















In this tip, I'll briefly demonstrate the proper techniques for using the IBM List Object APIs. In particular, I would like to show how to read user space objects in such a manner that programs using this technique will continue to work properly from release to release, even when IBM changes the layout of the information in user spaces that are written to by the APIs.
I will use the DSPRCDFMT tool as an example of how to read information in a user space. (You can download all the code you'll need for this TechTip by clicking here.) This tool, which was originally made available in "DSPRCDFMT--An API Alternative to DSPFFD," uses the QUSLFLD API to write the field information to a user space and then reads the information in that space and presents it in a subfile. It is a much more readable alternative to the DSPFFD command. Unfortunately, the original tool was written around V1R3, and we are now up to V5R2. Some users of the DSPRCDFMT tool have experienced errors when calling the QUSRTVUS API to get information from the user space. This is not an error on IBM's part; instead, the problem is a result of incorrect offsets in the call to the QUSRTVUS API. More about that below...
The following table represents a partial list of the IBM APIs that write list information to a user space object (type *USRSPC). You can find out more about these APIs and how to use them from the two online IBM manuals OS/400 System API Programming and OS/400 System API Reference.
API Name |
API Description |
|
QBNLPGMI
|
List ILE Program Information
|
|
QBNLSPGM
|
List Service Program Information
|
|
QDBLDBR
|
List Database Relations
|
|
QUSLFLD
|
List Record Format Fields
|
|
QUSLMBR
|
List Database File Members
|
|
QUSLOBJ
|
List Objects
|
|
QUSLRCD
|
List Record Formats
|
IBM has an excellent diagram of the user space format in the OS/400 System API Programming manual, which I've reproduced in Figure 1.
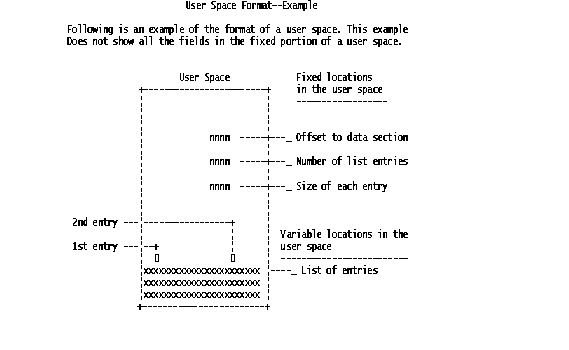
Figure 1: This is the format of the Control portion of a user space. (Click images to enlarge.)
Although you can create your own user spaces and write information to them in any format you want, each user space generally has three main sections, as written to by the APIs listed above. These sections are the "fixed" or Control section, the Header section, and the List section. Figure 1 shows the Control section and the first three entries of the List section; the Header section is not shown. You first read the Control section to get the offsets to and sizes of the Header and List sections. IBM uses the term offset to mean "start at byte zero" and the term position to mean "start at byte one." All the "start-at" values in the Control section are given in offsets, but when you use the QUSRTVUS API to read information from the user space, you add one to the offset to get the starting position, which you then pass as a parameter to the API.
The easiest way to retrieve these Control offsets and sizes is to use an externally described data structure; such a structure is shown in Figure 2. You can use the same data structure for any of the list APIs that write a list to a user space. The Control section will have the same layout, even though the Header and List sections will differ from API to API, according to which one you are using.
|
Figure 2: Use an externally described data structure to retrieve Control offsets.
To define the external data structure with RPG III, use the following input specification:
Here is the code snippet you use to retrieve the Control section information; this is the only time you will hard code the starting position value:
* First read the UsrSpc control area to get offsets, sizes
*
C CALL 'QUSRTVUS'
C PARM #SPC20
C PARM 1 #STPOS
C PARM 192 #STLEN
C PARM #CTRL
The first parameter, #SPC20, is the qualified name of your user space, with the space name being in the first 10 positions of the field and the space library (usually QTEMP) being in the second 10 positions. The second parameter, #STPOS, is the starting position of the space (that is, offset zero). It is a nine-digit binary field. The third parameter, #STLEN, is the length of the Control area to receive. It is also a nine-digit binary field. The length value is always 192 bytes. Even if IBM someday extends the Control area, the first 192 bytes should still contain the same information, and the rest can be skipped. In fact, you only need about four values from the Control section to process the rest of the user space information. The fourth parameter, #CTRL, is the RPG name of the externally described data structure into which you are reading the Control information.
It is vitally important that the size of the data structure into which you are reading information be exactly the same as the value of parameter three! If there is a mismatch, the call to the API will not work correctly. This is the programmer's responsibility, but using the offset values found in the Control area for the Header and List sections will ensure that you read your information from the correct position in the user space.
Figure 3 shows the code you use to retrieve the Header section information. You get the Start_Position value from the Control fields that have just been read.
|
Figure 3: Use this code to retrieve the Header section information.
The CTHDOS field is the Header_Section_Offset value. Add one to it to get the position value used by the QUSRTVUS API. If IBM changes the Header section offset from release to release, the offset will always be right because the value will be set correctly by the QUSLFLD API.
The last step is to read through the List area, reading each list entry and adding the information to the subfile. Figure 4 shows the code you use to set up the API to the start of the List section:
|
Figure 4: Use this code to set up the API to the start of the List section.
Note that you are using the Control section field CTENSZ to set the list entry size, but you are using the hard-coded value 288 to tell the API how many bytes you are going to retrieve on the call to QUSRTVUS. That is because you know in advance the size of the data structure that you are going to pass to the API, but you don't know in advance exactly how much data is really in each list entry. That value is set from the CTENSZ (Entry_Size) field. You will use that value in the read loop to compute the starting position of the next entry, until all entries have been read.
At V1R3, the Entry_Size for this API was in fact 288 bytes, but IBM has since increased it considerably. It is now over 400 bytes (!), but you don't need to know all the information contained in each entry, just the information defined in the #DETL data structure. Each time you set a new offset, you merely skip over the information that you don't need to see.
The read loop is shown in Figure 5.
|
Figure 5: Use the value in the read loop to compute the starting position of the next entry.
For simplicity's sake, I've omitted the logic to move the received values into the subfile fields, the calculations to get the From and To values, and so forth. The IF test outside the loop is to ensure that the user space does in fact contain at least one field entry. The way DSPRCDFMT is designed essentially ensures that, but it is also possible to use the QUSLFLD API to list fields for a record format that has no fields (such as an ASSUME record in a display file); that is why the test is made. The code should also test to ensure that the user space exists and has been loaded with field information before the QUSRTVUS API is called. That has been done in the case of the DSPRCDFMT tool outside the RPG program, in the calling CL program. The corrected source code for this utility is included in the downloadable code.
Figure 6 shows a sample of the output from the corrected DSPRCDFMT utility. The file record format shown is the same as the externally described data structure shown in Figure 2.

Figure 6: This screen shows sample output for the DSPRCDFMT command for the APICTL file.
Once you understand how API processing works for user spaces, you can apply this code example to any API that creates a list in a similar manner. After a while, it gets kind of fun! And of course, it is much faster than using *OUTFILE processing. Enjoy!
Richard Hart is an iSeries programmer with more years of experience on the IBM System/34 through the iSeries than he likes to think about. He can be reached by email at

 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online