look at a standard XML structure. Like all the data in these articles, the data comes from the DB2 appliance that we installed way back at the beginning of the series. You could certainly create your own, but it's nice to have common ground to start from. In this case, the common ground is a purchase order, the XML for which looks like this:
<PurchaseOrder
PoNum="5003"
OrderDate="2005-02-28"
Status="UnShipped">
<item>
<partid>100-100-01</partid>
<name>Snow Shovel, Basic 22 inch</name>
<quantity>1</quantity>
<price>9.99</price>
</item>
</PurchaseOrder>
This data resides in a column named PORDER in the table PURCHASEORDER. Yes, I know it's not a traditional 10-character file name, but SQL support on the IBM i allows you to easily get around the constraints for both file and field name. Of course, that means that sometimes people go crazy and create fields like ThirdQuarterInvoiceSubtotalForTemporaryTaxCalculations, but that's a different issue. Anyway, the files and fields are already defined in the appliance, and they're fine. So let's take a look at the data. We see that the highest-level tag is PurchaseOrder, which has several attributes: PoNum, OrderDate, and Status. Unlike relational data, where each element has its own column, or flat files where data is in specific locations, the data in an XML stream can come from anywhere within the document, subject to the syntactical rules of XML, which primarily revolve around surrounding data with tags. The attributes are a little different in that they are simply the keyword and the data joined by an equals sign (=), but the basic concept still applies: the name of the data is provided along with the data itself.
Then it can get very interesting. In this case, nested within that is an element named item, which we'll return to later. Just think about it for a moment, though; there could easily be zero, one, or a hundred item tags. That's where the straight one-to-one correspondence between an XML document and a single relational table beak down. I'll talk a little more about multiple instance tags before the article ends, but for now let's concentrate on the attributes and see just how we can express those attributes as a table.
Using the XMLTable Function

Figure 1: The XMLTable function extracts attributes and elements and converts them to relational columns.
This one figure is jam-packed with information that may not be entirely intuitive at first glance. First, the select statement at the top tells you that we're going to be selecting some columns from the table purchaseorder, but that the columns will come from something we will define later and name xt (which stands for XML table). We're going to show all the columns from xt. The comma then segues into the actual XMLTable definition, which does quite a bit of work even in this simple example. The first parameter defines the path to the document, which starts first with a value preceded by a dollar sign. That value, $po, says that very soon you're going to define "po" as something that contains XML, and sure enough that happens in the next clause: passing porder as "po". That phrase says find the relational field porder; it will have XML in it and the top-level element will be named PurchaseOrder. Note that if the XML doesn't start that way, you won't get any rows.
The next clause starts with the keyword columns, which is appropriate, since it defines the columns being extracted from the XML. The first one is named OrderDate, and it comes from the attribute also named OrderDate. Similarly, the column Status comes from the tag Status. These column names do not have to match the tag names, but the tag name (the one following the path keyword) must match the tag in the XML. Also note that in this case, since OrderDate and Status are attributes and not elements, the attribute name is preceded by @. I still don't understand that, but it seems to be pretty standard through all the XML/SQL syntax: attribute names are preceded by @.
Done correctly, the XML will generate a nice table of data.
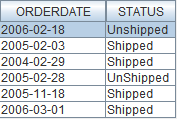
Figure 2: This is the result of the XMLTable function in Figure 1.
This is nice, but it has one shortcoming; it shows only XML data. The result doesn't include any non-XML elements from the record. Our simple table contains, in addition to the XML field named PORDER, a number of traditional relational data fields. One of those is the POID field, which holds the PO number. This field is a duplicate of the PoNum attribute, but it will serve our purpose here of showing just how easy it is to combine relational data with XML elements.

Figure 3: The XMLElement function embeds relational data within an XML element.
Here's a simple change that includes the POID field from the original record. You can see the statement is hardly changed, and it now includes a column from the relational table, as shown in the next figure.
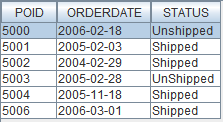
Figure 4: Adding the POID field in the statements yields the results you might expect.
Astute eyes might notice that I also changed the definition of the extracted OrderDate data. You can specify whatever type you like and, as long as the data in the element can be converted to the selected type, XML will do the conversion for you. You need to be careful with this as you would with any automatic conversion; if the data in the tag is bad, the selection will fail miserably.
That's it for this article. It really only scratches the surface of XMLTable. Subsequent articles will cover everything from handling multiple lines to using this syntax within a view: it can be very handy for selecting and sorting data from large XML documents. I hope this article convinces you to stay tuned for the upcoming ones!

Joe Pluta is the founder and chief architect of Pluta Brothers Design, Inc. He has been extending the IBM midrange since the days of the IBM System/3. Joe uses WebSphere extensively, especially as the base for PSC/400, the only product that can move your legacy systems to the Web using simple green-screen commands. He has written several books, including Developing Web 2.0 Applications with EGL for IBM i, E-Deployment: The Fastest Path to the Web, Eclipse: Step by Step, and WDSC: Step by Step. Joe performs onsite mentoring and speaks at user groups around the country. You can reach him at
MC Press books written by Joe Pluta available now on the MC Press Bookstore.
 |
Developing Web 2.0 Applications with EGL for IBM i Joe Pluta introduces you to EGL Rich UI and IBM’s Rational Developer for the IBM i platform. List Price $39.95 Now On Sale
|
|
 |
WDSC: Step by Step Discover incredibly powerful WDSC with this easy-to-understand yet thorough introduction. Now On Sale
|
|
 |
Eclipse: Step by Step Quickly get up to speed and productivity using Eclipse. Now On Sale
|




 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online