















Publish or consume application data and logic from anywhere, to anywhere, on any platform using REST service APIs.
For quite a while, we've all heard the buzz surrounding a "service-oriented architecture" (SOA). The promise of SOA is to allow applications to communicate with one another in real time, whether on a private network or across the world, using the platform-independent, standard HTTP protocol. If you're writing ILE subprocedures and SQL routines available for access by other applications (even on other OS platforms), then pay attention because building a service-oriented architecture is the next logical step in your code evolution. This article will provide an introduction to the concepts surrounding SOA development and its implementation using REpresentational State Transfer (REST) services.
Evolution of Computer System Communication
Before examining SOA, let's take look a look at a non-technical, three-step history of system communication. The terms and eras described here are arbitrary.
Caveman Era: Tools like EDI and FTP are used to exchange information between systems (only data is exposed).
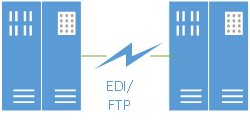
Figure 1: Initial communication between systems used technologies like FTP and EDI.
Though old, EDI and FTP are still useful, yet there is quite a bit of technical work required to implement either (although FTP is fairly easy for trivial text files). EDI has lasted in the industry for so long because it has the benefit of adhering to published standards. Even so, the data transfer is not "real time"; it can be difficult to detect and act on errors during the process, and it takes a developer with specialized knowledge to extract data received via EDI and place it into an application (or vice versa).
File-transfer utilities are also included in this era. Does anyone remember when System i Access was named PC Support and its file-transfer program was the best utility ever?
Client/Server Era: Specialized remote procedure calls (RPC) and SQL interfaces enable the real-time exchange of data and logic between a server such as the IBM i and various clients such as PCs/servers (usually limited to systems within a private network). I include traditional data-driven Internet or intranet applications in this era.
The drawbacks with client/server programming are that specialized developer knowledge is usually required for programming on the client, the server, and the middleware component. Further, deploying apps to multiple devices and platforms can be a challenge if a particular middleware component is unavailable.
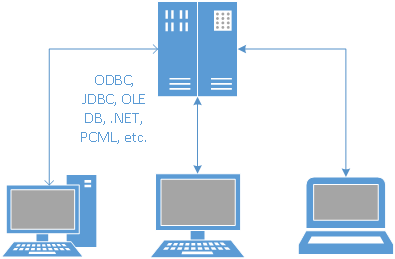
Figure 2: In the client/server era, communication from a business application is done using specialty middleware tools.
Client/server and web application coding involves writing pieces of code that can service other applications. An example would be writing an RPG subprocedure that can accept a sales order request. This subprocedure can be invoked by a 5250 program, a web UI, or a business partner's system to create a sales order, and it should be "stateless." By stateless, I mean the code unit accepts all of the information it needs via parameters to accomplish its task; it should not need to know anything about the state of the calling application.
This hypothetical "Create Sales Order" subprocedure can depend on other subprocedures, but thanks to its stateless design, theoretically it can be called from anywhere whether on the IBM i or another platform altogether as long as all necessary parameters are passed. All IBM i shops should be writing modular, stateless routines (functions/subprocedures) and, where appropriate, making the various entry points into the code public.
These public, stateless routines can be accessed by other ILE programs (even in a different application), by SQL calls (via external function/procedure wrappers), and by Java (by JDBC and PCML, etc.). The SQL and Java options open up your IBM i data and logic to other platforms and languages. Whether you label them as such, these are your own APIs.
The middleware components have a drawback because they generally service a specific server and client set (although some are multi-platform) and are cumbered with deployment issues. Another negative for middleware technologies is they're limited to the local network. It's considered a bad security practice to open the appropriate ports to allow outside users or partners to connect to your DB2 for i database using ODBC or JDBC!
I could have a cool stateless stored procedure that would allow a business partner to query data or create data on my local system, but alas, it would be a headache to find a safe way to allow them access to it (assuming they had the developer talent to call it from their own system). Likewise, if a vendor has a UNIX system running Oracle hosting a stored procedure of interest to my company, they're probably not going to give me access to their stored procedure! So publishing data to partner systems and consuming data from partner systems are problematic in the client/server environment.
Personally, as a developer with a "systems integration" interest, I've spent a good deal of time in this arena, working with various middleware technologies. It's been a pain in the neck to become good using one technology such as the Windows OLE DB provider only to encounter a non-Windows development project that required the same kind of programming. Learning new middleware often requires a boatload of hours, mistakes, and the frustration of coming up to speed with a new technology.
With the plethora of relatively newer platforms (iOS, Android, etc.) and devices (smartphones, tablets, embedded), there isn't a good way to learn how to develop for each of these. Worse, some technologies just go by the wayside! Did anyone besides me try their hand at IBM's Visual RPG to create client/server apps?! Kudos to IBM during this era for making sure developers have many middleware options to choose from.
Era of Enlightenment: A service-oriented architecture expands on the client/server paradigm. The code units are ideally written as stateless and intended to service any potential caller.
However, instead of doing something like publishing RPG code unit as an SQL external routine, the RPG code will now be published to an HTTP server. Rather than access the RPG code through SQL (or Java, etc.) using some kind of database middleware such as ODBC or JDBC, in the SOA world, the RPG code will be accessed via HTTP requests. This is good because just about every modern device and programming language can make an HTTP request.
Additionally, rather than passing parameters as a database-specific data type and getting tabular result sets intended for a specific middleware provider, with SOA all data exchanges are done using standard formats such as XML or JavaScript Object Notation (JSON). This is not as efficient as using middleware components, but interoperability is a plus and the performance cost is mitigated by new hardware.
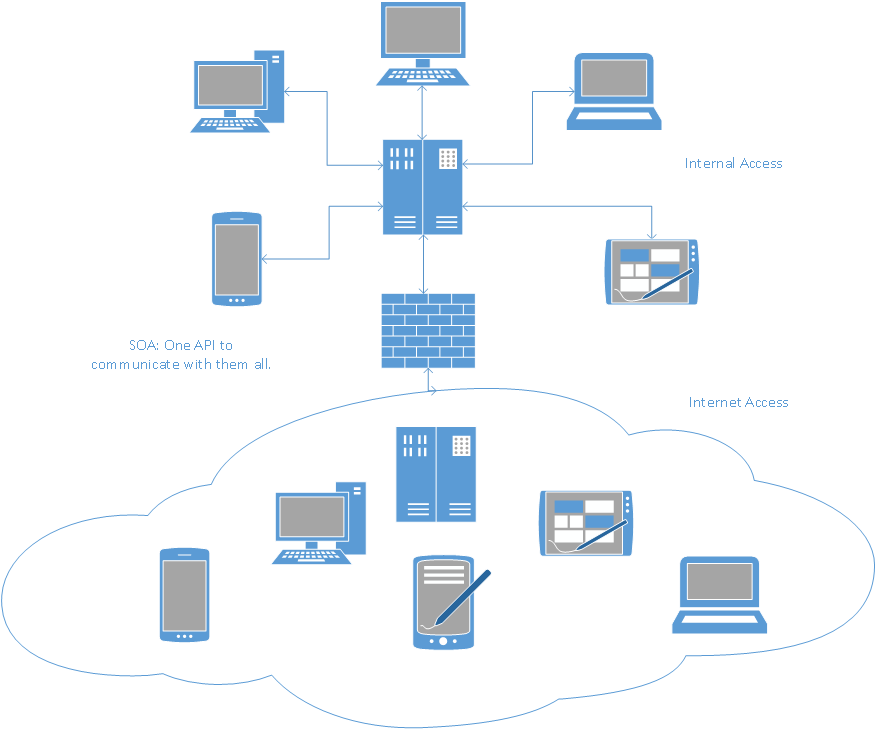
Figure 3: Using SOA allows your business to publish APIs or consume APIs using current Internet standards. These APIs are accessible by most modern platforms, languages, and devices.
In principle, the SOA era is similar to what you should already be doing when you write your code. However, the goal is moving away from specific middleware tools to a "universal" toolset. SOA retains the benefits of client/server real-time data and logic access, provides further benefits by making the API calls platform- and language-agnostic, and opens up the possibility of accessibility to business partners via the internet.
Should I Build My SOA With SOAP or REST Services?
There are two well-established standards for implementing SOA: Simple Object Access Protocol (SOAP)-based web services and REpresentational State Transfer (REST) services. These two options have quite complex definitions, and the interested reader can review the references. Simply put, these two can be considered the "end points" or wrappers used to access your code, similar to how an external SQL function definition allows SQL to access RPG code. These wrappers act as an interface to accept an HTTP request from a caller (via a URL that maps to a specific code unit such as a subprocedure), invoke your code with any parameters, gather the code's output, and return the output as an HTTP response.
So what distinguishes the two options? Early on, SOAP-based web services were popular, thanks in part to Microsoft's Visual Studio wizards that did most of the plumbing code and masked many of the coding complexities. Other development platforms were not so fortunate, with clumsy or complex tools required to publish or consume a SOAP-based web service. On the IBM i, the Integrated Web Services for IBM i tool allows ILE code to be published as a SOAP web service. The Web Services Client for ILE allows ILE code to consume a SOAP web service. In my limited experience (early on with these tools), I found they worked well when dealing with simple parameter data types, but passing complex object parameters became a headache. SOAP's complexities paved the way for REST to gain popularity.
SOAP web services also require XML wrappers for the requests and responses. Because everything is XML-based, a service that returns binary data, such as a zip file or an image, has to convert the binary to hex first and place it in the XML response. Thereafter, when the XML is received by the caller, it has to convert the hex to binary. Binary-based results equal extra overhead for XML. With REST, this is simplified as other data formats can be used.
REST services accept HTTP requests made to a URL with a specific HTTP verb (GET, PUT, DELETE, POST), invoke the defined business logic, and return the result as a standard HTTP response (typically formatted as JSON or XML). Further, REST APIs specifically are conducive for data-oriented CRUD (create, read, update, and delete) operations. Finally, since parameters for a REST call are often placed in the URL, it's easy to test REST services with your web browser by pasting in a particular URL that includes parameters.
Many modern web applications rely heavily on REST services because they can return results to the caller in the JSON format. JSON's claimed benefits are that it's "lighter" than XML in terms of size and composing/parsing overhead, and that a JSON string can be instantiated as a JavaScript object that the application can use immediately. Please note JSON's superiority to XML with regard to size and speed has been disputed.
While discussing all the differences between the two approaches would be time-consuming (hey, that's what the Internet is for), REST is generally the simpler of the two service implementations and the method I would recommend for the most common scenarios to publish an API.
Requisite Developer Skills
There are two aspects of REST services development: publishing a service (server side) and consuming a service (client side). To understand how to publish and consume REST services, you'll want to be up to speed on the basics of the HTTP protocol, XML, and JSON. You will probably want to brush up on how to work with these data items in your language of choice, such as Java, RPG, C#, PHP, etc. When publishing a service, depending on your environment, you may also need a web server such as Microsoft IIS or Apache to host it.
When publishing a REST service, you have to decide what data format the service will return (usually JSON or XML). Some service providers offer multiple formats and let the client dynamically choose the preferred response format. If the data returned from your service is likely to be consumed by a web client for display in a UI, then JSON is probably the best choice. XML is usually a good second choice. Other formats such as a PDF, a PNG image, or a Microsoft Office Open XML doc (.xlsx, .docx, etc.) can be returned as well.
For the IBM i faithful, to publish or consume a REST web service using an ILE language (like C, RPG, or COBOL), Scott Klement's open source HTTP API offering is a popular option. For consuming services, starting with IBM i 7.1, DB2 for i has new HTTP functions that make it pretty easy to make HTTP requests and receive responses using embedded or dynamic SQL. These tools aid with HTTP communication. Help with formatting data is discussed next.
When publishing data from a REST service in JSON format from an ILE program, you have a few options. Scott Klement published an IBM i port of YAJL (Yet Another JSON Library), which will allow an ILE program to easily create JSON responses to web service-based requests. As a second option, IBM Systems Magazine published a utility by David Andruchuk that will export a DB2 table to a JSON file and store the results on the IFS. When consuming a JSON-based web service in ILE, YAJL will do the trick.
When publishing XML, there are several tools available to help ILE programmers, such as:
- DB2 for i XML publishing functions (requires IBM i 7.1 or later)
- XML Toolkit for iSeries (5733XT1)
- CGIDEV2 product (this is an HTML tool, but it has been used by many for composing XML documents)
When consuming XML data from a REST service using an ILE client, some of the options include:
- DB2 for i XML support including the XMLTable table function (requires IBM i 7.1)
- Native RPG support for decomposing XML documents
- XML Toolkit for iSeries (5733XT1)
This list doesn't exhaust the options for IBM i developers as PHP, Java, etc. can also be used. These languages have additional options that are easy to investigate on the Internet.
If you're like me, you may be thinking something like "My .NET managed provider already opens my IBM i data and logic to the world." But alas, the .NET provider is stuck within Windows. SOA is about using standards to aid with consistent, platform-independent development.
Synchronous vs. Asynchronous Calls
Another aspect of client-side REST programming involves calling APIs asynchronously. This is typically done with browser-based, client-side user interface programming. When calling an API synchronously, the caller simply waits "on hold" for the API to finish and to return the results. When making an asynchronous call to a REST API, the caller submits a request but doesn't wait around for the result. Instead, a "listener" is used to monitor the server for when the final result is ready. When the API has completed, the response is given to the caller and an event-handler in the caller's code processes the results. An error-handler can also be set up if the expected response never comes (aka a timeout condition) or if an error occurs on the server.
As you can imagine, making HTTP calls in a background thread, monitoring for the server response (or lack thereof), and calling the appropriate code segment when the result is ready is no small coding task. Thankfully, for client-side web development, there are many JavaScript libraries that greatly simplify this complex task, such as Node.js and JQuery (Microsoft uses JQuery in ASP.NET).
Security
When publishing a service—whether on your private network, to business partners, or on the Internet at large—security is yet another skill that developers or administrators need to consider. Security is a broad topic and its implementation will depend on the infrastructure used to host the API (Microsoft IIS web server, Apache web server, a standalone Java program, etc.).
Therefore, you'll have to do your own research, but for many business needs, the following two items should be a minimum part of any security implementation:
- Implement basic authentication—Basic authentication requires the caller to specify a valid user name and password before access to the API is allowed. Unfortunately, basic authentication credentials are sent from the client to the HTTP server in base 64 encoded clear text, so they can be easily discovered and decoded (the next point indicates how to overcome this limitation).
- Implement SSL/TLS—To prevent prying eyes from gleaning valuable secrets from your network traffic, require Secure Sockets Layer (now known as Transport Layer Security) communication. This will require the client to call your API using HTTPS instead of HTTP and will encrypt communication between the caller and server.
Publishing a REST API using a combination of SSL/TLS and basic authentication will protect your API from many threats. For the record, SOAP offers more options in the security realm than REST, and special security requirements may make SOAP a better choice than REST.
What Companies and Products Offer REST APIs?
Many companies offer REST APIs, allowing your code to interact with their data and services. Intuit's QuickBooks Online, a myriad of Google services, Microsoft OneDrive (formerly Sky Drive), EBay, Amazon, and Yahoo are just a few.
Microsoft SharePoint, Microsoft CRM, IBM WebSphere, and many other products offer REST APIs as a means of accessing application data and services. This is important as it makes integrating with these applications much easier. Fading are the days when vendors try to hand you proprietary middleware tools to work with their products.
Even though SOA APIs are built on "standards," they can at times be cumbersome to work with (such as interpreting a complex HTTP response). Many vendors have created wrappers in a variety of languages (JavaScript, Java, PHP, C#, VB.NET, etc.) as wrappers around the REST calls to ease working with their APIs.
A REST API Example
After all this gabbing, it'd be useful to see how a raw REST API is invoked. Here are a few examples taken from the QuickBooks Online API portion of Intuit's developer network (knowledge of an HTTP request is helpful).
This first example uses a POST verb to create a payment transaction for a specific customer, date, amount, etc.
|
URI: https://quickbooks.api.intuit.com/v3/company/companyID/Payment Method: POST Content-Type: application/xml Accept: application/xml Request body: <Payment xmlns="http://schema.intuit.com/finance/v3"> |
Any language that can build XML and talk using HTTP (Java, RPG, C#, etc.) can build the above request. The XML response looks like this, returning all information about the newly created payment:
|
<IntuitResponse xmlns="http://schema.intuit.com/finance/v3" time="2013-07-11T17:54:46.078-07:00"> |
In this next example, a GET verb is used to query a specific payment.
|
URI: https://quickbooks.api.intuit.com/v3/v3/company/companyID/query?query=selectStmt Method: GET Content-Type: text/plain Accept: application/xml or application/json Request body: XML: select * from Payment where id = '8748' |
The XML response is shown here:
|
<IntuitResponse xmlns="http://schema.intuit.com/finance/v3" time="2013-07-11T17:54:47.580-07:00"> |
Intuit does offer libraries in several languages, such as Java, so that you can work with an object in code and skip past the bothersome XML parsing. One other thing to note is that this set of APIs can return data in XML or JSON format. For more examples, the Quickbooks Online API reference can be found here.
Many REST APIs can be invoked without an HTTP request body with all relevant parameters passed in the URL. These APIs are particularly easy to use because they can usually work in a web browser with parameters passed in the URL and the XML response shown in the UI.
Conclusion
In essence, publishing your data or logic using a REST API is similar to what you're already doing when you allow your ILE service programs or DB2 database code to be accessed via JDBC, ODBC, OLE DB, the .NET managed provider, PCML, etc. Using REST gives the potential to unveil your logic and data to a new world of devices and platforms for both internal and external users and business partner systems.
The SOA world moves ahead as ever more applications use services (REST in particular) to make their data and logic available to others. In fact, you may soon find yourself building applications by assembling pieces from different systems together. While this opens up the potential for application failure based on another vendor's system, it holds the promise of taking advantage of specialized logic and data (such as calculating shipping rates, tracking weather, finding an optimal driving route, etc.) that the average developer doesn't have the expertise or time to implement.
References

 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online