















Editor's note: This article is an excerpt from Chapter 8, "Master Data Integration," of IBM InfoSphere: A Platform for Big Data Governance and Process Data Governance (MC Press, 2013).
IBM InfoSphere Master Data Management (MDM) systems provide a 360-degree view of customers, vendors, materials, assets, and other entities. Traditional MDM systems collect structured data from a number of structured data sources. With the advent of big data, MDM projects will increasingly look to derive value from the large volumes of entity information that is hidden within unstructured text, such as social media, email, call center voice transcripts, agent logs, and scanned text. This content might reside in multiple formats, such as plain text, Microsoft Word documents, and Adobe PDF documents, and in different forms of storage, such as content management repositories and file systems. In the following case study, the MDM team at a hypothetical company needs to integrate email with the customer record using IBM InfoSphere Master Data Management and IBM InfoSphere BigInsights text analytics technologies.
Case Study: Integration of Email with Customer MDM
The MDM program needs to adopt the following steps to enrich master data with sources of unstructured text:
1. Define the attributes for each entity that needs to be governed.
Figure 8.1 describes a simplified schema for the customer entity. It includes attributes for name, company, city, country, and email address that are commonly found in a CRM system. In this theoretical example, the master data team will use these attributes to make correlations to existing IBM InfoSphere Master Data Management records with additional content from emails.
![]()
Figure 8.1: A simplified schema for the customer entity in IBM InfoSphere Master Data Management.
2. Generate a dictionary file for each attribute from the MDM repository and other sources.
The MDM team then needs to create or reuse a dictionary containing a list of all possible values. This dictionary may be generated in multiple ways. One approach would be to create the dictionary based on all the existing values for each attribute in the IBM InfoSphere Master Data Management repository. Additional algorithms and annotation logic can then enhance these dictionaries. Figure 8.2 provides an example of a dictionary that was created by looking up the values for each customer attribute within IBM InfoSphere Master Data Management.
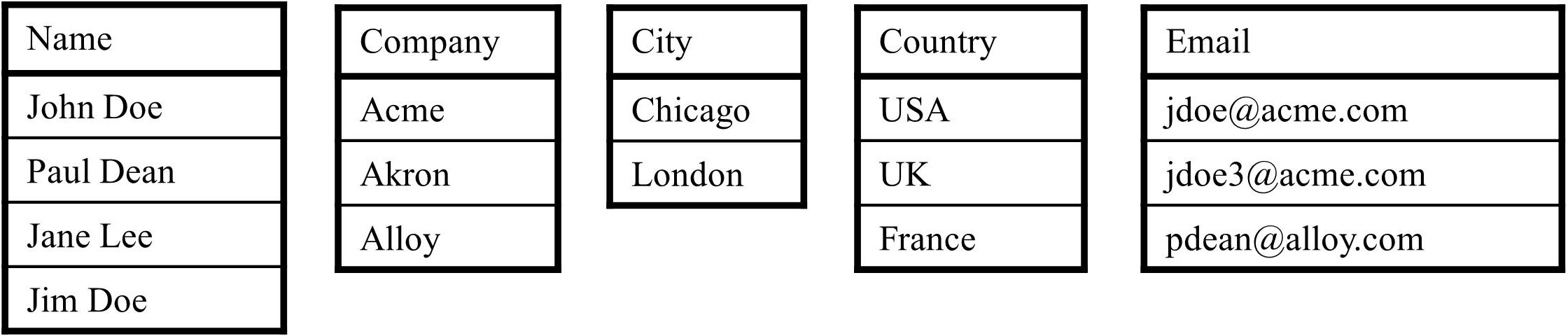
Figure 8.2: Attribute dictionaries for the customer entity in IBM InfoSphere Master Data Management.
3. Annotate relevant terms based on fuzzy matching and business rules.
Figure 8.3 shows a sample intercompany email that summarizes some business discussions. The team uses IBM text annotation techniques to locate the highlighted terms based on the dictionary. Some terms, such as “date,” are not amenable to dictionary-based annotation because there are too many different ways of writing the same date. Although date is not a key attribute in this example, a date-specific annotation algorithm or rule might be more appropriate.

Figure 8.3: A sample email with unstructured content.
4. Construct a query to the MDM system that consists of the annotations from the unstructured text.
As shown in Figure 8.4, the text analytics platform issues a single MDM query based on the annotations from the unstructured text.

Figure 8.4: A single MDM query based on annotations from unstructured text.
IBM InfoSphere Master Data Management then returns the records shown in Figure 8.5 that were above the minimal matching threshold. Entity identifier 1 (EID 1) received a high matching score because MDM found a match on email, employer, country, and name, which have a high weighting in the matching algorithm.

Figure 8.5: IBM InfoSphere Master Data Management returns records above the minimal matching threshold.
5. Construct a record for the unstructured entity.
The system then constructs the matching entities based on the attributes found in the document. In Figure 8.6, the system uses the email to construct a record for matching entity identifier 1 (MEID 1) as follows:
- Name = “Jon Doe”
- Employer = “Acme”
- Country = “UK”
- Email = “
This email address is being protected from spambots. You need JavaScript enabled to view it. ”
The record also contains the following attributes to identify the source of the information, the type of document, and the strength of that association:
- DOCID = “Doc1” (identifier for the specific email)
- Source = “Email”
- Confidence = “High”

Figure 8.6: Entities constructed by text analytics intersecting the results from MDM with the extracted terms.
6. Associate newly constructed entity records with existing MDM records.
As shown in Figure 8.7, the newly constructed entity records are automatically inserted into IBM InfoSphere Master Data Management if the confidence level is high. On the other hand, they are automatically rejected if the confidence level is low. For records with a medium confidence level, a data steward will manually review the records to determine whether they should be linked to existing MDM records.

Figure 8.7: An algorithm to process the newly constructed entity records in IBM InfoSphere Master Data Management.
As shown in Figure 8.8, IBM InfoSphere Master Data Management will automatically link MEID 1 for Jon Doe with EID 1 for John Doe. The email in Figure 8.3 will now be associated with EID 1 as well. On the other hand, IBM InfoSphere Master Data Management will automatically reject MEID 2 from Figure 8.6 because the confidence level is low. Finally, a data steward will manually review MEID 3 and MEID 5 because the confidence level is medium.
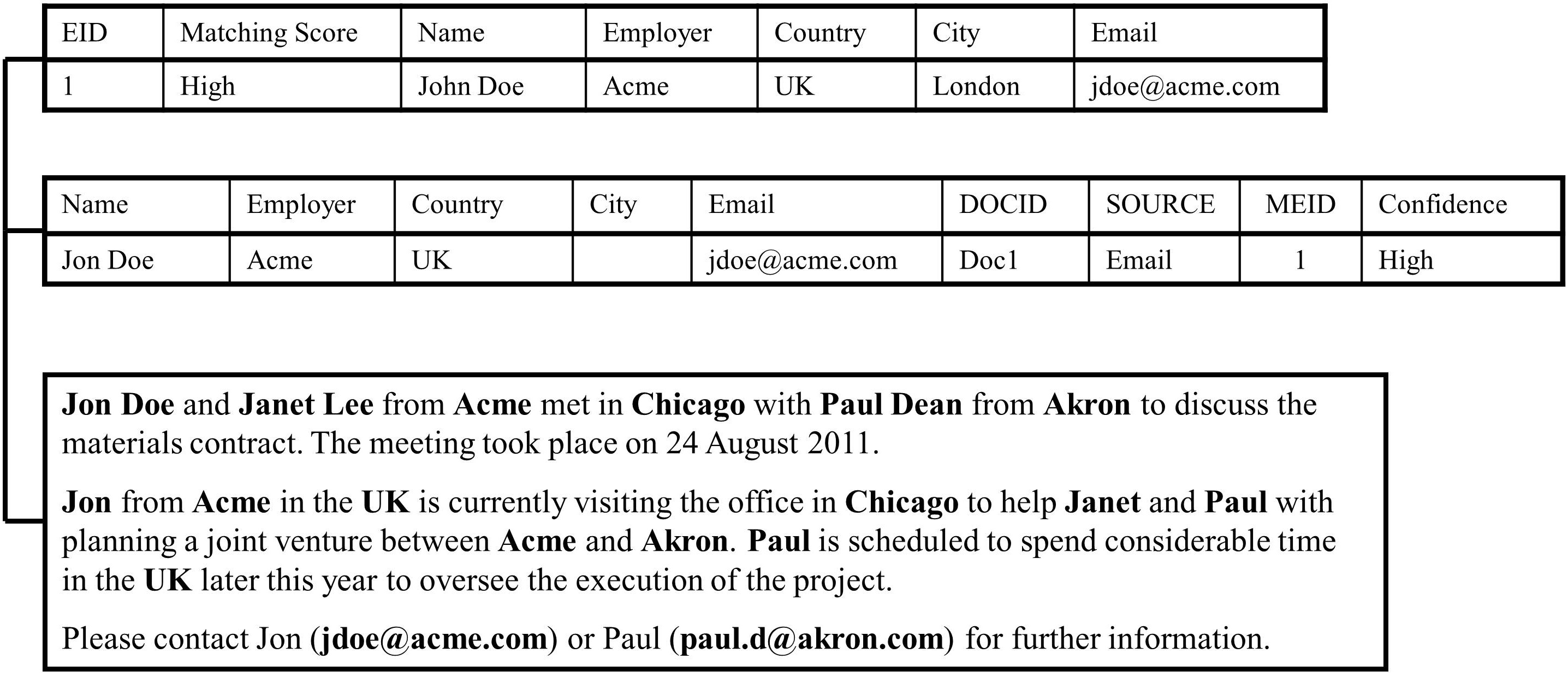
Figure 8.8: Linking matching entities and emails in IBM InfoSphere Master Data Management.
By incorporating unstructured information into MDM, the master data team can build a better view of the overall customer relationship. This can also be extremely helpful during personnel changes. In the preceding example, Jon Doe and Janet Lee from Acme were working with Paul Dean from Akron. If Paul Dean left Akron before completion of the contract, how would the new representative, Lucas Alexander, get an updated status on all the work that was scheduled with Acme?
By enriching MDM with unstructured text such as this email, Lucas would be able to open the profile of Acme. He would see that his contacts were John Doe and Jane Lee. Looking further, he would see that there was an email related to the profile. Upon reading the text, he would know that he should follow up with Acme and let them know he was looking forward to continuing the work they began with Paul. This would help cement the relationship between Acme and Akron, increase Akron’s retention of Acme as a client, and reduce the risk of critical leads being lost due to employee turnover or the failure of Paul Dean to enter the opportunity in the lead-tracking system.
There are a number of other business applications to support the integration of text analytics with MDM. For example, bank risk departments can use the integration of text analytics with MDM to update counterparty risk. The risk department at a bank can use unstructured financial information such as U.S. Securities and Exchange Commission (SEC) filings to learn that the ownership of a company has changed or that a large customer is also a director in three other companies. The risk department can use this information to update the customer hierarchies in MDM to establish an up-to-date picture of the overall exposure to a customer.

Sunil Soares is the founder and managing partner of Information Asset, LLC, a consulting firm that specializes in data governance. Prior to this role, Sunil was director of information governance at IBM, where he worked with clients across six continents and multiple industries. Before joining IBM, Sunil consulted with major financial institutions at the Financial Services Strategy Consulting Practice of Booz Allen & Hamilton in New York. Sunil lives in New Jersey and holds an MBA in finance and marketing from the University of Chicago Booth School of Business.
MC Press books written by Sunil Soares available now on the MC Press Bookstore.
 |
Big Data Governance Discover not only the “why” but the “how” of governing big data. List Price $59.95 Now On Sale
|
|
 |
Data Governance Tools See why tools are a critical component of a data governance program, and learn how to evaluate them. List Price $59.95 Now On Sale
|
|
 |
IBM InfoSphere: A Platform for Big Data Governance and Process Data Governance Get to know the big data support across the IBM InfoSphere portfolio. List Price $16.95 Now On Sale
|
|
 |
Selling Information Governance to the Business Learn best practices for implementing an information governance program across a variety of specific industries. List Price $49.95 Now On Sale
|
|
 |
The Chief Data Officer Handbook for Data Governance Implement a program that will manage data as an asset while delivering the trusted data your business initiatives require. Now On Sale
|
|
 |
The IBM Data Governance Unified Process Learn the 14 steps to implementing data governance based on IBM products, services, and best practices. Now On Sale
|



 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online