















Something for everyone! Which one is your favorite?
Once again, it's time to talk about the Technology Refresh timed enhancements to DB2 for i. When I reflected on how I would describe this topic in a "short and sweet" manner, I thought about a recent business trip I made to Indianapolis. While looking for a present to bring my family, I happened upon the Rocket Fizz candy store. One of the many great things about this store is their wall of saltwater taffy. You (the customer) get to pick and choose from the many flavors to savor. I crammed a bag full of these tasty bites and, upon my return home, was greeted ever so warmly by my sweet-tooth family. What does this have to do with DB2 for i? Much like my favorite candy store, we have a wide array of enhancements for you. Something for everyone, regardless of your specific area of interest. Read on and see if you find something sweet.
With the announcement of IBM i 7.1 Technology Refresh (TR) 10 and IBM i 7.2 Technology Refresh (TR) 2, IBM is sharing the details of enhancements that will be available soon. This article and the IBM official announcement content is shared with you in advance of these enhancements being generally available. If you follow our DB2 for IBM i Group PTF schedule page, you can see our up-to-date plans, dates, status, and more.
We have supporting detail for all IBM i TR10 and TR2 timed enhancements within the IBM i Technology Updates wiki in developerWorks. The landing pages for these enhancements are:
- http://www.ibm.com/developerworks/ibmi/techupdates/i72-TR2
- http://www.ibm.com/developerworks/ibmi/techupdates/i71-TR10
This is the best place to start, because it contains the complete list of enhancements with direct links to the details. The timeline slide that appears in Figure 1 merely scratches the surface of what's new.
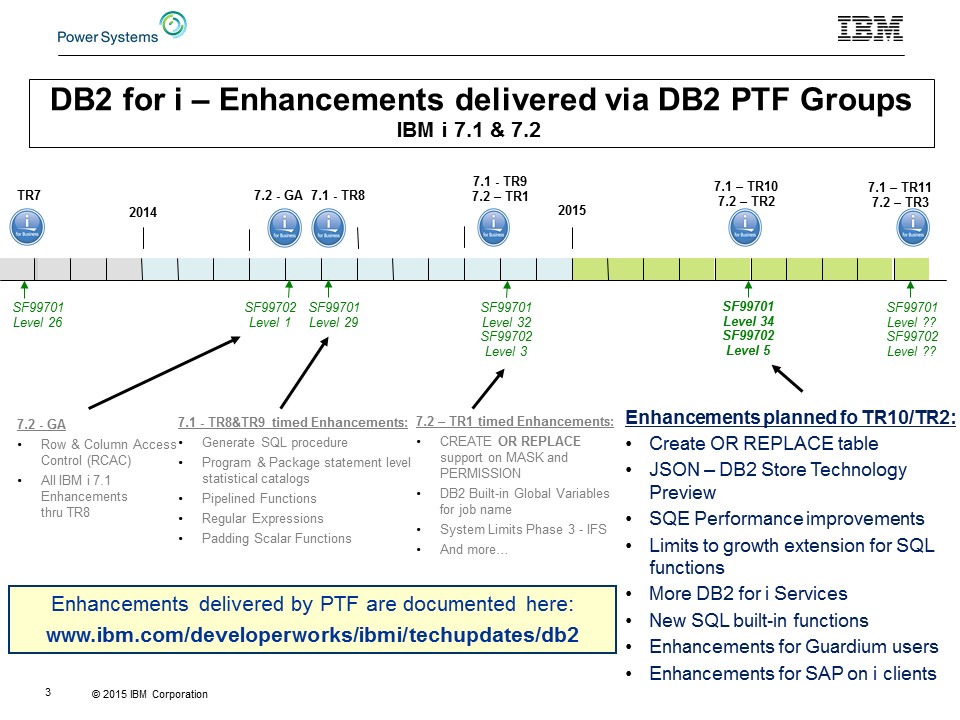
Figure 1: DB2 for i enhancements follow this timeline (updated for TR2/TR10).
We have many new flavors for you in DB2 for i, including:
- Enhanced SQL for Data Definition Language (DDL)
- New IBM i services
- SQE performance improvements
- New database performance controls and insight
- And more…
This is an overview article. I'll leave plenty of room for industry pundits to have a turn.
Create or Replace Table (SQL Statement)
One of the most important value statements for this database is that DB2 for i is "easy to use." This is an all-too-often-heard claim. How does the addition of table replacement make DB2 for i easier to use? Simply stated, a replaced table engages the database to discern and implement the necessary set of alter actions to transform the existing table into the new definition. By focusing on maintaining the master source for SQL tables, DB2 for i clients can avoid the time required to assess and implement the perfect combination of alters to achieve the desired outcome. In this way, DB2 for i is easier to use than other databases, where it can be typical to have an expensive administration team, diverting IT spending in the wrong direction.
Having one more option on an SQL statement that already has uncounted options may seem a bit mundane at first, but before you firm up your opinion, consider a couple things first. When OR REPLACE is used on a CREATE TABLE statement, the database is put in control of transforming your existing table into a new form while not losing anything important along the way. This is the latest example of something referred to as data-centric computing. For anyone unfamiliar with this term, the idea is to avoid handling many complex steps as a user in favor of having the database do the job.
If you're not convinced that transforming a table involves a complex set of tasks, refer to the check-marked list in Figure 2. Why is there a first-place ribbon on the figure? Similar to the Regular expression support added with TR9/TR1, DB2 for i is the first major database to have table replacement support on the CREATE TABLE SQL statement.

Figure 2: Create OR REPLACE Table SQL statement.
Considerations Abound
When replacing a table, DB2 for i lets you guide the replacement technique via the optional ON REPLACE clause. There are three options at your disposal:
- ON REPLACE PRESERVE ALL ROWS (default)
This is the safest option to use because you are guaranteed not to lose any rows in the table.
Columns can be added, dropped, and altered. - ON REPLACE PRESERVE ROWS
If the table is not a range partitioned table, PRESERVE ALL ROWS and PRESERVE ROWS result in equivalent behavior.
If the new range partitioned table has a match by partition name or by the exact range boundaries, the rows are preserved. Otherwise, the rows are deleted and no delete triggers are fired.
Columns can be added, dropped, and altered. - ON REPLACE DELETE ROWS
All rows are deleted and no delete triggers are fired.
You can (and should) read all the details within the updated CREATE TABLE documentation within the SQL Reference. The syntax is explained and, more importantly, the "REPLACE rules" table answers some of the questions you're eager to ask. When a table is replaced, the new definition of the table is compared to the old definition and logically, for each difference between the two, a corresponding ALTER operation is performed. When DB2 for i determines that a column or constraint needs to be removed, it uses RESTRICT processing rules.
RESTRICT rules:
- Columns cannot be dropped if any views, indexes, triggers, materialized query tables, row permissions, column masks, or constraints are dependent on the column.
- Unique constraints cannot be dropped if any referential constraints are dependent on the constraint.
Another critical resource is found under ALTER TABLE documentation. Search for "Cascaded Effects" to find a table that explains how the restrict effect is applied for different operations.
To make it a little easier to become focused on master table source, we also enhanced the QSYS2.GENERATE_SQL() procedure to return the master source when called with options CREATE_OR_REPLACE_OPTION => '1' & DATABASE_OBJECT_TYPE=> 'TABLE'. This differs from typical generate DDL processing for tables by including all the constraint definition within the CREATE TABLE statement, as opposed to generating a set of trailing ALTER TABLE ADD CONSTRAINT statements.
New IBM i Services
DB2 for i-supplied IBM i Services are quickly becoming a mainstream topic. Don't take my word for it; read what others are saying:
- Dawn May: http://www.ibmsystemsmag.com/Blogs/i-Can/March-2015/IBM-i-Services/
- Tim Rowe: https://www.systemideveloper.com/blogs/?q=node/17
- Michael Sansoterra: http://www.itjungle.com/fhg/fhg040715-story01.html
- Alan Seiden: https://twitter.com/alanseiden/status/519862901247856641
- Steve Pitcher: http://www.mcpressonline.com/commentary/in-the-wheelhouse-the-real-power-of-common.html
With the TR-timed DB2 PTF Group, new IBM i Services come in the form of views, User-Defined Table Functions (UDTFs), and procedures. These services extend what's possible with SQL in the following operating system subject matter areas:
- Java
- Librarian
- Security
- TCP/IP
- Work Management
Let's briefly examine what's new and enhanced. All the new and enhanced services are being added to both IBM i 7.1 and IBM i 7.2.
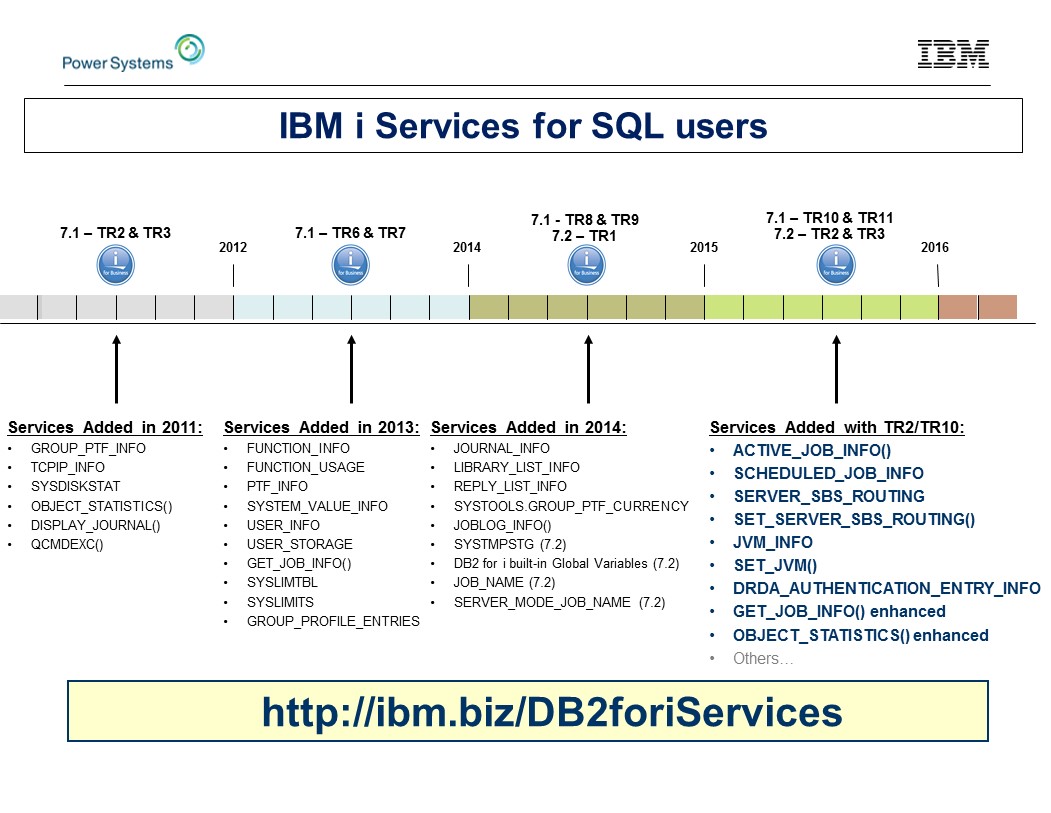
Figure 3: IBM i Services timeline, updated with new TR2/TR10-timed services
Work Management Services
These new and improved services enable new forms of systems management using SQL.
|
Service Name |
SQL Type |
Purpose |
|
QSYS2.ACTIVE_JOB_INFO() |
UDTF |
Work with Active jobs |
|
QSYS2.GET_JOB_INFO() (enhanced) |
UDTF |
Return additional detail about a specific job |
|
QSYS2.SCHEDULED_JOB_INFO |
View |
Details about the scheduled job entries. |
Example 1 gives a glimpse into what's possible now with these new services. Now that the active jobs are at the fingertips of your SQL queries, you simply need to construct the high-value questions and DB2 for i will help you answer them.
ACTIVE_JOB_INFO includes four parameters. As you see in the example, IBM i 7.2 users get an extra advantage of named and default parameter support for functions. This allows the function to be invoked with no parameters, if you want the default behavior. If you don't want to use a specific filter, don't specify that parameter.
Example 1: Find the longest-running SQL statement (IBM i 7.2)
WITH ACTIVE_USER_JOBS (Q_JOB_NAME, CPU_TIME, RUN_PRIORITY) AS (
SELECT JOB_NAME, CPU_TIME, RUN_PRIORITY FROM TABLE (ACTIVE_JOB_INFO()) x WHERE JOB_TYPE <> 'SYS'
)
SELECT Q_JOB_NAME, CPU_TIME, RUN_PRIORITY, V_SQL_STATEMENT_TEXT,
CURRENT TIMESTAMP - V_SQL_STMT_START_TIMESTAMP AS SQL_STMT_DURATION, B.*
FROM ACTIVE_USER_JOBS, TABLE(QSYS2.GET_JOB_INFO(Q_JOB_NAME)) B
WHERE V_SQL_STMT_STATUS = 'ACTIVE'
ORDER BY SQL_STMT_DURATION DESC
Example 1 sample query results:

Anyone using IBM i 7.1 will need to always pass all four parameters. If you don't want to use a specific filter, pass the empty string for that parameter.
ACTIVE_JOB_INFO() UDTF Parameters:
- RESET_STATISTICS (YES or NO)
Establish a new baseline for elapsed time measurements. Specifying YES on this parameter has the same effect as pressing F10=Restart statistics from the Work with Active Jobs (WRKACTJOB) command.
Subsequent executions that do not specify YES will be able to observe elapsed interval detail. See the details about the UDTF return table layout in developerWorks or in Knowledge Center. - SUBSYSTEM_LIST_FILTER
Optional list of up to 25 subsystem names separated by exactly one comma. The filter determines which subsystems to use to return job information. If this filter isn't used, information for all subsystems is returned. - JOB_NAME_FILTER
Find jobs by a specific name, generic name, or by a special value as shown in the following table.
|
JOB_NAME_FILTER Special values |
Meaning |
|
* |
Return information for the current job |
|
*ALL |
Information for all jobs is returned |
|
*CURRENT |
Information for all jobs with a job name that matches the current job is returned |
|
*SBS |
Information for all active subsystem monitors is returned |
|
*SYS |
Information for all active system jobs is returned |
- CURRENT_USER_LIST_FILTER
Optional list of up to 10 user profile names, separated by exactly one comma.
When multiple filters are used, they are logically ANDed together to return entries that match all the filtering criteria.
The SCHEDULED_JOB_INFO catalog returns detail normally accessed through the Work with Job Schedule Entries (WRKJOBSCDE) command. By having an SQL alternative interface to this detail, programmers can interrogate job schedule detail and administrators can use SQL to level check that a production partition's scheduled jobs match those on the failover partition.
TCP/IP Services
Have you ever been frustrated by having an ad hoc query appear in QUSRWRK that consumes more than its fair share of system resources? If so, this service can help you. The SET_SERVER_SBS_ROUTING procedure can be called to indicate the alternative subsystem that this user should use whenever they form a connection using DRDA, DDM, and/or Host Server.
The configuration choice is retained within the *USRPRF object, allowing it to survive save and restore operations. Further, the support even works against a group profile or supplemental group profile.
|
Service Name |
SQL Type |
Purpose |
|
QSYS2.SET_SERVER_SBS_ROUTING() |
Procedure |
Relocate Host Server and DRDA users into a specific subsystem, different from the default subsystem (QUSRWRK). |
|
QSYS2.SERVER_SBS_ROUTING |
View |
Review existing alternate subsystem configuration |
Java Services
The first set of Java services includes a catalog alternative to the Work with JVM Jobs (WRKJVMJOB) and a companion procedure to change the settings for certain JVM jobs. These services are intended to help anyone responsible for maintaining and monitoring the ongoing status of Java-based applications.
|
Service Name |
SQL Type |
Purpose |
|
QSYS2.JVM_INFO |
View |
Query live statistical and setup information related to all active Java Virtual Machine (JVM) jobs. |
|
QSYS2.SET_JVM() |
Procedure |
Take actions against specific JVM jobs. |
Librarian Services
The OBJECT_STATISTICS() UDTF was one of the first services created and is often used as a building block because it can find objects. For this TR, we had a flurry of activity and enhancements to make it even more useful:
1. When being used to search for libraries, we now support special values on the library name input parameter:
- *ALLUSRAVL—All user libraries in all available ASP groups
- *ALLUSR—All user libraries in *SYSBAS and the current thread's ASP group
2. New and improved data being returned in the following columns:
- OBJLONGNAME—Changed to return the related SQL name, if one exists
- TEXT—Unicode comment detail for libraries
- SQL_OBJECT_TYPE—The associated SQL object type, if relevant.
3. Search by Object Name (IBM i 7.2 only). An optional third input parameter can be used to designate the SQL or system name of the target object. This style of usage results in a better performing query, if you know the name of the object.
|
Service Name |
SQL Type |
Purpose |
|
QSYS2.OBJECT_STATISTICS() (enhanced) |
UDTF |
Find objects and its attributes. |
Security Services
This new catalog provides easy access to see the detail normally accessed via the Display Server Authentication Entries (DSPSVRAUTE) command. Note that with the command interface, you have to invoke the command one user at a time, whereas the catalog will show you the configuration detail for all users on the partition.
|
Service Name |
SQL Type |
Purpose |
|
QSYS2.DRDA_AUTHENTICATION_ENTRY_INFO |
View |
Display Server Authentication Entry information |
Performance Improvements
Two enhancements have been made to the SQL Query Engine (SQE).
- Index Merge Ordering (IMO) is an SQE enhancement where a multi-key radix index can be used by the optimizer in places where it couldn’t before. Index access to data is all about speeding up the query, so this is a good thing.
Note: This enhancement is eligible when First I/O is used as the optimization goal, the query returns a large result set, and non-equal predicates are used on the WHERE clause.
- I/O bound LEFT or RIGHT OUTER JOIN queries can be implemented more efficiently by reducing random I/O on indexes.
Note: The SQE optimizer will do this automatically.
Performance Analysis
Database performance analysts, we've got something for you too. The following enhancements aim to improve the productivity of what can be a very complex task.
- IBM i Navigator's Show Statements is enhanced to include CPU and I/O average columns. This additional detail makes it possible, and easy, to directly factor in CPU and/or I/O metrics in real-time analysis.
- IBM i Navigator's Analyze support is enhanced to include new Job Name Summary detail to allow you to see summary detail grouped by job name.
- IBM i Navigator's Analyze table and index summary support is extended to include specific statements and summary actions. Once you find an interesting table or index, it will be easier to see the relevant performance details.
- Database statistical catalogs for indexes (SYSINDEXSTAT, SYSPARTITIONINDEXES, and SYSPARTITIONINDEXSTAT) are enhanced to contain more detail. These catalogs contain extended detail on the state and build detail for indexes.
- IBM System Limits support is extended to include object tracking of database indexes. This automated tracking detail can be used to study trends and the top consumers.
Database Administration
Do you sometimes need to rebuild large, important indexes? If yes, we have two performance improvements that will help.
- DB2 for i will react to priority changes made while an index is being built in parallel.
To build an index in parallel, you need to own and use DB2 Symmetric Multiprocessing (option 26). DB2 for i will recognize that the job's run priority has changed and will refresh that change in the parallel build worker tasks.
This capability permits the administrator to speed up or slow down the index build activity. - Enhanced index build logic for highly concurrent environments.
The following table shows the basic understanding of how the job priority of the index build job affects how the database will process the build activity. High-priority settings (1-19) are intended for time periods where there isn't high contention for the index.
|
Job Priority |
Index keys Processed Before Looking for Held Users |
Wait Time |
|
1-19 |
Process many keys at a time |
Wait less time before trying to get the seize |
|
20-80 |
Process a few keys at a time |
Wait the same amount as previously |
|
81-99 |
Process two keys at a time |
Wait a longer time than previously |
JSON DB2 Store
No, we're not selling t-shirts in our store. With the JSON DB2 Store, you'll be able to store and retrieve JSON from a DB2 for i table. This is the first step to integrate JSON data with DB2 for i. We plan to explain this technology with an article on developerWorks.
Many Flavors, Which Is Your Favorite?
I generally don't like sweets that much, but I must confess that I did enjoy the saltwater taffy. I didn't fare too well at remembering which flavors I selected, so my family had to rely on their good sense of taste to discern each flavor.
My brief overview has ended up being somewhat lengthy. All these words and I still haven't mentioned all of our enhancements. Please, visit the landing pages mentioned earlier and stop by Rocket Fizz if you have a chance.
Send me an email or tweet so that I know whether you think any of this was sweet.


 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online