















XML represents a fundamental change in computing. It allows applications to move away from proprietary file and data formats to a world of open data interchange. XML has become ubiquitous not only because of its range of applications, but also because of its ease of use. Its text-based nature makes creating tools easy, and since it is an open, license-free, cross-platform standard, anyone can create, develop, and use tools for XML. In short, XML means portable data.
Although XML solves many problems by providing a standard format for data interchange, some challenges remain. In the real world, applications need reliable services to store, retrieve, and manipulate data. These services were traditionally offered by relational databases. The relational database technology has matured over the last 30 years, and it is well-known for its impressive SQL query performance, unequaled reliability and scalability, strong management and security, and legendary concurrency through locking and caching. So it would seem to be natural to use relational databases to persist and manipulate XML documents. Well, the problem is that relational and hierarchical representations of data are very different. In the relational model, the data is stored in rows of two-dimensional tables where the physical order of rows is insignificant. XML, on the other hand, is a highly hierarchical model where the order of elements is significant, and the relationship among elements is described in a given document. Using a relational model to express a hierarchy of elements in a complex XML document is a non-trivial task. Therefore, some software vendors decided to implement pure XML databases designed to efficiently handle the hierarchical model. Unfortunately, the native XML databases don't provide maturity, scalability, and concurrency of the relational databases yet. Another approach adopted by other software vendors is to programmatically process the XML documents and map their hierarchy into a relational database. Typically, these solutions leverage one of the standard APIs to manipulate XML, such as Simple API for XML (SAX) or Document Object Model (DOM). The JDBC is then used to write the extracted data into the database. Although the programmatic approach works fine in many cases, it also has serious limitations. It requires custom development for each XML schema, meaning that the structure of a given XML document type is hard-coded. So the code maintenance cost is usually very high. Every time the structure (schema) of an XML document changes, the respective code needs to be changed accordingly.
I believe that a much more productive approach is to use database middleware to handle the XML parsing and XML-to-relational mapping. Most database vendors provide this kind of functionality. DB2 UDB for iSeries, for example, provides DB2 XML Extender. DB2 XML Extender offers several advantages over the programmatic approach. It allows your development team to focus on business logic implementation rather than on mastering low-level APIs such as SAX or DOM. In addition, the XML-to-relational mapping is greatly simplified by a visual mapping utility provided in IBM's WebSphere Studio Application Developer (WSAD), Rational Application Development (RAD), and WebSphere Development Studio Client (WDSc) Integrated Development Environment (IDE).
In this article, I will demonstrate how to take advantage of the XML Extender and WSAD tooling to dramatically speed up the process of building robust XML-based applications. I'll also share best practices and techniques aimed at streamlining the XML-DB2 integration.
Note: I'm assuming that you are already familiar with basic XML-related concepts such as Data Type Definition (DTD), XML Schema (XSD), and location path. If not, you may check out the online W3 Schools tutorials web site. In this article, I focus only on the functionality specific to XML Extender.
DB2 XML Extender Basics
The DB2 XML Extender for iSeries, which consists of several components, is not a part of the DB2 UDB for iSeries runtime. It is shipped as a separate license program (5722-DE1) and needs to be ordered from IBM as a chargeable feature.
DB2 UDB stores and retrieves XML data and also generates helper side tables that can greatly improve the performance of the XML retrieval process. The extender, which mediates between DB2 UDB and the application requester, is functional and flexible whether you have relational data that needs to be transformed into XML or XML data to store in DB2 UDB tables. It contains a rich set of user-defined types (UDTs), user-defined functions (UDFs), and stored procedures to manage XML data. XML documents can be stored in DB2 UDB databases as character data. These concepts are illustrated in Figure 1.
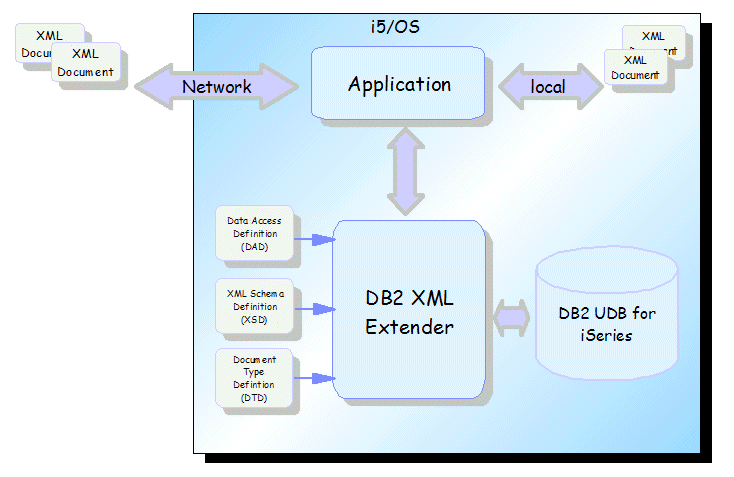
Figure 1: The DB2 XML Extender allows you to transform relational data into XML or store XML data in DB2 UDB tables. (Click images to enlarge.)
The DB2 XML Extender provides you with the ability to use DB2 UDB to store, manage, query, and update XML data. Two basic techniques are used:
- XML column method
- XML collection method
With the XML column method, you can use DB2 UDB tables to store XML documents in columns that have been enabled for XML, or you can store them as external files. The XML data can then be retrieved, updated, and searched. Furthermore, you can extract XML element or attribute values into secondary tables, called side tables, which, when indexed, provide fast XML element and attribute search capabilities. Columns that have been enabled for XML are known as XML columns and can be implemented as one of the three user-defined types provided with the XML Extender:
- XMLVARCHAR
- XMLCLOB
- XMLFILE
The XML collection method allows you to compose XML documents from existing DB2 UDB data or decompose (shred) XML documents into DB2 UDB data--that is, store untagged element or attribute values in DB2 UDB tables.
One of the cornerstones of the extender's architecture is the Data Access Definition (DAD) document. The DAD specifies how to map the hierarchical structure of XML documents to the actual relational structure in the database. For example, if you have an element called
The XML Extender provides two types of mapping schemes: SQL mapping and Relational Database (RDB_node) mapping. Both methods use the XPath model to define the hierarchy of the XML document. My experience shows that, for most applications, the RDB_node mapping provides much richer functionality and better flexibility than the SQL mapping. In the RDB_node mapping, the relationship between XML elements and relational database columns is expressed by employing element_node (or attribute_node) to RDB_node associations.
Let's explore these concepts by examining the following excerpt from a DAD document:
GLBLSALES.COUNTRY.GLOBALSALESUID
...
In the DAD source listed above, [1] indicates that the XML Collection method is used. The top element_node at [2] represents the root element of the XML document. The RDB_node associated with the root element is used to specify all tables that are associated with the XML document. At [3], I list two tables necessary for mapping. In the condition tag at [4], I provide the join condition for the two tables. At [5], I use an attribute_node to associate an XML attribute with an RDB_node . This time, the RDB_node defines the column name, its data type, and the target table name. Note that the nesting of the attribute_node within the root_node reflects the hierarchy of the XML document. At [6], I use an element_node to associate the content of the element represented by a text_node with an RDB_node. The RDB_node defines the target column in the database table. Again, the nesting of the element_node within the root elements represents the hierarchy in the XML document.
XML Shred Walkthrough
Armed with the basic understanding of the DB2 XML Extender functionality, we can now analyze the shredding methodology that I have successfully implemented for several large projects. As mentioned, the purpose of shredding is to store untagged elements or attributes in DB2 UDB tables. The proposed end-to-end development and deployment process is illustrated in Figure 2.

Figure 2: Shredding stores untagged elements or attributes in DB2 UDB tables.
In the above figure, steps 1through 5 are performed in WSDC. Once the necessary application files are generated, the solution is deployed to the target iSeries server, where the application files are used as input to the XML Extender shred procedures. The development and deployment steps are described in the following sections.
Analyze the XML Document's Structure and Figure Out the Mapping
I use a sample XML document called GlobalSales.xml as an input to the shredding process (source code contained in the Download Image. The document contains global sales data for various brands distributed in the retail stores throughout the world. First, the XML document is imported into a folder in a newly created Java project in WSAD. I use a Java project because the solution contains a simple Java program that needs to be compiled and tested. After you switch to the XML perspective, you can use the Outline view to analyze the hierarchy of the sample document. This is shown in Figure 3.
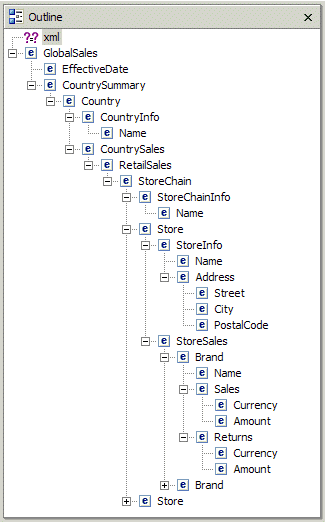
Figure 3: From the XML perspective, you can see the hierarchy of GlobalSales.xml.
Before you start the XML-to-RDB mapping process, you need to understand some fundamental concepts of XML technology:
- Containment--Some elements are fully contained in other elements. For example, in Figure 3, a Store element is contained in the StoreChain element that, in turn, is contained in RetailSales.
- Repeating Elements--Some elements may repeat within one parent element. For example, a StoreSales element can contain one or many occurrences of the Brand element. So there is a one-to-many relationship between StoreSales and Brand.
- Optional Elements--Some elements are optional. For example, a Returns element may occur zero times or one time within a Brand element. Optional elements are mapped to nullable columns in the database tables.
- Wrapper elements--These elements have no child attributes or text nodes. However, they contain children elements that have attributes or text nodes. For example, CountrySummary is a wrapper element. It has no attributes or text nodes. It is used to logically separate sales data from other elements.
In the proposed methodology, I assume that the target tables do not exist and that they need to be designed as part of the mapping process. In other words, during the mapping, I decide what tables and columns are needed to accommodate the data found in the XML document. Each text node or attribute of an element is mapped into a column in a table. Note that an element and all its children that cannot repeat can be mapped into columns of the same table. This is so because different columns in one row of a table correctly represent the one-to-one relationship between parent and child for those elements that cannot repeat. For example, each occurrence of a Store element can have just one occurrence of StoreInfo element, thus all data from Store and StoreInfo can be stored in one row. On the other hand, a child element that can repeat must be mapped to
a separate table. In this case, there is a one-to-many relationship between a parent and its children. The only way to reflect this relationship in a relational database is to store the parent element in a parent table and store the children elements in multiple rows of a dependent table. For example, a StoreChain element contains multiple Store elements, so the data for a particular occurrence of StoreChain can be stored in one row of a StoreChain table while children of this StoreChain element are stored in multiple rows of the Store table. This is illustrated in Figure 4.
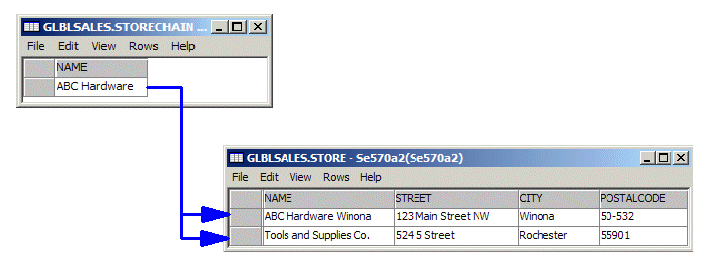
Figure 4: This is an example of a parent element and children elements that repeat.
I'll now employ the concepts I've explained so far to map out the GlobalSales.xml document. The Data Type Definition (DTD) for the sample XML document allows you to easily follow the XML hierarchy and find all elements that occur once, occur multiple times, or are optional. Here's the source of GlobalSales.dtd:
<!ELEMENT GlobalSales
(EffectiveDate,CountrySummary)>
<!ELEMENT EffectiveDate
(#PCDATA)>
<!ELEMENT CountrySummary
(Country+)>
<!ELEMENT Country
(CountryInfo,CountrySales)>
<!ELEMENT CountryInfo
(Name)>
<!ELEMENT CountrySales
(RetailSales)>
<!ELEMENT RetailSales
(StoreChain+)>
<!ELEMENT StoreChain
(StoreChainInfo,Store+)>
<!ELEMENT StoreChainInfo
(Name)>
<!ELEMENT Store
(StoreInfo,StoreSales)>
<!ELEMENT StoreInfo
(Name,Address)>
<!ELEMENT Address
(Street,City,PostalCode)>
<!ELEMENT Street
(#PCDATA)>
<!ELEMENT City
(#PCDATA)>
<!ELEMENT PostalCode
(#PCDATA)>
<!ELEMENT StoreSales
(Brand+)>
<!ELEMENT Brand
(Name,Sales?,Returns?)>
<!ELEMENT Sales
(Currency,Amount)>
<!ELEMENT Returns
(Currency,Amount)>
<!ELEMENT Currency
(#PCDATA)>
<!ELEMENT Amount
(#PCDATA)>
<!ELEMENT Name
(#PCDATA)>
The analysis starts at the root element, GlobalSales in this case. It has two children: EffectiveDate and CountrySummary. Both can occur only once. So I can map data from all three elements to a single table. For simplicity, let's call this table GlobalSales. Note also that GlobalSales and CountrySummary (a wrapper) contain no attributes or text nodes. Only EffectiveDate contains a text node. The CountrySummary, in turn, contains Country, which, as indicated by the plus sign (+) next to it, can occur one or more times. So Country needs to be mapped to a separate table. This leaves me with just one column in the GlobalSales table, namely EffectiveDate. Similarly, Country contains CountryInfo and CountrySales (a wrapper). The text node of element CountryInfo/Name cannot repeat, thus it is mapped into the Name column in the Country table. The process is continued recursively until all elements are mapped.
Three more elements can repeat: StoreChain, Store, and Brand (check out the + signs in the DTD). As a result, the mapping requires five tables: GlobalSales, Country, StoreChain, Store, and Brand. The following figure shows the layout of the target tables and their relationships. Sample data is provided to better illustrate the one-to-one and one-to-many relationships between rows.
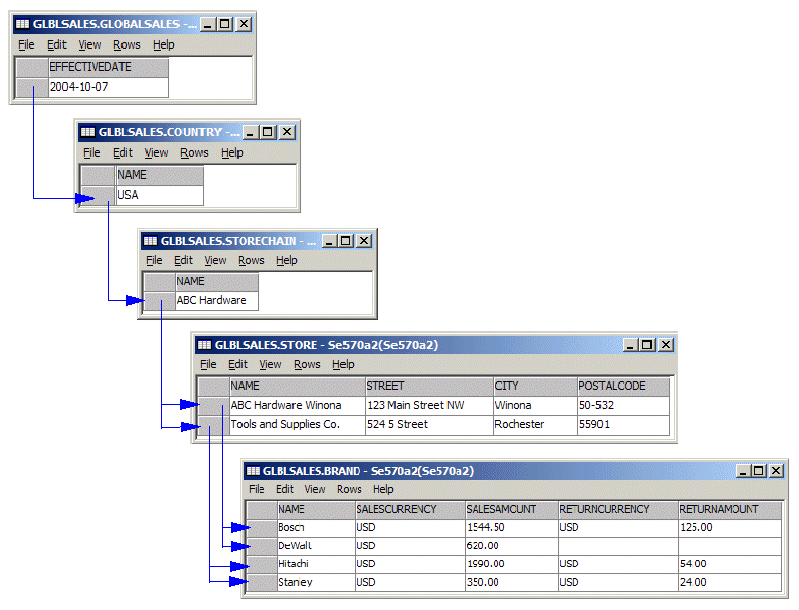
Figure 5: The layout of the example target tables looks like this.
In the above figure, the arrows indicate the hierarchy of the elements in the sample XML document mapped into a set of tables. For example, a Store named ABC Hardware Winona contains two Brand elements (Bosch and DeWalt). In other words, the arrows are needed to correctly reflect the containment and repeating elements.
Our discussion has reached the most critical aspect of hierarchical-to-relational mapping: How do we preserve the relationships represented by the arrows in Figure 5 in a relational database model? Referential integrity (RI) is probably the most natural choice, and, in fact, it is the cornerstone of the proposed methodology. In order to tie the related rows with the unique key/foreign key constraints, I need to insert unique key values into the designated elements. The key value uniquely identifies the given instance of an element, and at the shredding time, the extender will propagate the key value as a foreign key to the children elements that can repeat. That way, the children will be tied back to the parent element. The process of selecting the designated elements is pretty straightforward: I need to add a unique key to the GlobalSales element and then to all elements that can repeat--Country, StoreChain, Store, and Brand.
Use XSLTransform to Insert Unique Keys
The mapping process determined which elements need to contain the unique keys. I decided to use the XSL Transformation to insert the necessary values into the inbound sample XML document. I use the javax.xml.transform.Transformer class to apply the following simple XSL style sheet (see download for source code of the Java GlobalSalesTransform program):
xmlns:xalan="http://xml.apache.org/xslt">
At [1], the elements that need to contain a unique key are selected. At [2], a unique key is generated. The input parameter guuid is concatenated with the return value of the XSL generate-id() function to produce a unique value. For simplicity, I use the current timestamp as the input parameter. This guarantees the key uniqueness on consecutive invocations of the transformer. The newly generated unique key value is inserted as an attribute called Uid. All other nodes in the inbound document are just copied to the transformed XML document.
Here's an excerpt from the transformed GlobalSales_t.xml document:
...
Note the presence of the inserted attributes for the GlobalSales and Country elements.
Modify DTD or XSD
The original DTD needs to be modified to reflect the structure of the transformed XML document. The necessary change boils down to adding a new attribute called Uid to the designated elements. The DTD for the transformed XML document is used in step 5. Additionally, the DTD may be required if you decide to validate the inbound documents before shredding them into the database.
Once the DTD has been updated, I can use the WSAD's Generate XML Schema wizard to generate a corresponding XSD from the modified DTD. To do so, I right-click the GlobalSales_t.dtd in the Navigator window and select Generate -> XML Schema. The process outlined in this step is illustrated in Figure 6.

Figure 6: Use this process to modify DTD.
The XSD, in turn, serves as input to the Generate DDL wizard that is used in step 4.
Alternately, an existing XSD may have to be modified to reflect the structure of the transformed XML. XSD is better than DTD, because it more precisely reflects the data types for elements and attributes.
Create Target Tables
In step 1, I defined the layout of the target tables. Now it is time to create a DDL script that can be run on the database server to actually create the necessary tables. Once again, WSAD provides a handy wizard that can facilitate the process. I use the Generate DDL wizard to produce a "draft" DDL script from the modified XML schema (GlobalSales_t.xsd). To do so, I right-click the GlobalSales_t.dtd in the Navigator window and select Generate -> DDL. As indicated, the wizard provides only a rough guess as to what tables are needed to accommodate data contained in an XML document described by a given XSD. Despite the wizard's imperfection, I still prefer to use it rather than type the entire DDL script from scratch.
Typically, in the generated script, I need to remove unnecessary and redundant table and column definitions. Then I add to all tables the unique key constraints to accommodate the inserted Uid attributes. Next, starting from the GlobalSales and Country tables, I recursively express the one-to-many relationship between rows in two tables by specifying a foreign key in the dependent table. This is done by adding a new column to the dependent table with the same attributes as the unique key column in the parent table and defining it as a foreign key. This definition ties the two tables together.
Here's an excerpt from the modified SalesGlobal.sql script:
CREATE SCHEMA GLBLSALES;
SET SCHEMA GLBLSALES;
CREATE TABLE GlobalSales (
GlobalSalesUid CHAR(30)NOT NULL, <---------
EffectiveDate VARCHAR (80), |
PRIMARY KEY (GlobalSalesUid) |
); |
CREATE TABLE Country ( |
CountryUid CHAR(30) NOT NULL, |
GlobalSalesUid CHAR(30)NOT NULL, <-----------
Name VARCHAR (80),
PRIMARY KEY (CountryUid),
FOREIGN KEY (GlobalSalesUid) REFERENCES GlobalSales (GlobalSalesUid)
ON DELETE CASCADE ON UPDATE RESTRICT
);
In the above example, the GlobalSalesUid column in Country is a foreign key referencing the same-named column on the parent table. Note also that, in the foreign key definition, I specified the ON DELETE CASCADE rule. This will allow me, if needed, to remove all shredded data for a given XML document by deleting just one row in the GlobalSales table. DB2 will automatically remove all other related rows.
Note: Currently, the XML Extender does not provide the functionality to update the data once the document has been shredded. To perform the update, you could delete the data from the target tables and then shred again using the modified XML document.
Once the DDL script is cleaned up, I create the target tables by right-clicking on GlobalSales.sql in the WSAD's Navigator and selecting Run on the database server.
Build the DAD
WSAD provides a wizard that allows you to create RDB-to-XML mappings using graphical drag-and-drop editing. To invoke the wizard, I switch to the XML perspective and then select File -> New -> RDB-to-XML mapping. The wizard uses the target database meta data previously imported into the project (see the download materials for details) and GlobalSales_t.dtd as input. The mapping editor allows me to drag a column from a target table and drop it on an element or attribute in the XML structure. That way, I provide the information about the required mapping. The mapping editor session is shown in Figure 7.
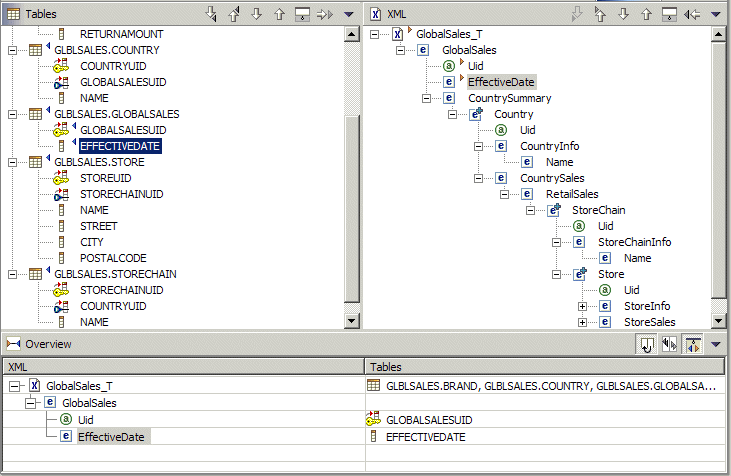
Figure 7: The RDB-to-XML mapping editor offers drag-and-drop functionality.
In the above figure, the upper left panel contains the list of target tables and their columns. The upper right panel contains the expanded structure of the XML document. The lower panel shows what mapping has been already defined.
In addition to column-to-element/attribute mapping, I also need to specify the join condition for the target tables. I use the unique key/foreign key pairs for that purpose. Here's the join condition needed for the target tables:
GLOBALSALES.GLOBALSALESUID = COUNTRY.GLOBALSALESUID
AND COUNTRY.COUNTRYUID = STORECHAIN.COUNTRYUID
AND STORECHAIN.STORECHAINUID = STORE.STORECHAINUID
AND STORE.STOREUID = BRAND.STOREUID
Once the mapping and the join condition are provided, I can generate the DAD by selecting Mapping -> Generate DAD in WSAD. Next, I verify that in the generated DAD file the multi-occurrence attributes are present for elements that repeat. Also, decomposing a wrapper element into one row requires a multi-occurrence attribute.
The WSAD's Generate DAD function automatically provides the necessary multi-occurrence attributes for repeating elements but not for the wrappers. Hence, you might need to manually modify the DAD. Check the Multi-occurrence requirements for wrapper elements technote for more info on that subject.
This concludes the development phase of the proposed methodology.
Deploy the Solution on the iSeries
I'm assuming that the XML Extender is already installed and enabled on the target iSeries server. To deploy the application, I need to copy the following files to the iSeries IFS: GlobalSales.xml, GlobalSales.xsl, GlobalSales_t.dad, GlobalSales_t.dtd, GlobalSales_t.xsd, and GlobalSalesTransform.java. Note that DTD and XSD files are needed only if the validation is required. I use the Export function in WSAD to copy all the files into an IFS directory called /dxx/Demo. To compile the Java source, JDK 1.4 or higher is required. You can check the default JDK version on your system by running the following command from the Qshell prompt:
The default Java version on V5R2 systems is 1.3.1; therefore, you need to change it to 1.4. To do so, create a stream file called SystemDefault.properties in your home directory--for example, /home/jarek. Add the following line to the properties file:
From now on, JDK 1.4 will be used for your user profile. Of course, this assumes that 57722-JV1 Option 6 is installed on your iSeries. The following command is used to compile GlobalSalesTransform.java:
javac GlobalSalesTransform.java
Additionally, I create an SQL stored procedure called ShredXMLWrapper in the target DB2 schema (GLBLSALES). The source of the stored procedure is listed below:
CREATE PROCEDURE GLBLSALES.SHREDXMLWRAPPER ( IN DAD_FILE VARCHAR(512),
IN XML_FILE VARCHAR(512),
OUT ERRCODE INTEGER,
OUT ERRMSG VARCHAR(1024) )
RESULT SETS 0
LANGUAGE SQL
SPECIFIC GLBLSALES.SHREDXMLWRAPPER
P1 : BEGIN
DECLARE DAD_BUF CLOB ( 102400 ) ;
DECLARE XMLOBJ CLOB ( 1048576 ) ;
SELECT DB2XML.XMLCLOBFROMFILE(DAD_FILE) INTO DAD_BUF FROM SYSIBM.SYSDUMMY1; [1]
SELECT DB2XML.XMLCLOBFROMFILE(XML_FILE) INTO XMLOBJ FROM SYSIBM.SYSDUMMY1; [2]
CALL DB2XML.DXXSHREDXML( DAD_BUF , XMLOBJ , ERRCODE , ERRMSG ) ; [3]
IF ERRCODE < 0 THEN
SET ERRMSG = 'ErrCode=' || TRIM ( CHAR ( ERRCODE ) ) || ' - ' || ERRMSG ;
SIGNAL SQLSTATE '70001' SET MESSAGE_TEXT = ERRMSG ;
END IF ;
END P1
At [1], the DAD file is read into a Clob variable. At [2], the XML file to be shredded is read into another Clob variable. At [3], the XML Extender stored procedure is called to perform the shredding. So the purpose of the wrapper is to read the DAD and XML from a file system and pass them to the XML Extender as Clobs.
Run the Application
Once the application is deployed, just a few easy steps are required to shred any number of XML documents that comply with GlobalSales.dtd grammar. For example, I use the iSeries Navigator Run SQL Scripts utility to execute the following commands:
set path=glblsales;
CL: cd '/dxx/Demo';
CL: RUNJVA CLASS(GlobalSalesTransform) PARM('/dxx/Demo/GlobalSales.xml'
'/dxx/Demo/GlobalSales.xsl' '/dxx/Demo/GlobalSales_t.xml'
'2005-09-29-11:48:00');
CALL SHREDXMLWRAPPER('/dxx/Demo/GlobalSales_t.dad',
'/dxx/Demo/GlobalSales_t.xml',0,'');
commit;
If everything works fine, the stored procedure returns the following message:
Output Parameter #3 = 0
Output Parameter #4 = DXXQ025I XML decomposed successfully.
The data from the GlobalSales.xml is now stored in DB2!
Software Prerequisites
For maximum database server stability, you should install the latest database group PTF (SF99502 for V5R2 or SF99503 for V5R3) on the iSeries server. In addition, the following table lists the PTFs required for the recently implemented DB2 XML Extender enhancements and improvements:
|
PTFs Required for the DB2 XML Extender Enhancements
|
|
|
OS/400 V5R2
|
i5/OS V5R3
|
|
SI17088, SI14558
|
SI17118
|
Go Forth
I hope that this article will help you select the XML-to-RDB strategy that is the most efficient in your computing environment. I believe that XML Extender can be used in many situations to simplify and speed up the implementation process. It's also important to know that the XML Extender development lab intends to provide function and performance improvements in future releases of the product.
Additional Material
Download the source code that accompanies this article: Download Image
The following publications can be helpful to those who want to learn more about the DB2 XML Extender:
- Simplified XML applications, DB2 Developer Domain white paper
- XML Extender Administration and Programming, SC27-1234-00
- XML for DB2 Information Integration, ITSO Redbook, SG24-6994
Jarek Miszczyk is the Senior Software Engineer, PartnerWorld for Developers, IBM Rochester. He can be reached by email at


 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online