















Client/server computing is the hottest trend in the industry today. One of the significant factors fueling this trend is the availability of sophisticated desktop development tools that are easy-to-use. Many development shops are abandoning traditional third-generation language (3GL) programming (such as C, COBOL, and RPG) and are turning to popular fourth-generation language (4GL) development tools. The list of available tools is quite impressive, and equally impressive is the apparent ease of use that these tools claim. I say "apparent" because, more often than not, applications developed using popular 4GL environments do not live up to the performance expectations of the developers and users. (For a more detailed discussion of performance issues in general, see "Maximizing Performance with Client Access/400 ODBC," MC, March 1996.)
For example, all too often, a solution provider will develop an application using a 4GL tool combined with a desktop database management system (DBMS). When the programmer attempts to run the same application using ODBC and a client/server DBMS, the performance is unacceptable. Of course, it's easy to just blame ODBC, but the real problem lies in the fact that applications designed for client/server must be architected quite differently than traditional applications, or they will perform poorly.
If you are building a client/server solution with one of the popular 4GL tools of the day, or if you are sticking with a traditional 3GL approach such as C, this article is for you. I'm going to assume a fairly high level of familiarity with SQL and ODBC. However, if you want more information about the ODBC functions that I discuss, turn to the Microsoft ODBC 2.0 Programmer's Reference and SDK Guide. Here, we will discuss key client/server performance issues and the implications of using popular 4GL query tools and development environments.
In "Maximizing Performance with Client Access/400 ODBC," I discussed the performance implications of client/server environments in contrast with traditional host-centric environments. I further described how these implications influenced the development of the Client Access/400 ODBC driver. Having an ODBC driver that is optimally tuned for performance is only part of the battle, though. Other things to consider are the tools that are used and whether to simply query the data or build complex programs for decision support and online transaction processing (OLTP). Many of these tools tend to violate the golden rule of client/server performance: Don't go to the server unless you have to, and go there in as few trips as possible when you do.
This rule gets violated for many reasons. Probably the foremost is that many 4GL tools were never designed for client/server environments. Instead, they were architected for standalone database access. When the rush to client/server gained momentum, some of these tools were retargeted for client/server without gaining the necessary architecture changes to ensure optimal client/server performance.
Another cause for golden rule violation and poor client/server performance is education. Here, the industry is clearly at fault. We have convinced you that building mission-critical client/server solutions is simple if you just use our 4GL tools. All you have to do is drag icons and draw lines with the click of a mouse button and voila, you've just replaced your legacy mission-critical application! Well, nothing could be further from the truth, as many of you have lived to tell.
Many 4GL development and query tools are available today. A partial list includes the following products:
o Borland Delphi
o Brio Technology DataPrism for AS/400
o Cognos Impromptu
o Computer Associates Visual Express
o Crystal Services Crystal Reports Professional
o Gupta SQLWindows
o IBM VisualAge
o IBM Visualizer for Windows
o Microsoft Access
o Microsoft Visual Basic
o Powersoft PowerBuilder
o ShowCase Vista
o Trinzic Forest and Trees
This is just a sampling. Many more are available, and every tool in the marketplace has its own strengths, weaknesses, and performance characteristics. But most have one thing in common: support for ODBC database servers. However, since ODBC serves as a common denominator for various DBMSs, and since there are subtle differences from one ODBC driver to the next, many tool providers end up writing to the more common ODBC and SQL interfaces and avoid taking advantage of a particular database server's strengths. While this eases programming efforts for the tool vendor, it often hurts overall performance.
Before we launch into some specific examples, let's take a high-level look at the generic 4GL tool architecture and how it relates to application programming logic and database access.
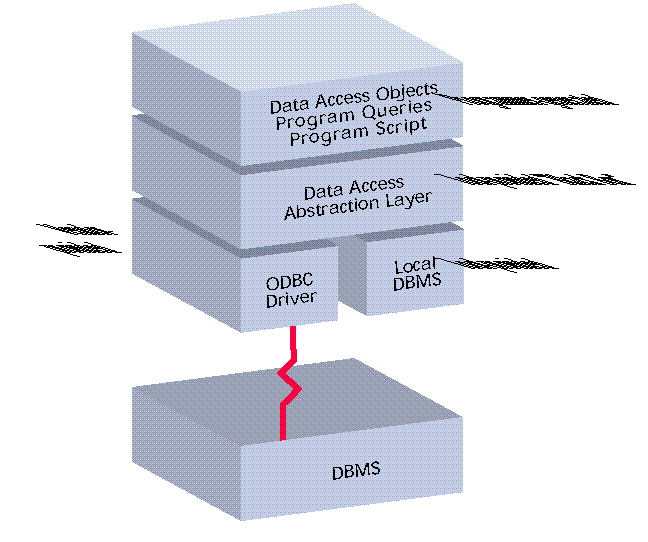
1 shows how a typical tool translates programming script and tool objects into more mundane 3GL database access. The first thing to notice in 1 is that many tools come packaged with a local standalone DBMS. Many programmers design and test their applications against local databases and then expect to roll the application out into a client/server environment without changes. Many tool user manuals suggest this as a development approach. It simply doesn't work, however, because of the different performance characteristics of client/server environments.
Figure 1 shows how a typical tool translates programming script and tool objects into more mundane 3GL database access. The first thing to notice in Figure 1 is that many tools come packaged with a local standalone DBMS. Many programmers design and test their applications against local databases and then expect to roll the application out into a client/server environment without changes. Many tool user manuals suggest this as a development approach. It simply doesn't work, however, because of the different performance characteristics of client/server environments.
The next critical piece of the architecture in 1 is what I call the Data Access Abstraction Layer. The reason it's so critical is that most database accesses go through this layer, yet many 4GL programmers don't even know that this layer exists! Worse, the programmer or user is often unable to affect this layer's behavior; hence, the term "black box." This layer is responsible for translating the high-level data access requests of the tool into specific DBMS requests, typically using SQL and ODBC. Your application's success will rely heavily on the quality of this layer's output. For example, some tools have a very good knowledge of the various server DBMSs and generate SQL that is known to perform well with each server. Other tools simply lump all server databases into one category and permit the DBMS to do as little as possible, which results in very poor client/server performance.
The next critical piece of the architecture in Figure 1 is what I call the Data Access Abstraction Layer. The reason it's so critical is that most database accesses go through this layer, yet many 4GL programmers don't even know that this layer exists! Worse, the programmer or user is often unable to affect this layer's behavior; hence, the term "black box." This layer is responsible for translating the high-level data access requests of the tool into specific DBMS requests, typically using SQL and ODBC. Your application's success will rely heavily on the quality of this layer's output. For example, some tools have a very good knowledge of the various server DBMSs and generate SQL that is known to perform well with each server. Other tools simply lump all server databases into one category and permit the DBMS to do as little as possible, which results in very poor client/server performance.
Along with the quality of the SQL and ODBC calls generated, the frequency with which the calls are generated is a critical aspect to the performance of the application. There are many different ways to accomplish the same thing when using SQL and ODBC. Some methods generate far more trips to the server than others, which degrades performance.
How can you tell the differences from one tool to the next? You must understand the output of the data access abstraction layer, both when evaluating a particular tool and throughout the application development process. In order to understand what this layer is producing, you must see the calls it is making, which is where the ODBC trace utility comes in. The version 2 ODBC driver manager has a built-in trace facility that can be activated using the ODBC Administrator. Simply run the Administrator and select the Options button on the bottom of the list box. This will bring up a dialog box that allows you to trace ODBC calls and direct them to a file for later viewing. 2 shows a typical trace listing for a popular tool.
How can you tell the differences from one tool to the next? You must understand the output of the data access abstraction layer, both when evaluating a particular tool and throughout the application development process. In order to understand what this layer is producing, you must see the calls it is making, which is where the ODBC trace utility comes in. The version 2 ODBC driver manager has a built-in trace facility that can be activated using the ODBC Administrator. Simply run the Administrator and select the Options button on the bottom of the list box. This will bring up a dialog box that allows you to trace ODBC calls and direct them to a file for later viewing. Figure 2 shows a typical trace listing for a popular tool.
It is not my intention to describe everything you might see in an ODBC trace. There is far too much to cover, and most of it is of little interest. What is important is that you are able to identify what SQL requests are being made, when they're being made, and what ODBC APIs are being used to pass the SQL to the server. In 2, one SQL SELECT statement is passed to the SQLExecDirect ODBC API. The result of the query is processed using SQLFetch and SQLGetData APIs. For the most part, this is all you have to be able to identify to diagnose performance characteristics based upon the examples described in the following pages.
It is not my intention to describe everything you might see in an ODBC trace. There is far too much to cover, and most of it is of little interest. What is important is that you are able to identify what SQL requests are being made, when they're being made, and what ODBC APIs are being used to pass the SQL to the server. In Figure 2, one SQL SELECT statement is passed to the SQLExecDirect ODBC API. The result of the query is processed using SQLFetch and SQLGetData APIs. For the most part, this is all you have to be able to identify to diagnose performance characteristics based upon the examples described in the following pages.
The performance problems incurred by generating SQL and ODBC calls that pay no attention to the particular ODBC driver or the server DBMS are best shown with a few examples. We'll start by examining some ODBC traces of some popular tools. As mentioned previously, ODBC trace information can give valuable insight into the quality of the ODBC and SQL requests made. Here are the requests of a few different tools (of course, we've changed the names and faces to protect the innocent).
Tool A
Query tool A makes the following ODBC calls to process SELECT statements:
SQLExecDirect("SELECT * FROM table_name") WHILE there_are_rows_to_fetch DO SQLFetch() FOR every_column DO SQLGetData( COLn ) END FOR ...process the data END WHILE This tool does not make use of ODBC bound columns, which would help performance. A faster way to process this is as follows:
SQLExecDirect("SELECT * FROM table_name") FOR every_column DO SQLBindColumn( COLn ) END FOR WHILE there_are_rows_to_fetch DO SQLFetch() ...process the data END WHILE For a table containing one column, there wouldn't be much difference between the two approaches. For a table with 100 columns, you end up with 100 times as many ODBC calls as in the first example, for every row fetched. We can further optimize the second scenario because bound FETCHs have the target data types defined prior to each FETCH, unlike FETCHs processed with SQLGetData calls.
Tool B
Query tool B allows the user to update a spreadsheet of rows and then send the updates to the database. It makes the following ODBC calls:
FOR every_row_updated DO SQLAllocStmt() SQLExecDirect("UPDATE...SET COLn='literal'...WHERE COLn='oldval'...") SQLFreeStmt( SQL_DROP ) END LOOP The first thing to note is that the tool performs a statement allocation and drop for every row. Only one allocate statement is needed here, and the free statement call could be changed to SQLFreeStmt( SQL_CLOSE ) after each SQLExecDirect. This would save the overhead of creating and destroying a statement handle for every operation. A second, more important performance concern is the use of SQL with literals instead of parameter markers. The SQLExecDirect() call causes an SQLPrepare and SQLExecute every time. A faster way to perform this operation would be as follows:
SQLAllocStmt() SQLPrepare("UPDATE...SET COL1=?...WHERE COL1=?...") SQLBindParameter( new_column_buffers ) SQLBindParameter( old_column_buffers) FOR every_row_updated DO ...move each row's data into the parameter buffers SQLExecute() END LOOP These sets of ODBC calls can outperform the original set by a large factor. For example, when using the CA/400 ODBC driver, the server CPU utilization will decrease to approximately 5 percent of what it was before! Response times can easily improve, dropping to a third of what they were.
Tool C (Your Worst Possible Nightmare)
Query tool C allows complex decision support type-queries to be made by defining complex query criteria with a point-and-click interface. For a particularly complex query, you might think you are generating the following SQL:
SELECT A.COL1, B.COL2, C.COL3, etc. FROM A, B, C, etc... WHERE many complex inner and outer joins are specified
The fact that you didn't have to write this complex query yourself sure is nice, but is this statement actually what the tool is processing? Perhaps yes, perhaps no. For example, one tool might pass this statement directly to the ODBC driver, while another would split the query into many individual queries and process the results at the client, like this:
SQLExecDirect("SELECT * FROM A") SQLFetch() all rows from A SQLExecDirect("SELECT * FROM B") SQLFetch() all rows from B (Process the first join at the client) SQLExecDirect("SELECT * FROM C") SQLFetch() all rows from C (Process the next join at the client) . . . And so on... This approach can lead to tremendous amounts of data being passed to the client, which will kill performance. In one real-world example, a programmer thought that a 10-way join was being passed to ODBC, with four rows being returned. Actually, however, 10 simple SELECT statements and all the FETCHs associated with them were passed. The net result of four rows was achieved only after 81,000 ODBC calls were made by the tool! Of course, the programmer was originally blaming ODBC for the slow performance, but not after the ODBC trace was revealed.
The previous examples show different ways to perform the same operation, but with different performance characteristics. If you are using a simple query tool, you typically do not have control over the SQL generated, and you are at the mercy of the programmers who wrote the tool. If you are using a 4GL development environment to build your own programs, you might have greater control over the types of ODBC and SQL calls generated. Or you might not. Evaluate each tool carefully with performance in mind, knowing that, at some point, you may have to exploit a particular feature of one DBMS to either get response times down or to increase scalability. Some tools will let you, some won't.
Although 4GL environments have great advantages for programmer productivity, they offer less control over the resulting code than with traditional 3GL development in languages such as C and C++. Sometimes, the increased control can make all the difference, especially where performance scaling is concerned.
A hybrid approach is to combine the strengths of both environments by implementing performance-critical application pieces, such as the data access layer in the 3GL environment and invoking them from the 4GL environment (assuming the 4GL tool allows this). This not only gives you the power of a 3GL where you need it, but, with proper encapsulation, you get the ability to make major changes to accommodate increasing performance requirements at late stages of the game.
When you make ODBC calls in a 3GL environment, you have full control over the types of ODBC calls and, more importantly, the quality of the SQL requests. There are typically three types of SQL requests when considered from a performance perspective: bad, good, and best. Some 4GL tools can generate good performing SQL, while some generate only bad performing SQL. To get the best performing SQL, however, you usually have to take advantage of a particular DBMS's feature, which many 4GLs do not. For example, there are essentially three ways to do INSERTs with DB2/400:
o INSERT using literals
o INSERT using parameter markers
o Blocked INSERT
Many 4GL tools use the first technique, and some use the second technique. I don't know of any (yet) that take advantage of blocked INSERT. What are the performance implications? Using parameter markers can be three times as fast as using literals, and using blocked INSERT is about 20 times as fast as using parameter markers, when all three methods are issued through the Client Access/400 ODBC driver. Although this example applies only to the Client Access/400 ODBC driver and DB2/400, consider the implications carefully at early stages of application development like these.
The client/server plunge should not be taken lightly. It is important to get your feet wet with a project of manageable size before jumping to a mission-critical application. Set your sights to the long-term, and bear in mind that client/server solutions are not cheaper in terms of dollars than traditional solutions. Much of the increased cost is in keeping things running with acceptable performance.
Another thing to be wary of is the popular advice of the day. For example, one current trend is the push for tools that can build client/server applications without any knowledge of the server. While this sounds good on paper (decreased programmer training, for example), how successful this approach will be remains unclear.
Consider also the implications of multitier architectures that utilize middle-tier servers in addition to a single data repository. Although they are significantly more complicated to implement, they offer performance scalability that is unprecedented. While you may have several thousand 5250 emulators attached to a single AS/400, you won't end up with ratios anywhere near this when distributed client/server architectures are involved. So what is considered aggressive in a two-tier client/server model? I tend to consider anything over 100 clients per server as a very aggressive client/server project. Of course, it depends on your application, but I would recommend a small number of clients per server for your first project. After that, you can rely on your own gray hair for advice.
Lance C. Amundsen is a member of the Client Access/400 ODBC development team in Rochester, Minnesota. His primary responsibility is identifying and implementing performance enhancements in the ODBC driver.
Reference
Microsoft ODBC 2.0 Programmer's Reference and SDK Guide (ISBN 1-55615-658-8).
Getting the Most Performance from ODBC Query and Development Tools
Figure 1: Typical Client/Server Tool Database Access Methods
Getting the Most Performance from ODBC Query and Development Tools
Figure 2: Typical ODBC Trace Listing
SQLAllocEnv(henv); SQLAllocConnect(henv, hdbc); SQLSetConnectOption(hdbc, 103, 00000014); SQLDriverConnect(hdbc, hwnd, "", 32, ConnStr, 256, ConnStrOut, 0); . . . SQLAllocStmt(hdbc, hstmt); SQLExecDirect(hstmt, "SELECT NEWS_DOC_SEQNBR,NEWS_KEY FROM OINT771", -3); SQLFetch(hstmt); SQLGetData(hstmt, 1, 99, rgbValue, 252, pcbValue); SQLGetData(hstmt, 2, 99, rgbValue, 244, pcbValue); . . . SQLFreeStmt(hstmt); SQLDisconnect(hdbc48470000);

 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online