
















Today’s topic is tricky, especially for people unfamiliar with the concept of indexes. Many of us use them implicitly when we create logical files, but do you really know what an index is and how to create one?
In the previous TechTip, I explained how views are similar and, at the same time, different from logical files (LFs): views are easier to define and change, but there’s something that LFs can have that views can’t: keys.
This brings us to the INDEX SQL instruction. If you’re not familiar with it, here’s what Wikipedia says about it:
A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index data structure. Indexes are used to quickly locate data without having to search every row in a database table every time a database table is accessed. Indexes can be created using one or more columns of a database table, providing the basis for both rapid random lookups and efficient access of ordered records.
An index is a copy of selected columns of data from a table, called a database key or simply key, that can be searched very efficiently that also includes a low-level disk block address or direct link to the complete row of data it was copied from. Some databases extend the power of indexing by letting developers create indexes on functions or expressions. For example, an index could be created on upper(last_name), which would only store the upper-case versions of the last_name field in the index. Another option sometimes supported is the use of partial indices, where index entries are created only for those records that satisfy some conditional expression. A further aspect of flexibility is to permit indexing on user-defined functions, as well as expressions formed from an assortment of built-in functions.
In short, indexes are shortcuts to the data. But because an image is worth a thousand words, let me explain how an index works with two of them.
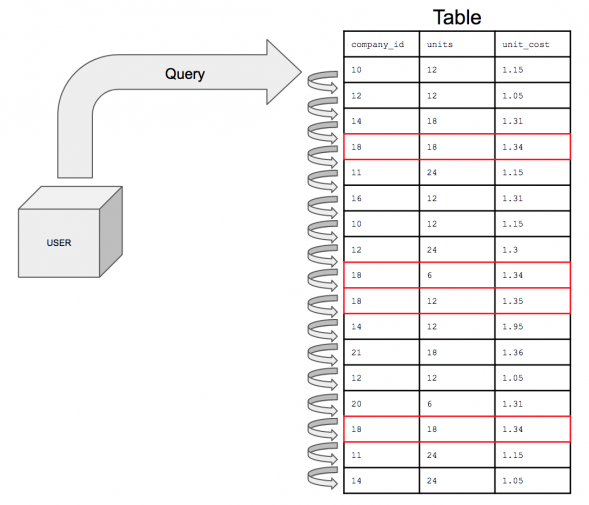
Figure 1: Query over an un-indexed table
Figure 1 shows what happens when a query is executed over an un-indexed table: Each row in the table is read, its column values are compared with the ones mentioned in the query, and the matching ones are selected. It’s slow, because the whole table will have to be scanned. Now let’s have a look at the same query and its behavior if there’s a usable index (that is, an index with the “right” key).
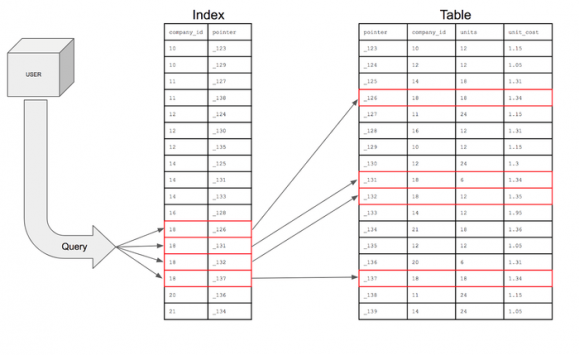
Figure 2: Query over an indexed table
Figure 2 depicts what happens if there is an index that can be used by the query. Instead of a full table scan, the query goes to the index first, which points only to the necessary rows on the table, thus dramatically decreasing the query execution time.
Now that you’re up to speed on what an index is, let’s continue.
Because your views can’t implement the ORDER BY clause, you need to create a view and an index to replace a keyed logical file, but an index is a more efficient access path than a logical file (LF). LFs can handle 8 Kb memory pages, while an index handles, by default, 64 Kb memory pages. However, you can specify the memory page’s size when you create the index; its range can vary between the LF’s 8 Kb and 512 Kb. This means that indexes can have a better performance than LFs by far.
Note that indexes with larger logical page sizes are typically more efficient when scanned during query processing. Indexes with smaller logical page sizes are typically more efficient for simple index probes and individual key lookups. In practice, a larger memory page size represents a significant performance gain because more data is handled at a time, reducing the disk access frequency. The INDEX syntax is very simple:
CREATE INDEX <schema or library name>.<index sql name>
FOR SYSTEM NAME <index system name>
ON <schema or library name>.<table name>
(key expression)
There are four types of indexes:
- The “regular” index doesn’t require any additional keyword and creates an access path like the ones you know from the keyed-not-unique LFs.
- The “unique” index prevents the table from containing two or more rows with the same value of the index key. When UNIQUE is used, all null values for a column are considered equal. For example, if the key is a single column that can contain null values, that column can contain only one null value. The constraint is enforced when rows of the table are updated or new rows are inserted. The constraint is also checked during the execution of the CREATE INDEX statement. If the table already contains rows with duplicate key values, the index is not created.
- The “unique where not null” index is similar to the unique index but doesn’t consider all null values as equal. In other words, multiple rows containing a null value in a key column are allowed.
- The “encoded vector index” is used by the database manager to improve the performance of queries. However, it cannot be used to ensure the ordering of rows. There’s a whole chapter on this topic in the Database Performance and Query Optimization manual.
For instance, a “regular” index over the inventory master table defined with this table’s primary key would look like this:
CREATE INDEX MYSCHEMA.IDX_INVENTORY_MASTER_MAIN
FOR SYSTEM NAME I_INVMST01
ON MYSCHEMA.INVMST
(WAREHOUSE_ID ASC, SHELF_ID ASC, ITEM_ID ASC)
The last line of the statement contains the key expression—the names of the columns that compose the key and the ASC reserved word, meaning that the data is sorted in ascending order. If I wanted any of the columns to be sorted in descending order, I’d replace ASC with DESC.
Indexes can also define unique key constraints. Here’s an example of a unique index, enforcing a unique key over the warehouse master table:
CREATE UNIQUE INDEX MYSCHEMA.IDX_WAREHOUSE_MASTER_MAIN
FOR SYSTEM NAME I_WHMST01
ON MYSCHEMA.WHMST
(WAREHOUSE_ID ASC)
I’ll revisit these DDL topics in a later TechTip and discuss how you can convert your physical and logical files to their SQL counterparts. In the next one, I’ll continue the DDL discussion with an extremely useful but not-very-well-known instruction: ALIAS

Rafael Victória-Pereira has more than 20 years of IBM i experience as a programmer, analyst, and manager. Over that period, he has been an active voice in the IBM i community, encouraging and helping programmers transition to ILE and free-format RPG. Rafael has written more than 100 technical articles about topics ranging from interfaces (the topic for his first book, Flexible Input, Dazzling Output with IBM i) to modern RPG and SQL in his popular RPG Academy and SQL 101 series on mcpressonline.com and in his books Evolve Your RPG Coding and SQL for IBM i: A Database Modernization Guide. Rafael writes in an easy-to-read, practical style that is highly popular with his audience of IBM technology professionals.
Rafael is the Deputy IT Director - Infrastructures and Services at the Luis Simões Group in Portugal. His areas of expertise include programming in the IBM i native languages (RPG, CL, and DB2 SQL) and in "modern" programming languages, such as Java, C#, and Python, as well as project management and consultancy.
MC Press books written by Rafael Victória-Pereira available now on the MC Press Bookstore.
 |
Evolve Your RPG Coding: Move from OPM to ILE...and Beyond Transition to modern RPG programming with this step-by-step guide through ILE and free-format RPG, SQL, and modernization techniques. List Price $79.95 Now On Sale
|
|
 |
Flexible Input, Dazzling Output with IBM i Uncover easier, more flexible ways to get data into your system, plus some methods for exporting and presenting the vital business data it contains. Now On Sale
|
|
 |
SQL for IBM i: A Database Modernization Guide Learn how to use SQL’s capabilities to modernize and enhance your IBM i database. Now On Sale
|



 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online