















Ah $@#%! I knew I had made a mistake as soon as I hit the Enter key. Within seconds, I had that sick feeling in the pit of my stomach—you know, the one that comes when you realize that your plans for the day have suddenly changed.
Let me start from the beginning. We had an application server that was quickly running out of disk space. The vendor had spec'ed a mirrored 36 GB drive to house the Linux OS and the JBoss instance and to store the PDF images of the bills we generate. (The database is hosted on another machine dedicated to that purpose.) It became apparent that, at the rate we were creating PDFs, we only had a month or so left before the lack of space became critical. The plan was to upgrade the SCSI controller contained in the server (an IBM xSeries) to one that was RAID 5–capable, add four 72 GB drives in a RAID 5 configuration, and then incorporate the new space into the existing LVM—nothing I hadn't done before. I estimated that the whole project would be completed in one hour, two at the most.
The hardware installation was trouble-free, and I was just configuring the drives when I hit the SNAFU: I neglected to import my existing drive configuration. Thus, when I made that fateful keystroke, my existing mirror information was wiped clean and, apparently, so was my existing data. And thus, my epithet.
I know what you're thinking. "So all you had to do was restore your system from the backup. What's the big deal?" That was my thought, too. Unfortunately, the vendor-supplied system backup software doesn't work. Oh, the output from it gives the impression that it does. But when you actually attempt a restore to bare metal, things don't go as advertised. No matter what I tried (up to and including reverting back to the original hardware configuration), I could not make the recovery CD do anything other than repeatedly reboot. At this point, it became clear that a reinstallation was in the offing, so I reconfigured the system's hardware to the way I wanted it (minus one of the original drives, which I placed on the shelf for data recovery) and rebooted the SuSE Linux installation CD. While the system started coming up, I placed an SOS call to the vendor's emergency team to notify them that they'd have to jump into action once I had the basic system recovered.
By the time everyone came in on Monday morning, the application server was back online and no one was any wiser, except that the historical data represented by the PDFs had yet to be restored. The task of restoring them from the daily backup was mine, and I had decided that it was one that could be postponed until my arrival at the office on Monday. I'm sure that the astute reader has already guessed this punchline: The daily backup (run from the database server) doesn't save the PDF data, even though it's supposed to.
Another 911 call to the vendor secured copies of the errant data, with the exception of the PDFs created during the first two months we had been using that software. While the lost data wasn't particularly valuable, losing any data just rubs me the wrong way. I was determined to find a way to recover it. While the techs at IBM gave me no hope of recovery, I figured that because the data was on mirrored drives, it was contained in its entirety on the trashed disk. I surmised that the RAID controller would have probably overwritten only the metadata and would, most likely, have left the rest of the drive intact. As it turns out, I was correct.
Enter the Open-Source Options
Many people feel that data recovery is nothing more than voodoo requiring tons of specialized knowledge and equipment. While that can be the case with hard drives that are inoperable due to hardware failure, logical damage to the data on the drive is often recoverable if you have the tools to do so. There are certainly commercial tools available for this task, and they've been around almost as long as the PC has. (Remember Norton Disk Doctor?) I like to use open-source tools whenever possible, and as it happens, many fine tools are available, as you'll soon see.
I came into the office during the weekend so that I could take the server offline and use it for my recovery efforts. Once the box was shut down, I inserted the original drive into an unused slot and booted the machine using a Knoppix CD. This gives me complete access to the drives, without the normal host operating system getting in the way.
Once I was at the Knoppix desktop, I checked and, as expected, the mirrored pair containing the reconstituted system appeared as /dev/sda, and the newly inserted drive showed up as /dev/sdb. To give myself a fallback position, I used the dd command to create an image of the drive and saved it to another server on my network. This would allow me to restore the drive (by using dd again, this time in reverse) should I need to revert back to its current but useless state.
Having gotten this far, my next step was to install a truly outstanding program with an innocuous name: TestDisk. As its Web site says, TestDisk is "primarily designed to help recover lost partitions and/or make non-booting disks bootable again when these symptoms are caused by faulty software, [or by] certain types of viruses or human error (such as accidentally deleting your Partition Table)." The installation of this software is trivial. I simply downloaded the tarball containing a static compilation (so I wouldn't have to worry about missing libraries), untarred it into root's home directory (which is actually on a RAM disk, since Knoppix runs from CD), and ran it by issuing the command ./testdisk_static.
Once the program loaded, I was greeted with the screen shown in Figure 1.
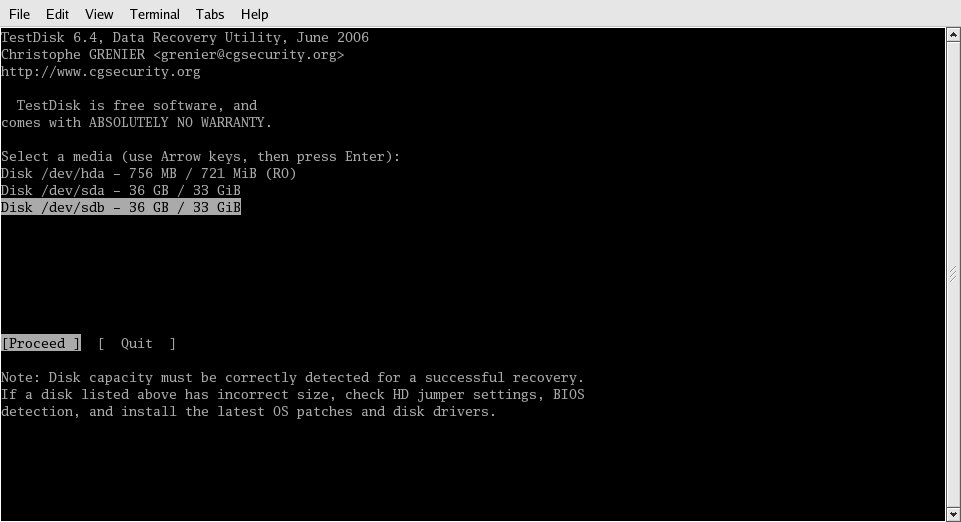
Figure 1: This TestDisk screen capture shows the mirrored drive, the corrupted drive, and the CD-ROM from which Knoppix was booted. (Click images to enlarge.)
I selected the second drive (/dev/sda) and continued, which brought me to the screen shown in Figure 2.
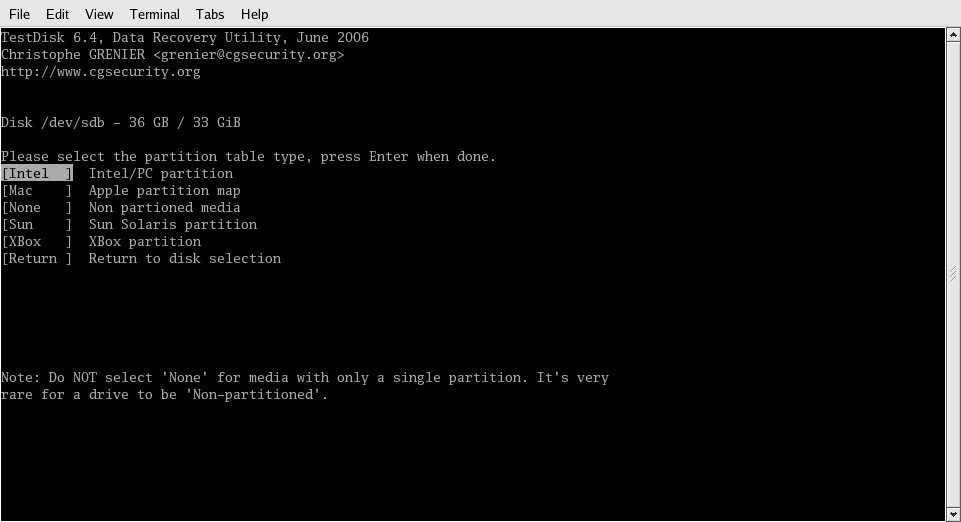
Figure 2: The program is capable of identifying different types of partition tables. In this case, my system is an IBM xSeries.
Since this box is an IBM xSeries, I chose "Intel" and moved on. The next screen, shown in Figure 3, is where I chose to allow the program to look over the drive, searching for a recognizable partition table.
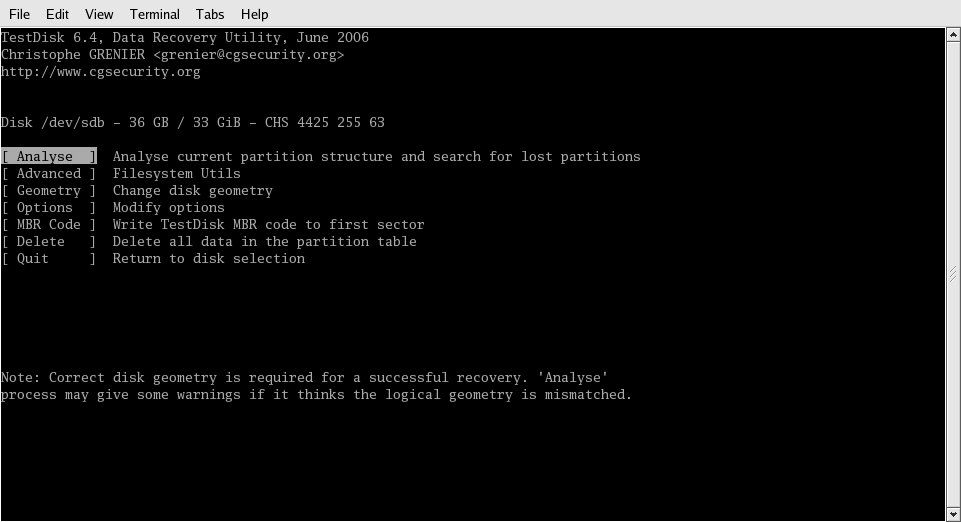
Figure 3: The Analyse task searches the disk for a recognizable partition table.
Right off the bat, it told me that the partition table wasn't where it should be, as shown in Figure 4. This is to be expected as I assume that the RAID controller had written its metadata where you'd normally find the partition table, so the partition table would be "farther in" on the disk.
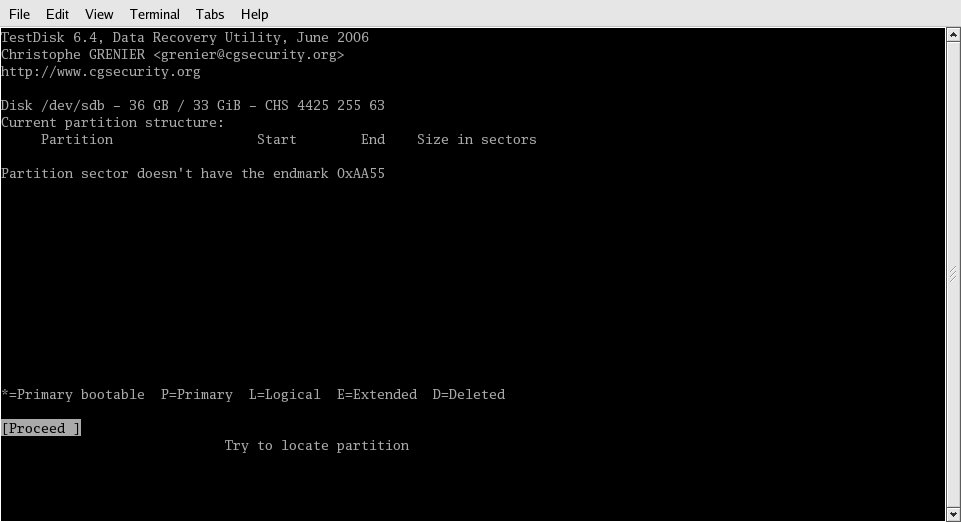
Figure 4: It's nice that the program tells me what I already knew: The partition table isn't where it belongs.
Within one minute of selecting Continue, I was looking at my partition table, as shown in Figure 5. Eureka! The only thing I had to do was press Enter and then tell the program to write the table.
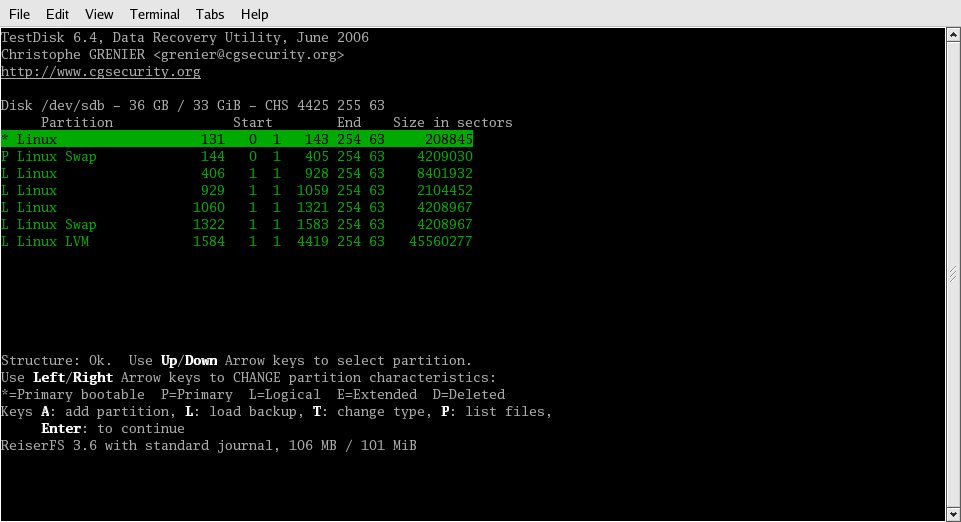
Figure 5: A quick scan of the disk found a valid partition table, which was displayed here. If the partition table is trashed completely, TestDisk will scan the entire disk, looking for signatures indicating the beginning and end of partitions.
Once I was out of TestDisk, I used fdisk to list the partition table, which was as expected, and then did a gratuitous "write" to exit fdisk, thus causing the system to re-read the partition table, saving me the time required for a reboot. Once the disk's partition table was restored, it was a trivial matter to import the LVM partition, mount the partitions (read-only), and copy the data to the mirrored drives.
I shut the system down one last time, removed the superfluous drive and Knoppix CD, and powered things back up. When the system was operational, I entered the application and verified that the data was indeed back where it belonged, which brought a smile to my face. Let me make one thing clear, though: I got lucky. Had these disks been RAID 5 instead of mirrored, my chance of actually recovering the data would have been nearly zero, since the data would have been spread over all of the disks in the RAID volume. The loss of the metadata would have been catastrophic.
Fool Me Once
I already know what most of you are thinking: that I shouldn't have had to go through these gyrations. Had I actually tested the backup and restore procedures, I would have known there was a problem before finding out the hard way. You're absolutely right; I should have done the testing. My mistake was accepting the word of a vendor that things would work as advertised (a vendor that has this package in hundreds of locations, by the way). Given that I didn't have spare hardware on which to test the package didn't help me much, either. Believe me: Had this particular piece of software been hosted on my i5 or any of my Linux servers, I could tell you with certainty that I could have restored the data.
As the saying goes, "Fool me once, shame on you. Fool me twice, shame on me." Up to that fiasco, the vendor was loathe to provide much information concerning what was going on under the covers of its product. After the failure, I spent a great deal of "quality time" on the phone with the vendor. I had the technical representative tell me exactly what gets backed up by their scripts and exactly what those files represented. So now, while I still use the vendor's tools (which have since gone through many revisions and bug fixes) to do regular backups, I also do my own, using my choice of tools. If the vendor's backup fails again, I have my backup to that backup, from which I am confident I can restore.
How about you? Any systems around your place that you aren't confident are properly backed up? If not, may I humbly suggest that you do some research on the data recovery tools available in the open-source world. You'll eventually need one.
Barry L. Kline is a consultant and has been developing software on various DEC and IBM midrange platforms for over 23 years. Barry discovered Linux back in the days when it was necessary to download diskette images and source code from the Internet. Since then, he has installed Linux on hundreds of machines, where it functions as servers and workstations in iSeries and Windows networks. He co-authored the book Understanding Linux Web Hosting with Don Denoncourt. Barry can be reached at


 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online