
















Now that you know how to create simple triggers from our previous article, Introducing Database Triggers, let’s move on to more complex scenarios.
As you probably realized by now, a trigger can be used for many different tasks. Updating a certain value each time a record is somehow created or changed is just a very small part of what you can do with a trigger. Let me take you on an exploration of a few scenarios where a properly crafted trigger can be a simple solution to a complex problem. Instead of vague and insipid scenarios, we’ll return to our fictional UMADB database and its environment to provide something you can actually relate to. So, just to quickly get you back “into character”: we work for ACME University’s IT department, and we’ve been overhauling the database in order to open it to all the non-IBM i applications that need its data.
Using Triggers for Data Validation
We were called to the Dean’s office (again). It seems that our good job with the database redesign and stored procedures got us on the Dean’s speed-dial list. This time, the big boss is worried about data tampering and asked us to devise low-cost, low-maintenance solutions for this type of problem. The most urgent matter is related to money, naturally. More specifically, it concerns the teachers’ salary data: he wants us to find a cheap way to avoid a teacher’s salary being increased more than 10 percent in one update.
Now that we’ve helped “open up” the database to non-native applications, there are multiple points of entry from which the teacher’s data can be changed. This means that an application-level change is not an option: it would be costly and time-consuming to implement, and would basically mean repeating the same business rule in multiple environments and programming languages. Our solution is to perform a database-level change, by creating a data-validity check whenever a teacher’s record is changed.
However, there are many possible changes (theoretically, as many as the table’s columns), so this has to be very precise. The other factor that we must take into account is that this check has to prevent the change, not find and report it after it happens. You probably already saw where this is going: we’re going to set up a trigger that’s activated before an update that changes a teacher’s salary occurs. If, and only if, the new salary is more than 10 percent higher than the original one, we’ll block the change and send an error message back to the origin of the update. This sounds tricky, but it’s actually quite simple. Let’s analyze the code, bit by bit, starting with the usual trigger name and even “sections”:

Nothing new here: I’m just naming my trigger and saying that it will be activated before an update occurs in the Teachers table. Now I need to compare the old and new values of the salary. How can I do that, if we’re talking about the same record? Well, actually the trigger’s “entry parameters” are the before and after images of the records. In other words, I can access the record before its data is changed by the UPDATE statement.
However, I must tell the database engine that I need both the before and after images, and I need to define a prefix for them, because (obviously) the column names are the same in both. The following three lines of code are all that’s required to do it:

The first line tells the database engine that I’ll be using both “old” and “new” records or, in other words, the original and updated records. The second line is there to guarantee that the trigger is called after each row, because the update can affect multiple rows at once. Finally, the third row tells the database engine to restrict the activation of this trigger to updates that change the salary column, because that’s all I’m interested in right now. All that’s left to do is check whether the change is allowed—that is, whether the new salary is within the accepted limits. That task is performed in the trigger action section:

In this block of code, I’m checking whether the update (new) salary is higher than the limit: 110 percent of the original (old) salary. If it is, I’m stopping the process and sending an error message back to the caller program. If you don’t recall how SIGNAL works, reread Chapter 6 to brush up on error handling and signaling. The SET MESSAGE_ TEXT sends a human-readable message that can be accessed by the caller directly (SQLCA) or via the GET DIAGNOSTICS statement, depending on the caller program’s environment.
Testing the Teacher Salary Update Check Trigger
All that’s left to do now is to test the trigger. This one doesn’t require the creation of additional tables; all you need is a properly engineered UPDATE statement. First, let’s find an appropriate teacher ID, by running a SELECT over the entire table:

Let’s pick one existing ID—I chose 6, but it all depends on the data—and run the following UPDATE statement:

This will try to increase the salary of the teacher whose ID is equal to 6 by 20 percent. As expected, the update will fail. If you run this statement in Run SQL Scripts or a similar tool, you should receive output similar to this:

With 11 lines of code, we solved a problem that would have taken several programmers quite a bit of time to solve, in their respective applications. Note that this is a very simple example of data validation, but it illustrates the foundational principles: set up the trigger to run in the appropriate event (by using the proper BEFORE/AFTER INSERT/UPDATE/DELETE combination in the trigger event section), pinpoint your target (using the WHEN clause), run the check (with one or more IF statements), and act upon it (by writing the necessary code in the trigger action section, which will either block the I/O operation entirely, as I did here, or adjust the incorrect value, for instance).
Using Triggers for Auditing
Even though this crisis was averted, somehow we find ourselves in the Dean’s office (again). This time, the Dean wants us to set up history files for auditing purposes, because someone has been tampering with the grades, and no one knows how, when, who, or from where. It seems the existing auditing mechanisms, which were built in the application’s RPG III days and were never properly overhauled, are not working as they should, so we got called in to save the day.
Yes, it’s another trigger scenario, a bit different from the previous one. In short, we need to build something that logs all activity in the grades table (that’s the TBL_Class_ Enrollment_Per_Year table, in case you don’t remember), except READ operations. We’re going to log all INSERT and DELETE operations, as well as all UPDATE operations that change the GRADE column.
I’ll create a new table, based on the Class Enrollment per Year, with a few additional columns: EVENT, which I’ll fill with the name of the operation that activated the trigger; USER (you guessed it) to contain the name of the user who initiated the operation; and TIMESTAMP to answer the “when” question. Instead of a complete CREATE TABLE statement, with all the names of the original table columns plus these three new columns, I’ll use a shortcut and create the table by copying the Class Enrollment per Year table’s structure and adding the new columns. Yes, that’s possible and actually quite simple:

The CREATE TABLE AS statement allows you to create a new table on the fly, based on a SELECT statement. It’s particularly useful in situations such as this one, because I don’t have to type (or copy/paste) the complete list of columns of the original table. Finally, the WITH NO DATA line is important, because I just want the table definition, not its data. If you run a simple SELECT statement on the new table, you’ll be able to confirm that it has all the necessary columns. Now I can proceed to the trigger creation.
You could write an RPG program and associate it with a trigger using the ADDPFTRG (Add Physical File Trigger) CL command, but I’ll take the SQL route and use a native trigger. Just as I did before, I’ll divide the trigger’s code into chunks and analyze each of them separately. Let’s start with the trigger name, activation, and event sections:

This looks similar to the previous trigger, but it also has some noteworthy differences. If you look carefully, you’ll note that this trigger is activated after an INSERT, DELETE, or UPDATE of a record in our grades table. However, there’s something special about the update: I only want the trigger to be activated if the update operation changes the GRADE column; that’s why I included that OF GRADE bit after the UPDATE. This OF <some column> part only makes sense after an update, because when you insert or delete a record, you’re affecting the whole record, not just one particular column or set of columns.
The next part of the statement is also similar to the previous trigger:

I changed the old and new record prefixes for clarity’s sake, but it’s basically the same as before. The difference is what I’m going to do with the records, as you’ll see in the trigger action section. Remember, the objective is to keep track of all INSERT, UPDATE, or DELETE operations performed on the table where the grades are stored. It might be useful to know which row of the log file is linked to which operation. That’s why the log file includes a column named EVENT. Native triggers offer us a simple way to determine which event activated the trigger. Because I want to store that information in my audit table, I’ll use a variable to temporarily store the operation name:

This variable will receive different values, depending on the event that activated the trigger. Let’s see this in the code, by analyzing the piece of code that’s executed when an INSERT occurs:

It’s that first line, IF INSERTING THEN, that does the trick. There are three such predicates: INSERTING, UPDATING, and DELETING. These keywords contain TRUE if the corresponding operation activated the trigger. When used with an IF statement, they allow you to do different things depending on the operation, instead of creating multiple triggers. In this case, I want to log when a new record is inserted, who did it, and when. Note that I’m using the “new” record for this, because there’s no “old” record, in this case.
The code for the UPDATE and DELETE is similar, as you’ll see in a minute, but for those scenarios I decided to log only the “old” record (that is, the image of the record before the UPDATE or DELETE operation was performed):

Remember that because of that UPDATE OF GRADE bit of code, I’m only logging updates that change the GRADE column. This is another way to implement granularity, quite different from the WHEN (UPDATED.SALARY <> ORIGINAL.SALARY) used in the previous trigger. If you read carefully the documentation about triggers in the DB2 for i Reference manual, you’ll see that there’s usually more than one way to solve a problem.
Testing the Trigger
Let’s test this trigger! I’ll assume that you have some data in the Class Enrollment per Year table, and I’ll start by updating a grade:

You might need to adjust this statement, so that the TBL_CLASSES_PER_YEARCLASS_PER_ YEAR_ID matches an ID that exists in your version of the data. Now let’s run an INSERT statement:
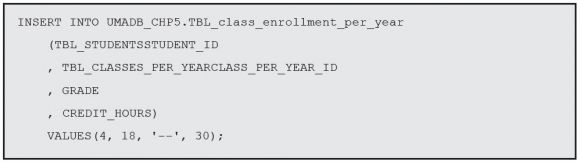
Again, you might need to adjust the IDs for this to work on your system. Finally, let’s delete the line we just inserted:

If everything went as expected, you should have three lines in your log table. Run the following statement to check:
![]()
You should find an exact image of the record you updated, as well as two copies of the record you inserted: one for the INSERT and another for the DELETE operations. The first record is the image before the update, because I’m using the OLDREC prefix in the INSERT statement that writes data to the log table.
There you have it: a different trigger, slightly more complicated than the previous one, which you can easily adapt to create an audit/log/history table to any existing table in your database!

Rafael Victória-Pereira has more than 20 years of IBM i experience as a programmer, analyst, and manager. Over that period, he has been an active voice in the IBM i community, encouraging and helping programmers transition to ILE and free-format RPG. Rafael has written more than 100 technical articles about topics ranging from interfaces (the topic for his first book, Flexible Input, Dazzling Output with IBM i) to modern RPG and SQL in his popular RPG Academy and SQL 101 series on mcpressonline.com and in his books Evolve Your RPG Coding and SQL for IBM i: A Database Modernization Guide. Rafael writes in an easy-to-read, practical style that is highly popular with his audience of IBM technology professionals.
Rafael is the Deputy IT Director - Infrastructures and Services at the Luis Simões Group in Portugal. His areas of expertise include programming in the IBM i native languages (RPG, CL, and DB2 SQL) and in "modern" programming languages, such as Java, C#, and Python, as well as project management and consultancy.
MC Press books written by Rafael Victória-Pereira available now on the MC Press Bookstore.
 |
Evolve Your RPG Coding: Move from OPM to ILE...and Beyond Transition to modern RPG programming with this step-by-step guide through ILE and free-format RPG, SQL, and modernization techniques. List Price $79.95 Now On Sale
|
|
 |
Flexible Input, Dazzling Output with IBM i Uncover easier, more flexible ways to get data into your system, plus some methods for exporting and presenting the vital business data it contains. Now On Sale
|
|
 |
SQL for IBM i: A Database Modernization Guide Learn how to use SQL’s capabilities to modernize and enhance your IBM i database. Now On Sale
|



 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online