















Learn how to tackle the challenges of poor data quality, inconsistency of business terms, fragmented view of the customer and product, and security and privacy.
Editor's note: This article is an excerpt from the book Selling Information Governance to the Business: Best Practices by Industry and Job Function, published by MC Press.
According to the IBM 2009 Global CIO Study, today's CIOs spend an impressive 55 percent of their time on activities that spur innovation. These activities include generating buy-in for innovative plans, implementing new technologies, and managing nontechnological business issues. CIOs spend the remaining 45 percent of their time on essential, more traditional tasks related to managing the ongoing technology environment. This includes reducing IT costs, mitigating enterprise risks, and leveraging automation to lower costs elsewhere in the business.
IT is a key stakeholder in the entire information governance program because it is normally the custodian of the data repositories. In addition, IT is the business sponsor for information governance in situations that are generally associated with IT cost savings. Across the entire sample in the IBM 2009 Global CIO Study, CIOs spend about 14 percent of their time removing costs from the technology environment. One of the top management priorities cited by a banking CIO was to "position the IT organization to handle increased activity with minimal additional cost." Simply put, CIOs aspire to do more with less. A retail CIO in the United States described the dual challenge, "The balance between new projects and cost control is the dichotomy of my life."
Here are the best practices to sell information governance internally, within IT operations:
- Engage with the vice president of applications to retire legacy applications while retaining access to the underlying data.
- Work with the vice president of applications to reduce storage costs through an archiving strategy.
- Ensure trusted data when consolidating applications, data warehouses, data marts, and operational data stores.
- Support the vice president of testing by automating the creation of test data sets.
- Work with the enterprise architecture team to enforce consistent information-architecture standards.
These best practices are discussed in detail in this chapter.
1. Engage with the VP of Applications to Retire Legacy Applications but Retain Access to Underlying Data
In a 2010 study, IT industry analyst IDC predicted that information volumes would increase by a factor of 44 over the next decade. Most large IT shops have legacy applications that are no longer in use but consume a significant portion of the IT budget. For a variety of legal and regulatory reasons, the business might need access to the underlying data but not the application itself. For example, there might be "legal holds," or regulations that require the retention of certain data sets.
IT can establish significant cost savings by retiring the legacy applications while retaining access to the underlying data. The key technical challenge is to be able to provide the data on demand, which requires the ability to maintain the referential integrity of the data.
2. Work with the VP of Applications to Reduce Storage Costs Through an Archiving Strategy
Gaining a complete understanding of which areas are accumulating the most information allows an organization to apply the most effective information lifecycle governance strategy. Data duplication has significantly contributed to growth statistics. Organizations frequently clone or copy production databases to support other functions, or for application development and testing. They also maintain several backup copies of critical data or implement mirrored databases to protect against data loss. Finally, disaster recovery plans require data duplication, to store critical data in an alternate location. All of this duplication has created what is known as the "data multiplier effect."
As data is duplicated, storage and maintenance costs increase proportionally. Figure 14.1 provides an example of a production database that contains one terabyte of data. When that database is copied for backup, disaster recovery, development, testing, and user acceptance, the total data burden increases to six terabytes.
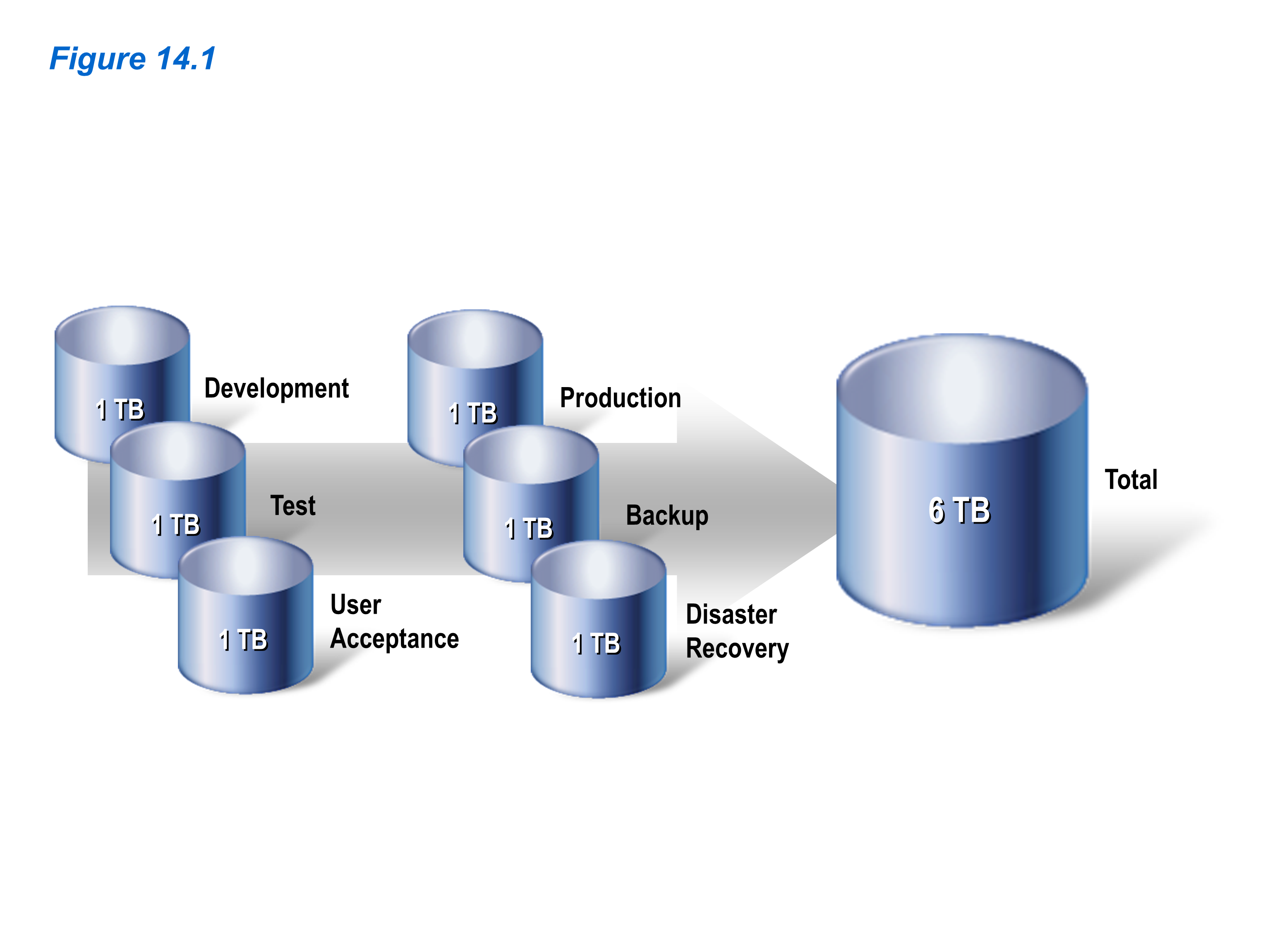
Figure 14.1: The actual data burden equals the size of the production database and all replicated clones. (Click image to enlarge.)
You cannot govern data if you do not understand it, so it is critical that you first document your existing data landscape, using data discovery. Data discovery analyzes data values and patterns to identify the relationships that link disparate data elements into logical units of information, or business objects, such as customer, patient, and invoice. These business objects provide essential input for archiving. Without an automated process to identify data relationships and define business objects, organizations can spend months performing manual analysis, with no assurance of completeness or accuracy.
From an information governance perspective, an organization needs to archive both structured and unstructured content to reduce storage costs, improve system performance, and ensure compliance with regulatory requirements. In particular, unstructured content in the form of emails and other documents makes up more than 80 percent of the content in a typical enterprise. This content needs to be archived to reduce storage costs.
Storing archived data according to its business value is a logical component of an integrated data management strategy. A three-tier classification strategy is a useful way to approach the problem. Current transactions are maintained in high-speed, primary storage. Reporting data is relocated to mid-tier storage. Reference data is retained on a secure Write Once, Read Many (WORM) device, keeping it available in case an audit request should arise. This approach to a tiered storage and archiving strategy is a good way to reduce costs and maximize business value, as discussed in Case Study 14.1.
Case Study 14.1: Managing data growth at a large telecommunications operator
A large telecommunications operator was struggling with the storage costs associated with large amounts of data, including Call Detail Records (CDRs). The telecommunications operator had nearly 16 terabytes of data in one production environment, and six database clones for disaster recovery, backup, and pre-production environments. The operator needed to fund additional mainframe computing capacity every year to upgrade performance.
The information governance team established a business case that articulated significant cost savings by archiving data to lower-cost storage environments. Important questions to the business included "How many months of data do we need to maintain in production systems?" Because of the initiative, the operator was able to reduce storage costs dramatically. The business benefits are highlighted in Table 14.1.
|
Table 14.1: The Sanitized Business Benefits from an Archiving Solution at a Large Telecommunications Operator |
|
|
A. Size of the production database in gigabytes |
16,000 |
|
B. Number of database copies for disaster recovery, backup, and performance testing |
6 |
|
C. Annual cost of storage per gigabyte |
$50 |
|
D. Current cost of storage ((B + 1) x A x C) |
$5,600,000 |
|
E. Percentage of data that can be archived |
70% |
|
F. Post-archiving storage cost savings (D x E) |
$3,920,000 |
|
G. Three-year storage cost savings (F x 3) |
$11,760,000 |
3. Ensure Trusted Data when Consolidating Applications, Data Warehouses, Data Marts, and Data Stores
Most large IT departments have multiple, overlapping applications, data warehouses, data marts, and operational data stores that are enormously expensive to maintain. One large bank saved hundreds of millions of dollars by consolidating eight customer information files (CIFs) into one. Another bank had 10 CIFs, each with five or more copies, several of which were built in COBOL. It cost the bank tens of millions of dollars to maintain this unwieldy system. The information governance program was driven by a strong desire to cut costs, especially when a seemingly straightforward project to implement "powers of attorney" cost several millions of dollars because the same functionality had to be re-implemented within each CIF.
When organizations embark on multi-year, multi-million dollar enterprise resource planning (ERP) implementations, they believe that the business benefits delivered by ERP solutions will far outweigh the costs of implementation. Empirical evidence shows that approximately 40 percent of the cost of an ERP implementation is around data integration. Sound information governance will ensure that not only is "the data loaded correctly," but also the "correct data is loaded correctly" into the ERP application. When an organization migrates to new ERP applications, the information governance program needs to ensure that data within the source systems is understood, cleansed, transformed, and delivered to the ERP system.
Table 14.2 provides a sanitized version of the business benefits associated with improving the quality of data as part of an SAP rollout. The SAP project will achieve limited savings during the initial rollout due to the upfront cost associated with adopting a new approach. However, the project will produce substantial benefits in subsequent rollouts, with the adoption of a data integration center of excellence. In addition, the business benefits shown do not reflect soft savings associated with improved decision-making based on better data quality.
|
Table 14.2: The Sanitized Business Benefits from Improved Data Quality as Part of an SAP Rollout |
|||
|
Rollout |
As-Is Approach |
To-Be Approach with Focus on Data Quality |
Hard Savings |
|
A. Number of hours for rollout 1 |
30,000 |
27,000 |
3,000 |
|
B. Number of hours for rollout 2 |
25,000 |
15,000 |
10,000 |
|
C. Number of hours for rollout 3 |
20,000 |
8,000 |
12,000 |
|
D. Total number of hours (A + B + C) |
75,000 |
50,000 |
25,000 |
|
E. Labor cost per hour |
$75 |
$75 |
$75 |
|
F. Total labor costs (D x E) |
$5,625,000 |
$3,750,000 |
$1,875,000 |
4. Support the VP of Testing by Automating the Creation of Test Data Sets
The creation of realistic test data sets can add significant extra time to projects. For example, a large organization added several months to its project timeline to create thousands of realistic customer data sets for testing. According to the white paper "Enterprise Strategies to Improve Application Testing" (IBM, April 2008), it is typically impractical to clone an entire production database, made up of hundreds of interrelated tables, just for testing purposes. First, there are the capacity, cost, and time issues with provisioning an entirely new database environment just for testing. Second, there is a quality issue: when working with large test databases, developers might find it difficult to track and validate specific test cases.
Here are some of the requirements for effective test data management:
- Create realistic data. It is important to create a smaller, realistic subset of data that accurately reflects application production data.
- Preserve the referential integrity of the test data. The data subsets need to respect the referential integrity rules enforced within the database and the applications. Typically, application-enforced referential integrity is more complex. For example, the application might include relationships that use compatible but not identical data types, composite and partial columns, and data-driven relationships.
- Force error and boundary conditions. Creating realistic subsets of related test data from a production database is a reasonable start. However, it is sometimes necessary to edit the data to force specific error conditions or to validate specific processing functions.
- Mask and transform test data. With the increased focus on data privacy, the ability to transform and de-identify sensitive data in the development and testing environments is critical to preventing data breaches and severe penalties.
- Compare before and after test data. The ability to compare test data before and after successive tests is essential to the overall quality of the application. This process involves the comparison of each test iteration against baseline test data to identify problems that otherwise could go undetected—especially when tests potentially affect hundreds or thousands of tables.
Case Study 14.2 provides an example of a large information services company that dealt with several issues around test data. Table 14.3 highlights the potential business benefits from the case study's solution.
Case Study 14.2: Managing test data at a large information services company
A large information services company was focused on improving productivity, increasing efficiency, and providing high levels of customer service for its corporate clients. The business had a strong focus on cost cutting while protecting confidential client data. However, the IT department found that the testing department was making copies of sensitive data for use in test environments. As a result, IT embarked on a journey to quantify the business benefits associated with a more streamlined test environment. Due to the large volumes of data, IT found that:
- Right-sizing the test environments would have a significant impact on storage cost savings.
- Masking the data within pre-production, performance, and test environments would significantly reduce the risk of exposing confidential client information.
- Automating scripts to mask and populate test data would significantly improve the productivity of the testing team, due to reduced downtime.
In addition to the hard-dollar benefits in Table 14.3, the solution also yielded soft-dollar benefits from improved security and privacy of client data.
|
Table 14.3: The Sanitized Hard-Dollar Business Benefits from a Test Data Management Solution at a Large Information Services Provider |
|
|
A. Size of production database in gigabytes |
5,000 |
|
B. Number of production environments |
1 |
|
C. Number of test environments with cloned copies of production data |
8 |
|
D. Annual cost of storage per gigabyte |
$50 |
|
E. Total annual cost of storage (A x (B + C) x D) |
$2,250,000 |
|
F. Percentage of production data to be cloned to each test environment |
20% |
|
G. Size of each test data environment in gigabytes (A x F) |
1,000 |
|
H. Annual storage in gigabytes after right-sizing the test data environments (A + (C x G)) |
13,000 |
|
I. Future-state cost of storage (H x D) |
$650,000 |
|
J. Potential storage cost savings (E – I) |
$1,600,000 |
|
K. Number of hours saved on refreshing the test environment per year (4 hours per refresh x 12 refreshes per year x C) |
384 |
|
L. Total number of testers affected by refresh cycles |
90 |
|
M. Potential productivity impact on testing team (K x L) |
34,560 |
|
N. Cost per hour of a tester |
$50 |
|
O. Total impact on testing productivity (M x N) |
$1,728,000 |
|
P. Annual business benefits from test data management solution (J + O) |
$3,328,000 |
|
Q. Business benefits over three years from test data management solution (P x 3) |
$9,984,000 |
5. Work with the Enterprise Architecture Team to Enforce Consistent Information Architecture Standards
In some cases, the information governance team might assume responsibility to ensure that the organization observes standards for information architecture. In many organizations, an IT enterprise architecture review board that has sign-off authority for new IT projects might handle IT architecture governance. This board has an important role in driving overall IT efficiency through the enforcement of standards. For example, the standardization of tools is critical as organizations look to reduce license, software maintenance, and support costs. Keep in mind, however, that there is always a natural tension between IT architecture teams that tend to prefer standardization and business units that prefer tactical approaches to address project needs.
Summary
IT has a critical role as the custodian of data to serve the needs of the business. In addition, IT can benefit from sound information governance to drive operational efficiencies and cost savings.
Notes
"Control Application Data Growth Before It Controls Your Business," IBM, September 2009.
"IBM Information Server: Easing SAP implementations, migrations and instance consolidation," IBM Corporation, 2007.
This chapter includes contributions by Meenu Agarwal (IBM).

Sunil Soares is the founder and managing partner of Information Asset, LLC, a consulting firm that specializes in data governance. Prior to this role, Sunil was director of information governance at IBM, where he worked with clients across six continents and multiple industries. Before joining IBM, Sunil consulted with major financial institutions at the Financial Services Strategy Consulting Practice of Booz Allen & Hamilton in New York. Sunil lives in New Jersey and holds an MBA in finance and marketing from the University of Chicago Booth School of Business.
MC Press books written by Sunil Soares available now on the MC Press Bookstore.
 |
Big Data Governance Discover not only the “why” but the “how” of governing big data. List Price $59.95 Now On Sale
|
|
 |
Data Governance Tools See why tools are a critical component of a data governance program, and learn how to evaluate them. List Price $59.95 Now On Sale
|
|
 |
IBM InfoSphere: A Platform for Big Data Governance and Process Data Governance Get to know the big data support across the IBM InfoSphere portfolio. List Price $16.95 Now On Sale
|
|
 |
Selling Information Governance to the Business Learn best practices for implementing an information governance program across a variety of specific industries. List Price $49.95 Now On Sale
|
|
 |
The Chief Data Officer Handbook for Data Governance Implement a program that will manage data as an asset while delivering the trusted data your business initiatives require. Now On Sale
|
|
 |
The IBM Data Governance Unified Process Learn the 14 steps to implementing data governance based on IBM products, services, and best practices. Now On Sale
|




 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online