
















A trigger is a predefined event that runs automatically whenever a specified action is performed on a table. In the “smart reality” and “Internet of Things” times that we live in, it’s the database equivalent of the shower turning itself on (and at the right temperature) when you enter the bathtub. The fun part is that you can be very specific about what happens when that predefined event occurs.
Before getting into the details, let me just add that there are two types of triggers: those you might already be familiar with: high-level programming language (HLL) triggers, written in RPG or one of the other languages the IBM i supports natively, and SQL triggers. I’ll stick to the same guidelines followed thus far and will discuss only SQL triggers. It’s true that most of the stuff I’ll talk about can also be done in an RPG program. Sometimes, it might even be better to adapt an existing HLL program and link it to a trigger via the ADDPFTRG (Add Physical File Trigger) CL command, especially if complex code is involved. However, for certain tasks, an SQL-only approach is preferable for reasons of clarity and future maintenance.
Having said that, let’s dissect the definition with which this section started, starting with the “specified action” part.
Editor's Note: This article is excerpted from chapter 9 of SQL for IBM i: A Database Modernization Guide, by Rafael Victória-Pereira.
What Triggers a Trigger?
Going back to my bathtub analogy, imagine that you enter your bathtub with your clothes on. Turning on the shower automagically doesn’t sound like a great idea now, right? Well, maybe just turning on the faucet, to start the water running, sounds better. Triggers, unlike tripwires, can be created to react only to specified actions. Because triggers are associated with tables, those actions are the I/O operations that somehow change the table: INSERT, UPDATE, and DELETE operations.
I know, you’re thinking that reading the table’s records also changes its state, because it can cause locks, and so on. However, it’s not possible to create a trigger that goes off whenever records are read from a table, only for the three other I/O operations I mentioned. But there’s more to it: you can choose when the trigger goes off: before or after the action occurs. As you’ll see later in this chapter, this distinction is of paramount importance for some of the tasks you can rig a trigger to perform. Just a side note: instead of “goes off” or “is triggered,” I personally prefer the expression “is activated” to refer to the moment the metaphorical tripwire is pulled. So, from this point on, I’ll refer to activation to describe the moment the trigger is put to use.
In a nutshell, here’s what you need to keep in mind about triggers: they execute a piece of code (SQL or HLL) when the records of the table they’re associated with are changed (via an INSERT, UPDATE, or DELETE operation). The execution of that piece of code can happen before or after the action that triggered it occurs.
Why Use Triggers?
Triggers are great at making stuff happen without human intervention, because they are activated whenever the action or actions with which they’re rigged happens. Yes, you read it right: it’s possible to associate a trigger with more than one action. You can define a trigger that executes a piece of code upon insertion or deletion of a record, for instance, no matter where these actions are initiated. And that’s the interesting part: triggers are linked to the table, not the operation’s source, which means that they’ll be activated no matter where the operation comes from: an RPG program, a remote ODBC call, or a DFU (remember that tool?) operation performed by you.
This “operation omniscience” makes triggers the perfect tool in a data-centric approach, because they allow you to “move” code from RPG applications to the database! Think of the possibilities: just to mention a possible scenario, you can simply rig a trigger that calls a complex (and typically old) RPG monolith instead of detailing the business logic to be rewritten in a “modern” language, in order to perform the same validations, with very little effort. You can reuse, instead of rewriting, your code by placing triggers in the appropriate tables, with the appropriate conditions, and call existing programs. Note that I do not advise perpetuating the use of old RPG monoliths. It’s always better to rewrite them in smaller and more manageable chunks of code—but that’s a discussion for another book.
You can also easily create audit files, validate data, and do much more—all at database level, thus making your database more “intelligent.” Do you see where I’m going with this? These are just some of the reasons you should use triggers: as part of a data-centric approach, they provide an amazing level of reusability and automation.
SQL Triggers’ Advantages
As I mentioned earlier, there are two types of triggers: SQL and external. You’re probably familiar with the external (created using RPG or other IBM i-compatible HLL) triggers.
What you are probably not aware of is that SQL triggers offer several advantages over external triggers:
- SQL’s simpler and more powerful language makes trigger development easier and faster.
- SQL triggers’ activation is more precise: you can, for instance, activate the trigger only if a certain column has a certain value. This type of operation is not possible with external triggers.
- It’s much easier to write an SQL trigger to handle operations that modify more than one row in the target table.
- With SQL, you can create INSTEAD OF triggers (which I’ll discuss later in this chapter).
- SQL’s syntax makes it easier to write and configure one trigger to process several events.
After all this discussion, you’re probably itching to start coding. Well, I’ll get to that in a moment. First, I’ll explain how to create triggers using SQL and provide some examples to get you warmed up.
SQL Trigger Mechanics
What you’ve read so far hinted at (actually, it almost gave away) most of the mechanics of an SQL trigger. Let’s take a moment to see how the different pieces fit in the instruction’s syntax:

It seems like a lot but isn’t that complicated, especially because I already mentioned (albeit without naming) all these different pieces. Let me go over them, one by one:
- The trigger-name must be unique within the schema to which it belongs. It’s restricted by the same rule previously discussed in regard to SQL routines, so I won’t go into details about them here.
- The trigger-activation-time refers to the moment in which the trigger is activated: BEFORE or AFTER the event that activated the trigger occurs (there’s also another option for this parameter, named INSTEAD OF, which I’ll leave for later).
- The trigger-event indicates with which operation(s) the trigger is associated. I mentioned the I/O operations before, but let’s look at the syntax in more You can choose between INSERT, UPDATE, and DELETE. It’s also possible to use any combination of these three commands, separating the options with the OR keyword. For instance, a trigger that is activated by an insertion or deletion of a record will have INSERT or DELETE on the trigger-event part of its definition. By the way, the ON target-table refers to the table over which you’re setting up the trigger, because unlike SPs and UDFs, triggers don’t exist in a vacuum: they are always linked to a target table.
- The trigger-granularity is one of most interesting parts of the trigger’s definition, as it allows you to decide how the trigger will be activated. You can choose between FOR EACH STATEMENT and FOR EACH ROW. This controls whether the triggered action is executed for each row or for each statement that has been changed in some For instance, an UPDATE operation could modify three rows, and the trigger would be activated either once or three times depending on the value defined here.
- The next item in the list, trigger-mode, also plays a part in the execution, but in a different It controls the moment in which the trigger’s code is executed. If you choose MODE DB2ROW, then the trigger will be activated (in other words, its code will be executed) after each row operation. But if you choose MODE DB2SQL, then the database engine will wait until all the row operations are processed to execute all the respective trigger’s actions.
- Finally, triggered-action is a placeholder for the actual SQL/PSM code that will run whenever the trigger is activated. It can be either a simple INSERT statement (as you’ll see in one of the examples, later in this chapter), or something much more complex (such as a full-fledged SQL/PSM routine for cross-table data validation, for instance).
Keep in mind that not all these pieces are mandatory, as you’ll see in a moment.
A Simple Trigger Example
To help you consolidate the syntax explanation, let’s analyze a simple scenario: someone wants to keep track of how many students exist in our UMADB students table, so they asked us to create a simple counters table that stores the total number of students, teachers, and classes that exist at any moment. “It will look good on our website,” they said. Note that this is a hypothetical and oversimplified scenario that ignores the fact that these three pieces of information can be obtained directly from the respective tables.
Instead of going to the RPG, Web, or any of the many simple programs or full-fledged applications that use the Students table, we’ll tackle the problem at its target, rather than its source(s): We’re going to create a trigger that is totally oblivious to where the student- creation request (read: the insert operation in the students table) came from, and that’s it! No need to change the existing HLL (IBM i “native” or otherwise) applications. The most pressing issue here is that you need to have an exclusive lock over the table to add the trigger. There are other potential issues, which I’ll address in greater depth later, but that’s the most important one—for now. So, let’s say we wait until a time no one is using the Students table, and we create our trigger with the following command:

Let’s dissect this statement (and please pay attention, because you’re about to get some practice based on this), bit by bit. The first line (CREATE OR REPLACE TRIGGER UMADB_CHP5.Trg_log_student_creation) is quite obvious and follows the same principles of the previously presented SQL routines. It serves to identify the type and name of the SQL routine. In this case, I’m creating (or replacing, if it already exists) a trigger named Trg_log_student_creation in schema UMADB_CHP5. The second line (AFTER INSERT ON UMADB_CHP5.TBL_Students) tells us that this trigger is activated after each insert operation on table TBL_Students. So far, this follows the high-level syntax model I presented earlier.
However, I mentioned that not all the “pieces” of that model were mandatory. The next couple of lines (UPDATE UMADB_CHP5.Tbl_Counters and SET STUDENT_COUNTER = STUDENT_COUNTER + 1;) serve as an example of that statement, as they don’t refer to the trigger’s granularity or mode. In fact, these lines are this trigger’s action: an update to another table.
But let’s go back to the trigger’s granularity and mode; even though it’s not specified, the trigger granularity option is “still there”—its default, implicit value is the FOR EACH STATEMENT. Similarly, the trigger mode is also absent, so its default value—MODE DB2SQL—will be used, in order to keep compatibility with other DB2 implementations. Although this is a very simple trigger, I could have written the triggered action (my UPDATE statement) as a BEGIN/END block of code, because triggers are SQL routines, and SQL routines can be composed of multiple BEGIN/END blocks. I could rewrite my trigger to include the BEGIN/END lines, like this:

Testing Your First Trigger
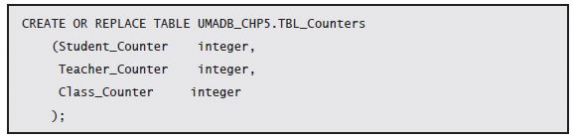
It’s now time to test this trigger. Naturally, I’ll use SQL statements for that. You can either type them or use the ones provided in the downloadable source code for this chapter. The Counters table doesn’t exist in the current UMADB schema, so you’ll need to create it, using the following statement:
The next step is to add a new row, zeroing the counters:

Just to check whether everything is in perfect order, let’s run a SELECT statement over the Counters table:

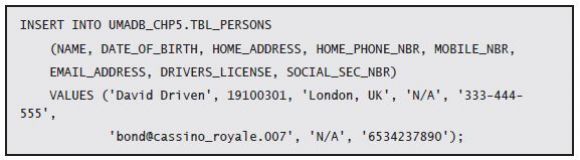
All the pieces are set, so let’s test the trigger. This particular trigger is activated by INSERT operations in the Students table, so let’s create a new student. That task is, for now, a two-step process. First, I need to create a new person record:
And then, using the person ID generated by the database, I can finally insert a new row in the Students table:

Note that 17 is the person ID generated by the database when I inserted the record; yours will certainly be a different number, so run a quick SELECT over the Persons table, find out which is the correct number, and replace the 17 with that number. If you were expecting some sort of confirmation that the trigger was activated (or even that it exists) when the INSERT statement’s execution finished, you might be disappointed, because you won’t see it. To check whether the trigger was actually activated (and worked as expected), you need to check the Counters table again:

There you’ll see the proof you were looking for: the student count’s value was changed from 0 to 1, so the trigger was executed, and it performed admirably the action it was designed to perform.
Time for Some Practice
Now that you know a little more about SQL triggers and their syntax, it’s time for some hands-on work. The idea is for you to create similar triggers to feed the other two columns of the Counters table—Teacher_Counter and Class_Counter—whenever new records are added to their corresponding tables (TBL_Teachers and TBL_Class_Definition, respectively). Just reread the section that dissects the trigger that keeps the Student_ Counter updated, and you should do fine. If you need a little push (or get totally lost), you’ll find the statement for creating the Counters table and the solutions (separate files for the two triggers) for this little practice session in this chapter’s downloadable source code. If you want to check whether these two triggers work, just adapt and run the test steps mentioned in the previous section to each particular situation.
Next time: Exploring More Complex Trigger Scenarios.

Rafael Victória-Pereira has more than 20 years of IBM i experience as a programmer, analyst, and manager. Over that period, he has been an active voice in the IBM i community, encouraging and helping programmers transition to ILE and free-format RPG. Rafael has written more than 100 technical articles about topics ranging from interfaces (the topic for his first book, Flexible Input, Dazzling Output with IBM i) to modern RPG and SQL in his popular RPG Academy and SQL 101 series on mcpressonline.com and in his books Evolve Your RPG Coding and SQL for IBM i: A Database Modernization Guide. Rafael writes in an easy-to-read, practical style that is highly popular with his audience of IBM technology professionals.
Rafael is the Deputy IT Director - Infrastructures and Services at the Luis Simões Group in Portugal. His areas of expertise include programming in the IBM i native languages (RPG, CL, and DB2 SQL) and in "modern" programming languages, such as Java, C#, and Python, as well as project management and consultancy.
MC Press books written by Rafael Victória-Pereira available now on the MC Press Bookstore.
 |
Evolve Your RPG Coding: Move from OPM to ILE...and Beyond Transition to modern RPG programming with this step-by-step guide through ILE and free-format RPG, SQL, and modernization techniques. List Price $79.95 Now On Sale
|
|
 |
Flexible Input, Dazzling Output with IBM i Uncover easier, more flexible ways to get data into your system, plus some methods for exporting and presenting the vital business data it contains. Now On Sale
|
|
 |
SQL for IBM i: A Database Modernization Guide Learn how to use SQL’s capabilities to modernize and enhance your IBM i database. Now On Sale
|



 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online