
















Let's continue our exploration of how to build very large spreadsheets.
By Giuseppe Costagliola
As I promised in my previous article, "TechTip: SQL2XLSX - The Starter Kit," I'm back to present an enhanced version of the utility that I hope you find useful.
If you ever tried to create a medium- or large-sized Excel spreadsheet, you realized that creation time increases dramatically as the number of rows increases, and maybe you even had to cancel the job because it never ended. This happens because the original version relies on an Apache POI XSSF API implementation, which gives access to all rows in the document, which are kept in memory until the end, and the heap space is not enough to let them fit inside.
However, Apache POI provides a low-memory footprint SXSSF API built on top of XSSF. SXSSF is an API-compatible streaming extension of XSSF to be used when very large spreadsheets have to be produced and heap space is limited. SXSSF achieves its low-memory footprint by limiting access to the rows that are within a sliding window.
Furthermore, in auto-flush mode, the size of the access window can be specified to hold a certain number of rows in memory. When that value is reached, the creation of an additional row causes the row with the lowest index to be removed from the access window and written to disk.
The window size can be set to grow dynamically, and it can be trimmed periodically by an explicit call to flushRows(numberOfRows) as needed. When a new row is created via createRow() and the total number of unflushed records would exceed the specified window size, then the row with the lowest index value is flushed and memory freed.
You can check the flush from the Display Call Stack of the QJVAEXCEL job:
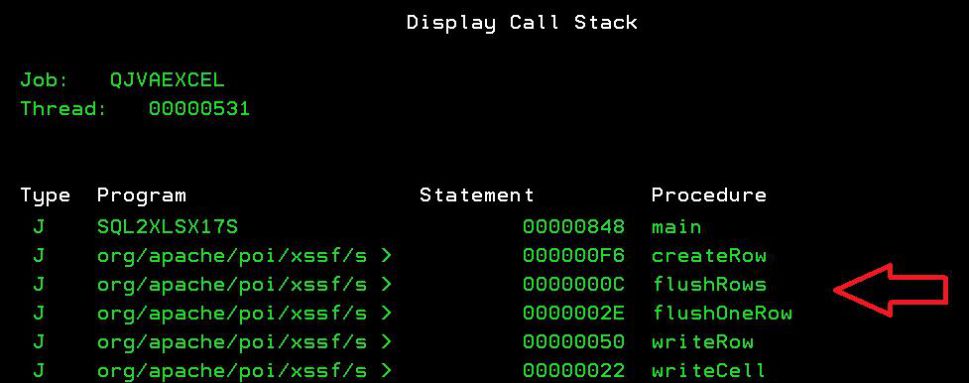
Figure 1: Flush the rows.
SXSSFWorkbook APIs default to using inline strings instead of a shared strings table. This is very efficient, since no document content needs to be kept in memory. This allows any IBM i, regardless of its memory capability, to easily reach the one-million-rows limit. Of course, if you have a little box, creation of large spreadsheets will require more time, but you'll never crash the system as you certainly do now with the XSSF standard version.
I've tried to create a large XLSX on a small V7R1 IBM i:
SQL2XLSX SQLSTMT('select * from bigfile')
TOXLS('/home/costagliol/sql2xlxss.xlsx')
COLHDRS(*LABEL)
FREEZE(*YES)
SETLIBL(*LIBL)
COMPRESS(*YES)
JDEBUG(*YES)
These are the results (it's a really good elapsed time, though):
select * from bigfile
Connecting to LOCALHOST with "com.ibm.db2.jdbc.app.DB2Driver"
0 hour(s) 4 minute(s) 19 second(s)
Writing /home/costagliol/sql2xlxss.xlsx
591953 Rows x 121 Columns
0 hour(s) 6 minute(s) 41 second(s)
SXSSF flushes sheet data in temporary files (a temp file per sheet), and the size of these temporary files can grow to a very large value. For example, with 20MB of CSV data, the size of the temp XML becomes more than a gigabyte! If the size of the temp files is an issue, you can tell SXSSF to use gzip compression; the SQL2XLSX has a new parameter, COMPRESS(*YES|*NO), to force compression of temporary files (which could make the entire process a little slower).
There are some cases, however, when the XSSF is more efficient - for example, when you create a multisheet, where the final document may have a significantly lower size.
Therefore, you can keep both versions on, and the enhanced command SQL2XLSX now has another new parameter, STREAM (*YES|*NO, that can run in either XSSF (no streaming) or SXSSF (streaming) mode.
The SQL2XLS of my previous article relied on Apache POI 3.9, so it can run on any IBM i release from V5R3 forward. However, at the time of this writing, the latest stable release is POI 9.17. It is difficult to stay current with the latest POI library updates, as there are new releases at least twice per year, and quite often each new release changes some API interfaces and requires our code to be modified accordingly. But because POI 3.17 is the last release to support Java 6 and the next release will be 4.0.0 supporting a minimum of Java 8 (requiring at least IBM i V7R1), I decided to update the SQL2XLSX to have it run with POI 9.17. Just note that the Java source code included in the zip file will not compile and run on earlier POI releases.
Installation steps of this enhanced version of SQL2XLSX are more or less as outlined in my previous article, "TechTip: SQL2XLSX - The Starter Kit."
Follow the instructions hereafter to set up the new SQL2XLSX version.
Create a subfolder POI-3.17 to contain the new jars with MD DIR('/excel/poi-3.17').
Connect to the download section of the Apache POI - The Java API for Microsoft Documents site and download the latest stable release of Apache POI 3.17 on your desktop.
Extract and copy the following jars into the subdirectory /excel/poi-3.17 you just created:
poi-3.17.jar
poi-ooxml-3.17.jar
poi-ooxml-schemas-3.17.jar
In the folder ooxml-lib in the downloaded zip file, you will find the following jar file that you should also extract and copy into your subdirectory:
xmlbeans-2.3.0.jar
You also need an additional jar that is not part of the POI distribution.
Connect to https://commons.apache.org/proper/commons-collections/download_collections.cgi, download the commons-collections4-4.1-bin.zip, and unzip and copy the commons-collections4-4.1.jar file into your subdirectory.
Then, just to make sure that the required jars are in the right place, use this command to check:
DSPLNK OBJ('/excel/poi-3.17/*') DETAIL(*NAME)
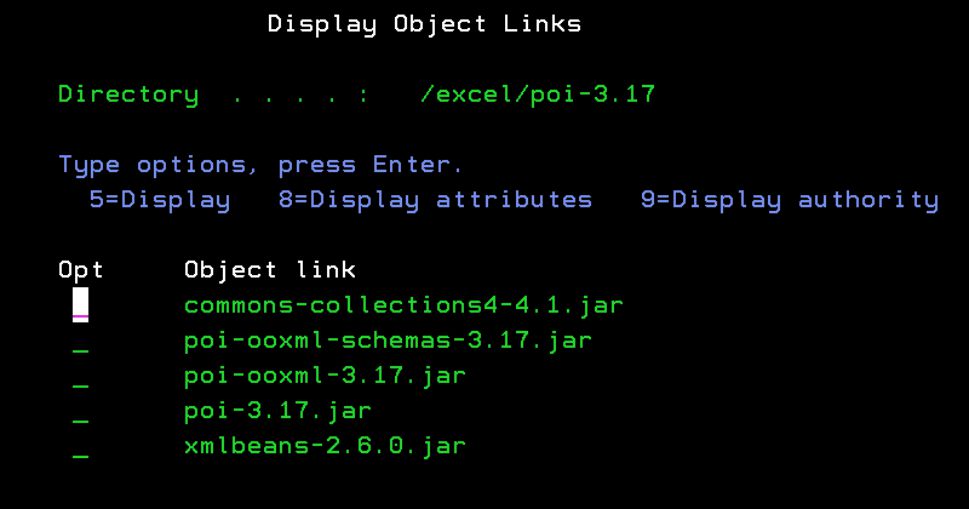
Figure 2: Ensure that your jar files are in your subdirectory.
Now download the zip file into your desktop.
Extract and copy SQL2XLSX(CMD), SQL2XLSXC (CLLE), and SQL2XLSXR (RPGLE) into a source file and compile as usual. Remember to create the SQL2XLSX command with parameter PGM(SQL2XLSXC).
Extract the SQL2XLSX17N.java and the SQL2XLSX17S.java source files into the /excel directory and create the corresponding two .class files; you can use the enclosed QSH script (SQL2XLSXJ.CLP).
That's all. Now you should be able to create your very big XLSX worksheets.
As I mentioned, the SXSSF (streaming) mode leads to some limitations, especially when using templates. Keep in mind that an XLSX/XLSM template must be loaded in memory before adding rows or sheets. Therefore, you can't for example create a multisheet XLSX having one million rows each because your system could never load it. If you use a header template, you can't automatically write new rows past the existing header rows as done in the standard version because the number of existing rows is not known, and you have to manually specify the number of rows to skip in the command parameter BLANKROWS.
Apart from this, I hope that this utility will suit all your needs.



 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online